阿里发布Qwen3小幅更新版本,放弃混合思考模式,发布全新的2个版本Qwen3-235B-A22B-2507模型,1/5的参数,性能直逼Kimi K2,推理模式版本评测结果接近o3
阿里今天开源了Qwen3-235B-A22B模型的一个小幅更新版本,命名为 Qwen3-235B-A22B-Thinking-2507。这是一个 仅支持推理过程 的模型。而在四天前,阿里还发布了 Qwen3-235B-A22B-Instruct-2507,它 不支持推理过程。
这两个模型将原先Qwen3中的“混合架构模式”(即一个模型同时支持thinking和non-thinking)拆分为两个独立版本。据官方说明,这是基于社区反馈所做出的调整。

Qwen3-235B-A22B-2507 的主要更新
本次更新主要带来了以下变化:
- 原先在4月底引入的“混合架构模式”被弃用。阿里认为,一个模型通过参数切换支持推理与非推理两种模式的效果不理想,因此本次直接拆分为两个模型,各自专注于一种模式,且无法通过参数切换。
- Instruct-2507 在通用能力方面有显著提升,涵盖指令遵从、逻辑推理、文本理解、数学、科学、编码和工具使用等多个方面。
- Thinking-2507 在逻辑推理、数学、编程方面达到了当前开源模型的 SOTA 水准。
- 非推理版本在创意写作、风格模仿、情感支持等主观任务中,输出更贴近人类偏好,文本质量更高。
- 多语言能力也有所增强,尤其是在某些长尾语种的知识覆盖方面。
