能否用85000美元从头开始训练一个打败ChatGPT的模型,并在浏览器中运行?
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。
Django的共同创始人Simon Wilison最近发表了一篇博客,介绍最近的模型进展使得大家可以用8.5万美元从头训练一个类似ChatGPT的模型。其实最主要的办法就是你训练一个70亿参数规模的LLaMA(MetaAI开源的),然后用斯坦福大学的Alpaca的指令微调方法做微调(成本不到100美元)。这两个加在一起,效果与ChatGPT比较还是不错的。而且这两个模型都是开源的,并且有详细的细节介绍。
注意,本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!
本文根据Simon Willison的博客介绍了如何得出这样一个8.5万美元成本的ChatGPT模型:
一、大语言模型的训练成本
构建具有类似GPT-3能力的大型语言模型需要数百万美元的费用,这归因于运行需要昂贵GPU服务器的高昂成本。无论是租用还是购买这些设备,都需要支付巨额能源成本。
一个例子是BLOOM大型语言模型(模型卡地址:https://www.datalearner.com/ai/pretrained-models/bloom ),在法国得到了法国政府的支持,其费用被估计为200万-500万美元,花费了近4个月的时间进行训练,并因大部分电力来自核反应堆而夸耀其低碳足迹!
最近的一些新的模型技术发展让大家发现可以用8.5万美元来训练一个和ChatGPT差不多的模型。因为类似ChatGPT模型本身就是一个大的生成模型GPT-3加上指令微调变成ChatGPT,因此,只需要找到一个低成本的大模型训练方法加一个低成本指令微调方法即可。也就是本文介绍的2个开源方法:LLaMA+Alpaca
二、低成本的关键方法来源一:LLaMA
GPT-3的发布已经涉及很少的训练细节和成本了,而GPT-4模型则是没有公布任何细节,所以大家很难从中找到训练成本降低且保证质量的方法。但是MetaAI开源大模型LLaMA(模型信息:https://www.datalearner.com/ai/pretrained-models/LLaMA )提供了一个完全公开可用的方式,这使得我们可以考虑从中优化。在LLaMA的论文中,MetaAI公布了他们的训练成本:
我们估计我们使用了2048个A100-80GB GPU,持续约5个月的时间来开发我们的模型。
这个成本可以这样算,一般来说,公有云中A100的使用费用是1个小时1美元。因此,LLaMA的成本大约是:
2048*5*30*24=7372800
也就是737万美元!不过,对于MetaAI来说,他们的费用肯定比这个低了,而且这是好几个版本的结果。根据论文的描述,LLaMA的训练成本与OPT或者其它的模型的对比:
这表明,最小的LLaMA-7B模型是在82432小时的A100-80GB GPU上进行训练的,成本为36兆瓦时,并产生14吨CO2。
根据每小时1美元的经验法则,这意味着,如果你在第一次训练中做对了一切,你可以花费约8.2万美元训练一个LLaMA-7B规模(即70亿参数)的模型。
三、低成本的关键方法来源二:Alpaca
你可以在自己的笔记本电脑(甚至手机)上运行LLaMA 7B,但你可能会发现很难获得良好的结果。这是因为它没有进行指令调整,所以在回答你可能会发送给ChatGPT、GPT-3或4的提示时,它不是很出色。
Alpaca是斯坦福大学的项目(参考:斯坦福开源媲美OpenAI的text-davinci-003轻量级开源预训练模型——Stanford-Alpaca),他们对LLaMA进行了52,000个指令(有些指令的来源可疑)的微调,并声称因此获得了类似ChatGPT的性能......需要注意的是,Alpaca微调的成本不到100美元。Replicate团队已经重复了训练过程,并发布了一篇教程,介绍了他们是如何做到的(复现教程:https://github.com/antimatter15/alpaca.cpp )。
至此为止,8.2万美元+100美元,成本不到8.5万!
四、能否在浏览器中运行类似ChatGPT的模型?
至此为止,虽然我们可以低成本训练出一个ChatGPT模型,但是能否以一个较低的资源使用在类似浏览器的场景运行依然是一个非常值得关注的问题,毕竟端侧如果使用将能大大提升模型的便捷使用。
Alpaca的规模与LLaMA 7B相同,约为3.9GB(经过llama.cpp的4位量化)。而且LLaMA 7B已经被证明可以在许多不同的个人设备上运行:笔记本电脑、树莓派(非常缓慢)甚至是Pixel 5手机也可以以不错的速度运行!这意味着Alpaca应该也是可以在这些设备上运行的。
但是浏览器中目前还没有这样的测试。不过,有2个库让我们看到了浏览器中运行ChatGPT的希望。
第一个今年2月份发布的Transformers.js,这是Hugging Face Transformers模型库的WebAssembly端口,以前只能在服务器端Python上使用。而Xenova将它改造成可以在浏览器运行的库!
第二个是前几天发布的Web Stable Diffusion。这个团队设法使稳定扩散(Stable Diffusion)生成图像模型完全在浏览器中运行!
