
Stable Diffusion的最新实现——KerasCV的官方实现!
Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!
汇总「Keras」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!
KerasCV是由Keras官方团队发布的一个计算机视觉框架,可以帮助大家用来处理计算机视觉领域的相关任务和问题。这是2022年4月刚发布的最新产品,由于是官方团队出品的工具,所以质量有保证,且社区活跃,一直在积极更新。

最近一段时间Text-to-Image模型十分火热。OpenAI的DALL·E2模型的效果十分惊艳。不过,由于Open AI现在的不Open策略,大家还无法使用这个模型,业界只开放了一个小版本的DALL·E mini。不过,前段时间,Stability AI发布的Stable Diffusion其效果明显好于现有模型,且免费开放使用,让大家都开心了一把。不过原有模型是Torch实现的,而现在,基于Tensorflow/Keras实现的Stable Diffusion已经开源。
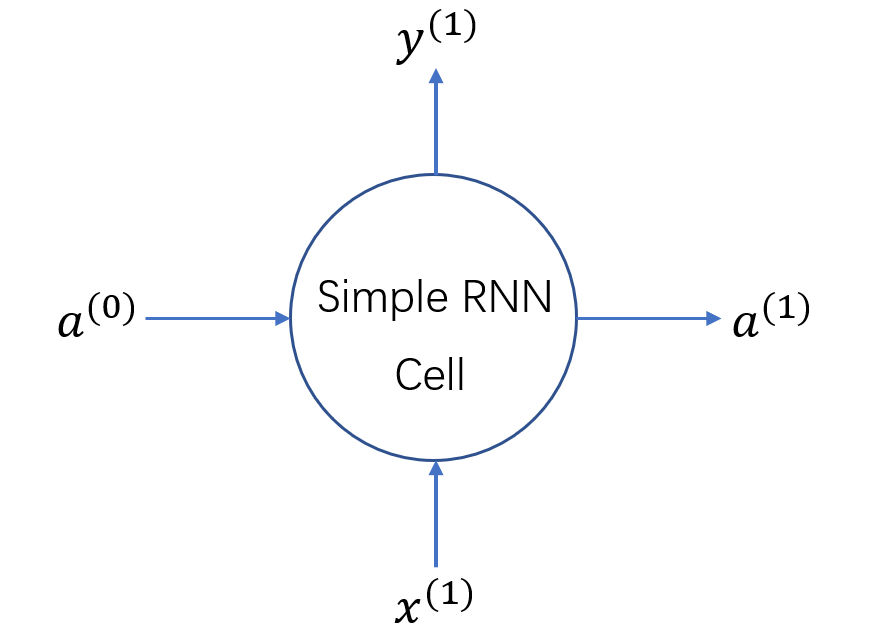
RNN的应用有很多,尤其是两个RNN组成的Seq2Seq结构,在时序预测、自然语言处理等方面有很大的用处,而每个RNN中一个节点是一个Cell,它是RNN中的基本结构。本文从如何使用RNN建模数据开始,重点解释RNN中Cell的结构,以及Keras中Cell相关的输入输出及其维度。我已经尽量解释了每个变量,但可能也有忽略,因此可能对RNN之前有一定了解的人会更友好,本文最主要的目的是描述Keras中RNNcell的参数以及输入输出的两个注意点。如有问题也欢迎指出,我会进行修改。


深度学习本质上是表示学习,它通过多层非线性神经网络模型从底层特征中学习出对具体任务而言更有效的高级抽象特征。针对一个具体的任务,我们往往会遇到这种情况:需要用一个模型学习出特征表示,然后将学习出的特征表示作为另一个模型的输入。这就要求我们会获取模型中间层的输出,下面以具体代码形式介绍两种具体方法。
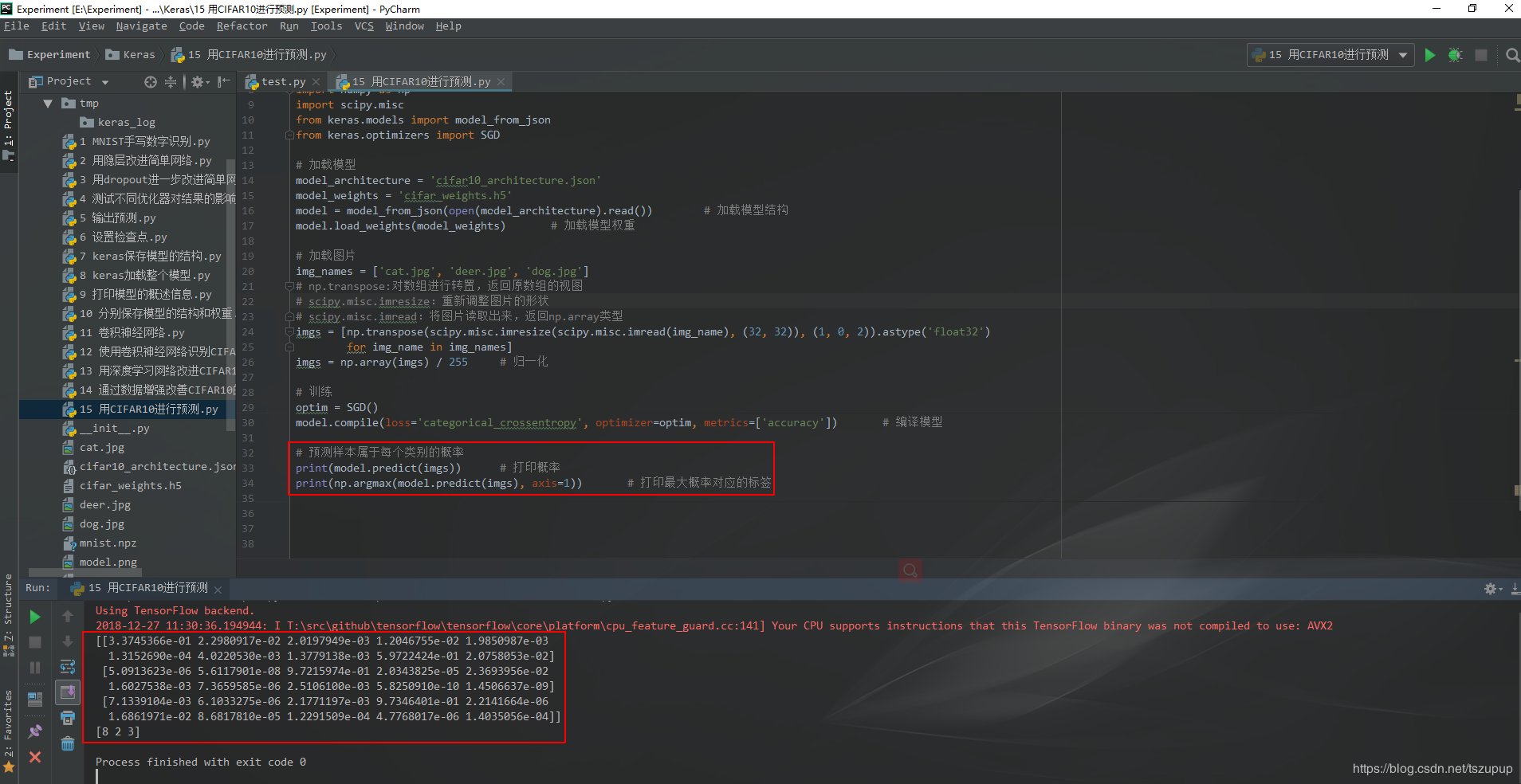
Keras中predict()方法和predict_classes()方法的区别
multi-class classification problem和 multi-label classification problem在keras上的实现