- 上下文长度提升至 256K(原为 128K)。
架构方面保持不变,仍为 MoE 结构,拥有 128 个专家,每次推理激活其中的 8 个。
Instruct-2507 不支持推理模式,也不会生成空的 <think></think> 标签。如需推理能力,请使用 Thinking-2507。
非推理模式模型(Instruct-2507)评测结果优于 Kimi K2
根据官方评测,相较于 4 月 28 日版本,非推理版本的能力显著增强,已全面超越 Kimi K2。
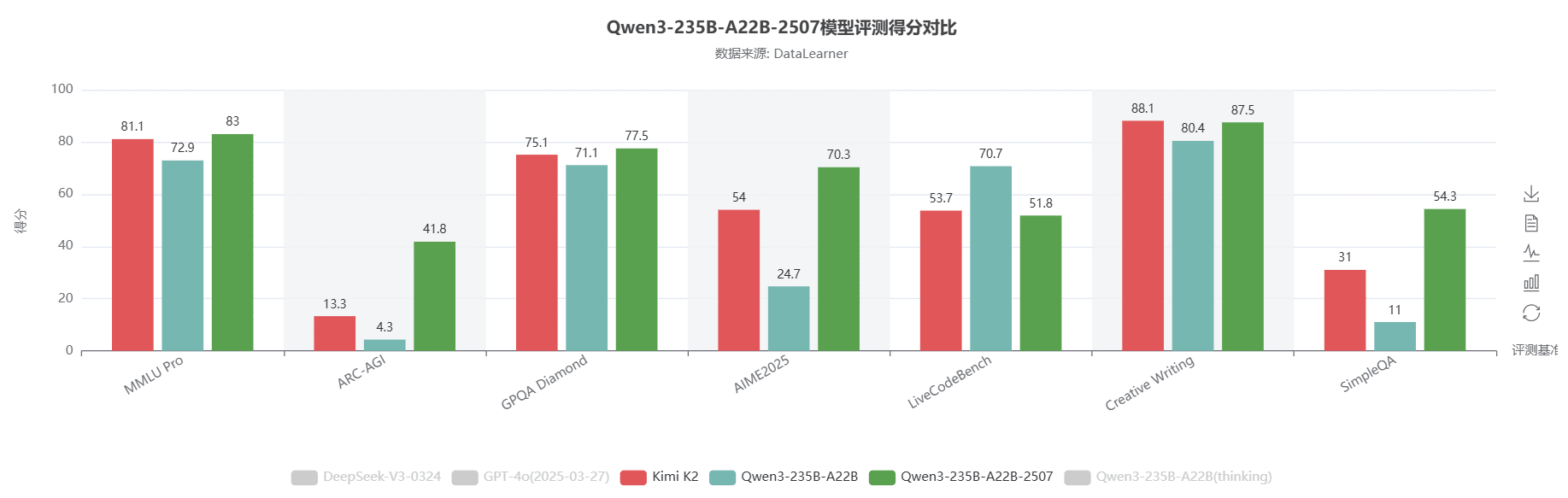
图中绿色为本次更新版本,红色为 Kimi K2,青色为 4 月版本。
需要注意的是:ARC-AGI-1 的评分为 41.8(阿里公布),但 ARC Prize 官方表示无法复现,实测结果为 11.6。目前官方尚未回应此问题。
推理模式模型(Thinking-2507)评测结果接近 OpenAI o3
推理版本 Qwen3-235B-A22B-Thinking-2507 在多个方面有明显提升,尤其是在数学推理与编程能力方面表现出色。
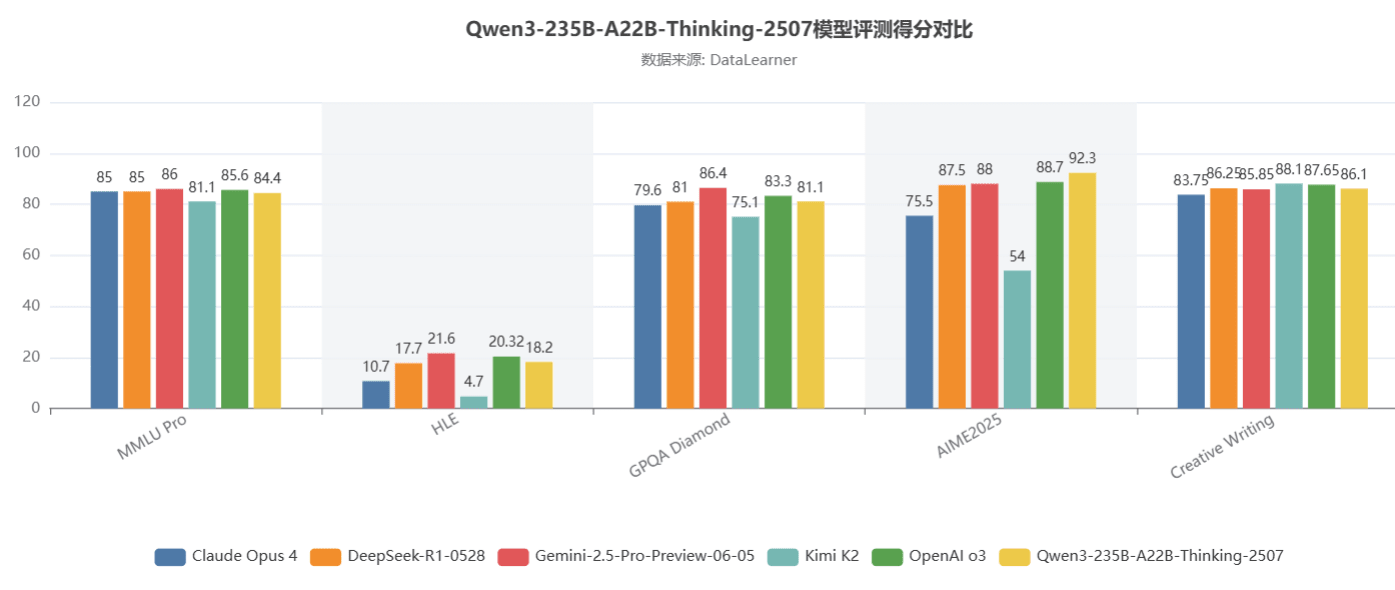
模型在 GPQA Diamond、Creative Writing v3 等任务中表现与顶级模型接近。
在 HLE(人类最后难题)这种高难度任务中得分 18.2,优于 Claude Opus 和 Kimi K2,并略胜 DeepSeek R1。
