2025年的大模型训练和大模型应用与之前有什么差别?来自前OpenAI研究人员、特斯拉FSD负责人Andrej Karpathy的年度总结:2025年6个大模型不一样的地方
昨天,Karpathy 发布了《2025 LLM Year in Review》,对过去一年大模型领域发生的结构性变化进行了深度复盘。在这篇总结中,他不再纠结于具体的模型参数,而是将目光投向了推理范式的演进、Agent 的真实形态以及一种被称为“Vibe Coding”的新型开发模式。
汇总「RLHF」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
昨天,Karpathy 发布了《2025 LLM Year in Review》,对过去一年大模型领域发生的结构性变化进行了深度复盘。在这篇总结中,他不再纠结于具体的模型参数,而是将目光投向了推理范式的演进、Agent 的真实形态以及一种被称为“Vibe Coding”的新型开发模式。

在今年的Microsoft Build 2023大会上,来自OpenAI的研究员Andrej Karpathy在5月24日的一场汇报中用了40分钟讲解了ChatGPT是如何被训练的,其中包含了训练一个能支持与用户对话的GPT的全流程以及涉及到的一些技术。信息含量丰富,本文根据这份演讲总结。
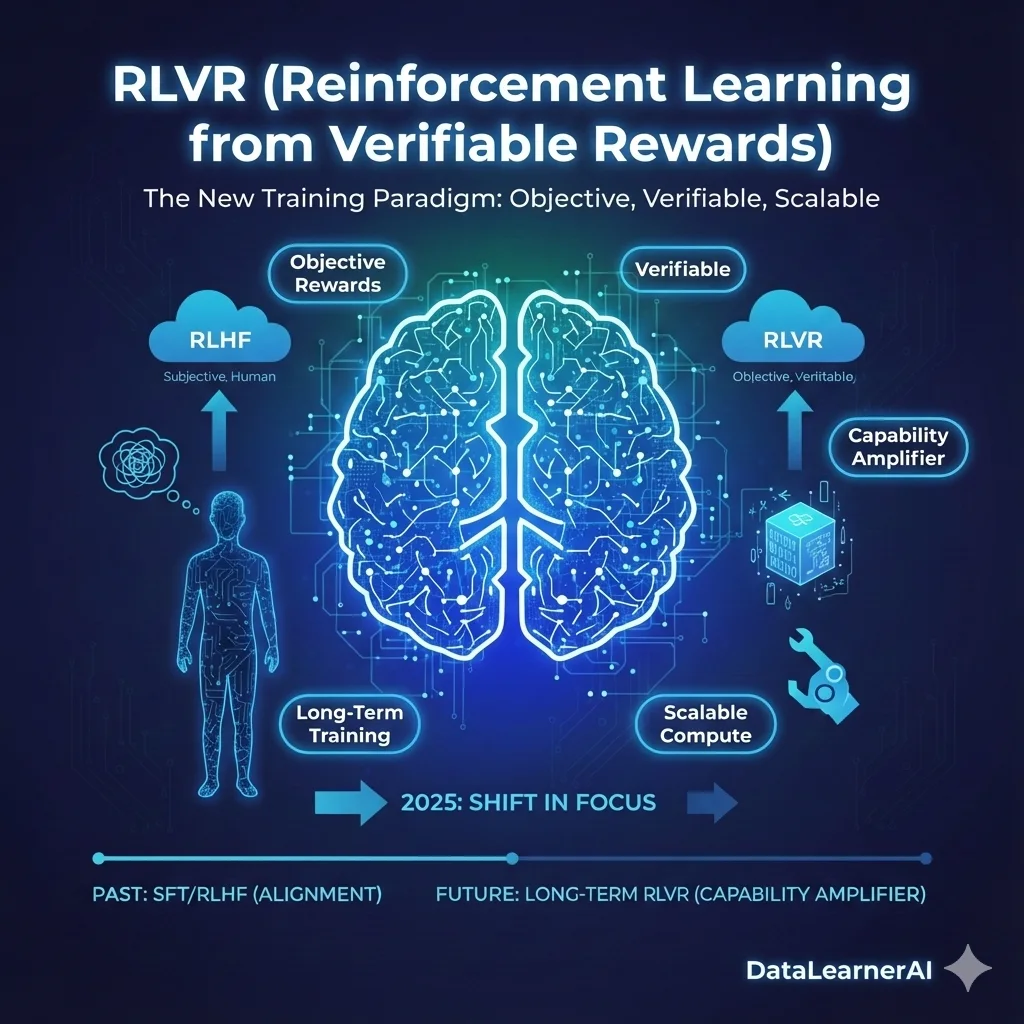
