重磅!阿里巴巴开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B
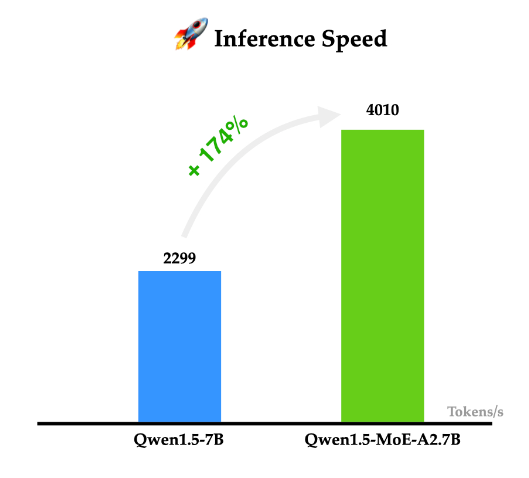
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
汇总「Qwen1.5-MoE」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。