在 AIME 2025 数学推理评测中获得了 92.3 分,超过 Gemini 2.5 Pro 与 OpenAI o3:
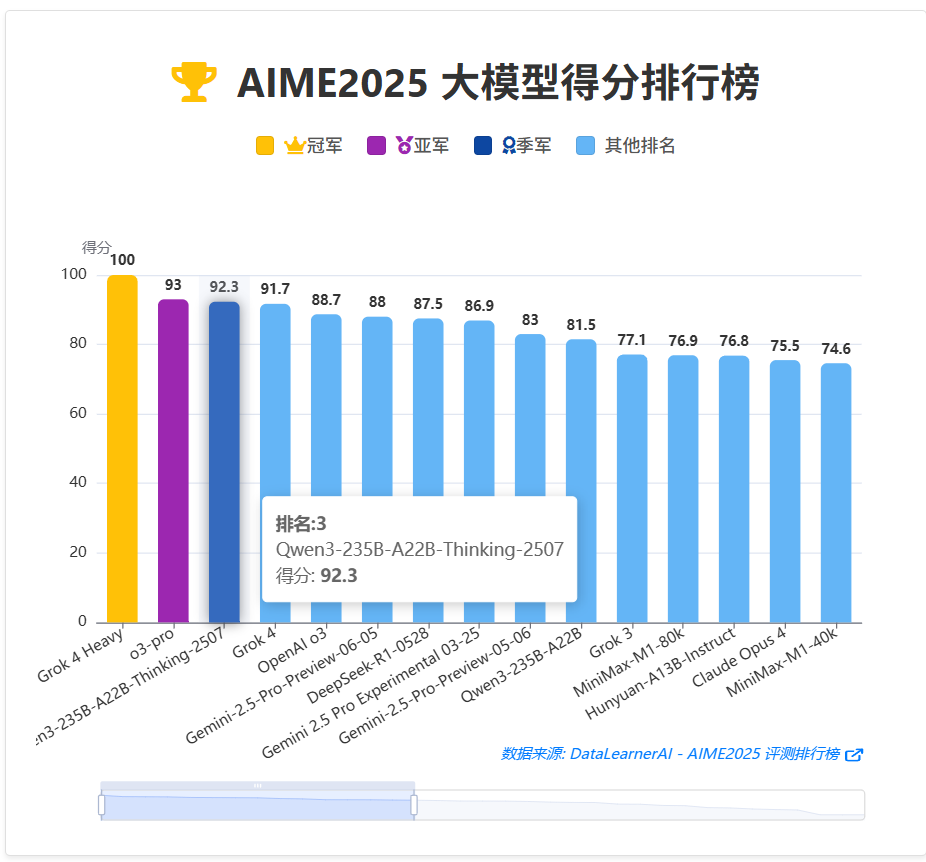
目前在 DataLearnerAI 榜单中排名第 3,略低于 OpenAI o3 Pro。
阿里为什么要拆分推理与非推理模式?
此次更新最大的变化是:不再混合支持推理与非推理模式,而是明确拆分为两个模型版本。
这一变化并非临时决定。在 Qwen3-235B-A22B 发布后,虽然其代码生成和推理能力强,但社区反馈在数学与创意写作等方面存在不足,有时关闭推理反而效果更好。
此外,尽管推理时仅激活 22B 参数,但模型总规模仍为 235B,对显存要求不低。部分用户反馈某些任务表现仅与 Qwen3-14B(稠密结构)相当。
因此,这次更新不仅是一个版本迭代,更可能是技术路线的调整,评测结果也印证了其成效。
不过,Qwen 系列的评测数据污染与部分指标无法复现的问题仍令人关注。
Qwen3-235B-A22B-2507 的开源信息与社区反馈
无论如何,阿里已正式开源了 Qwen3-235B-A22B-2507 更新版本。尽管仍有争议,但多数用户实际使用体验良好。
目前已有多个对比评测显示 Qwen3 与 Kimi K2 在不同方向上各有优势,表现都非常强劲。
两者都是开源模型,开发者可自由使用与部署。
相关开源链接如下:
