抛弃RLHF?MetaAI发布最新大语言模型训练方法:LIMA——仅使用Prompts-Response来微调大模型
MetaAI最近公布了一个新的大语言模型预训练方法(LIMA: Less Is More for Alignment)。它最大的特点是不使用ChatGPT那样的(Reinforcement Learning from Human Feedback,RLHF)方法进行对齐训练。而是利用1000个精选的prompts与response来对模型进行微调,但却表现出了极其强大的性能。能够从训练数据中的少数几个示例中学习遵循特定的响应格式,包括从规划旅行行程到推测关于交替历史的复杂查询。
LIMA方法最主要的几个突破总结如下:
- 不使用RLHF(强化学习和人类反馈),仅使用精心挑选的prompts-response数据
- 对未出现在训练数据中的任务有良好的泛化能力
- 在43%的情况下,LIMA的响应等同于或优于GPT-4,与Bard和davinci003比较,这一比例甚至更高
- 你可以通过非常简单的方法和有限的指令调整获得高质量的输出
目前,MetaAI尚未宣布是否会开源这个模型(基于LLaMA-65B微调结果),LIMA在DataLearner上的模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/LIMA
LIMA模型简介
MetaAI最近公布了一个名为LIMA(Less Is More for Alignment,少即是多的对齐)的新模型,这在AI社区引起了轰动。LIMA是一个拥有650亿参数的LLaMA微调语言模型,它在仅有1000个精心策划的提示和响应上进行了标准的监督损失微调(standard supervised loss)。LIMA的特点是,它并不依赖任何强化学习或人类偏好建模,但却表现出了极其强大的性能。
LIMA的核心思想和方法解释
MetaAI认为当前的大语言模型的训练可以大致分为2个阶段:一个是从原始文本中学习通用表示的无监督训练阶段,另一个是大规模的指令调整和强化学习以更好地对齐到最终任务和用户偏好。
而MetaAI认为,第二个阶段需要大量的人类标注的交互结果,非常的耗费时间和成本。但是,如果我们已经有了一个强大的预训练模型,那么应该可以有更简单的方法让模型拥有这样的能力。为此,MetaAI提出了LIMA,仅仅用1000个精心挑选的训练数据即可让模型激发强大的能力。