Web Stable Diffusion使用WebGPU,这是一个仍在发展中的标准,目前仅在Chrome Canary中工作。但它确实可行!它在38秒内渲染了一图片,展示了两只浣熊在森林里吃馅饼的场景。
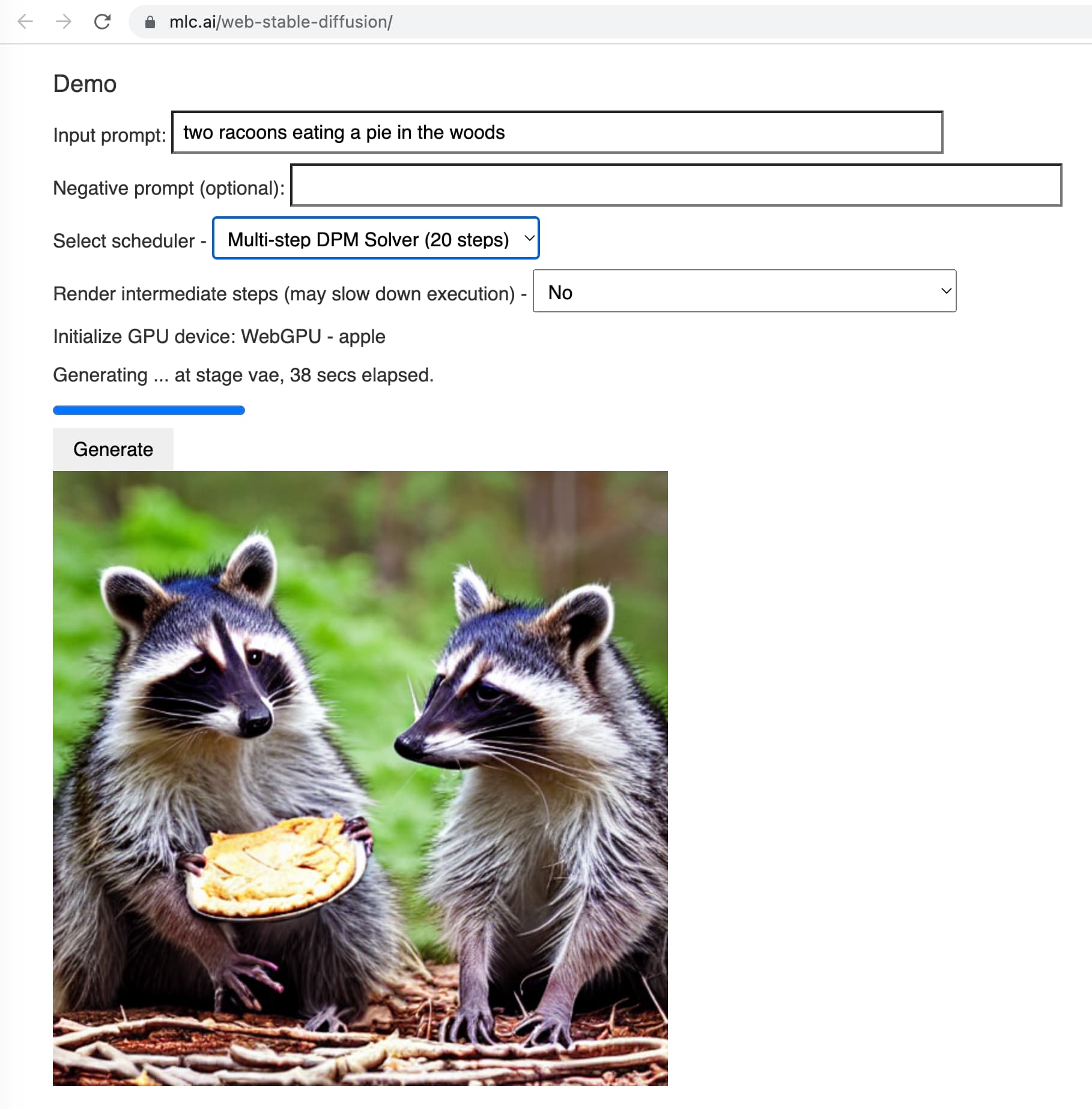
目前,这个Web Stable Diffusion加载的预训练模型是1.9GB,而INT4量化后的LLaMA/Alpaca只有3.9GB,说明基于浏览器运行一个完整的模型是非常有希望的。
五、基于ReAct增强对话能力
ReAct是来自谷歌论文《Synergizing Reasoning and Acting in Language Models》中的一个方法,它是2022年12月发表的。这是一种eason+Act(ReAct)的方式,让大模型的行动和推理一起协同,提高大模型解决问题的能力。也就是让模型在访问外部知识的情况下和自己的模型能力结合。其实这就是Bing中的ChatGPT的运行方式!这个简单的方法可以让模型有更强的能力。而它的实现其实只需要简单的几行代码即可。因此,在前面的低成本+浏览器运行的基础上,加上ReAct改造,几乎可以得到一个与ChatGPT类似或者甚至更好的对话模型!
原文:https://simonwillison.net/2023/Mar/17/beat-chatgpt-in-a-browser/