下图是LIMA使用的训练数据总结:
LIMA背后的核心思想是,对齐可以是一个简单的过程,可以是模型从与用户互动中学习相应的风格或格式,以展示在预训练期间已经获得的知识和能力。这种方法使LIMA能够从训练数据中的少数几个示例中学习遵循特定的响应格式,包括从规划旅行行程到推测关于交替历史的复杂查询。此外,该模型往往能很好地推广到未出现在训练数据中的未见任务。
LIMA的实验结果
在一个受控的人类研究中,LIMA的响应在43%的情况下与GPT-4相当或严格优于GPT-4。与Bard比较,这个统计数据高达58%,与通过人类反馈训练的DaVinci003比较,这个数字为65%。结果显示,LIMA能够遵循除50个分析提示中的6个之外的所有提示。50%的LIMA答案被认为是优秀的。

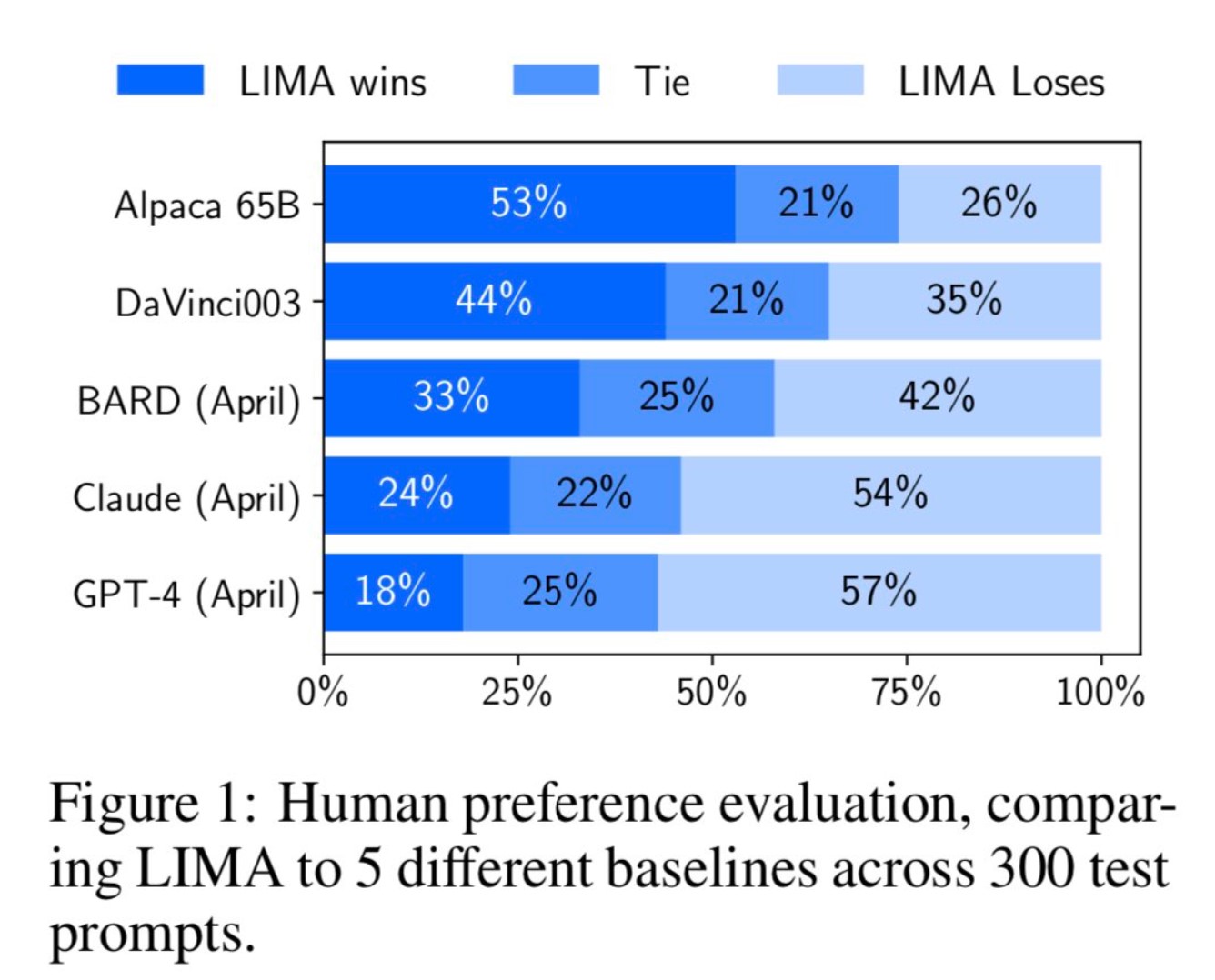
图1显示了人类偏好研究结果,而图2展示了GPT-4的偏好结果。二者很大程度上呈现出相同的趋势。主要测试结论如下:
- 尽管Alpaca 65B的训练数据是LIMA的52倍,但它产生的输出通常比LIMA的输出更不可取。
- 对于DaVinci003也是如此,尽管程度较轻;这个结果引人注目的是,DaVinci003是使用了一种被认为更优越的RLHF对齐方法进行训练的。
- Bard的情况与DaVinci003相反,它的回答比LIMA好的情况占了42%;然而,这也意味着58%的时间里,LIMA的回答至少和Bard一样好。
- 最后,虽然Claude和GPT-4通常比LIMA表现更好,但还是有相当数量的情况下,LIMA确实能够产生更好的回答。或许具有讽刺意味的是,即使是GPT-4自己也有19%的时间更喜欢LIMA的输出。
LIMA模型的争议
尽管LIMA引起了很多人的关注,同时MetaAI宣称LIMA模型的思想非常好,可以极大的降低模型在对齐阶段和指令微调方面的成本。但是,很多人对这个结果表示质疑。其中最大的问题在于它没有使用我们常见的那种评价方法对模型的得分进行计算,而是用人类评估的方法对比它和GPT-4等模型的好坏,缺乏足够强大的说服力。同时,这个模型目前也没有开源,外界无法进行评估。