过去几年,大语言模型的训练路线相对稳定:更大的模型、更长的预训练、更精细的指令微调与人类反馈对齐。这套方法在很长一段时间内持续奏效,也塑造了人们对“模型能力如何提升”的基本认知。但在 2025 年前后,一种并不算新的训练思路突然被推到台前,并开始占据越来越多的计算资源与工程关注度,这就是**基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards,RLVR)**。
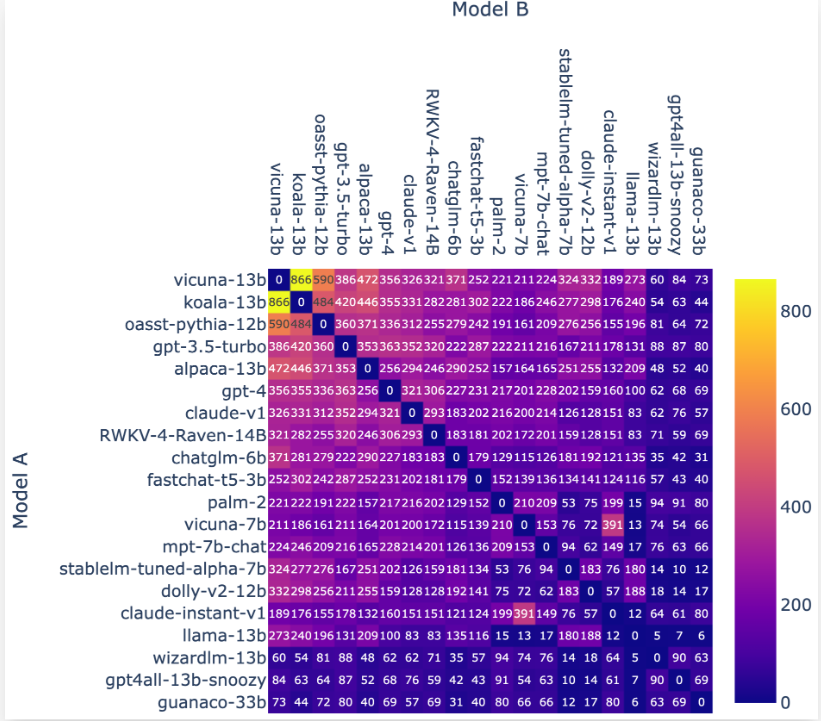
LM-SYS全称Large Model Systems Organization,是由加利福尼亚大学伯克利分校的学生和教师与加州大学圣地亚哥分校以及卡内基梅隆大学合作共同创立的开放式研究组织。该团队在2023年3月份成立,目前的工作是建立大模型的系统,是聊天机器人Vicuna的发布团队。今天开源 了包含3.3万包含真实人类偏好的对话数据集和3000条专家标注的对话数据集:Chatbot Arena Conversation Dataset和MT-bench人工注释对话数据集。
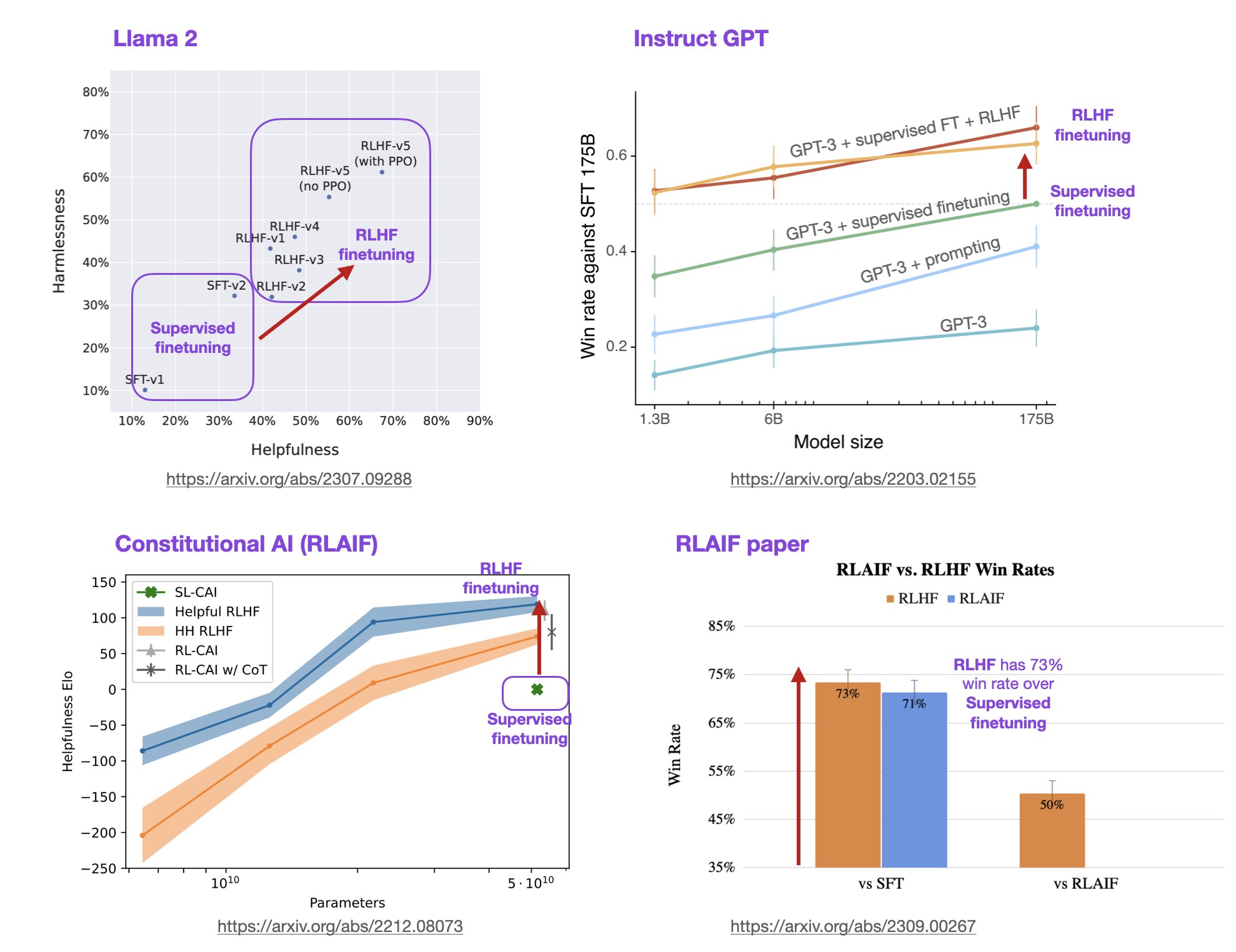
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。
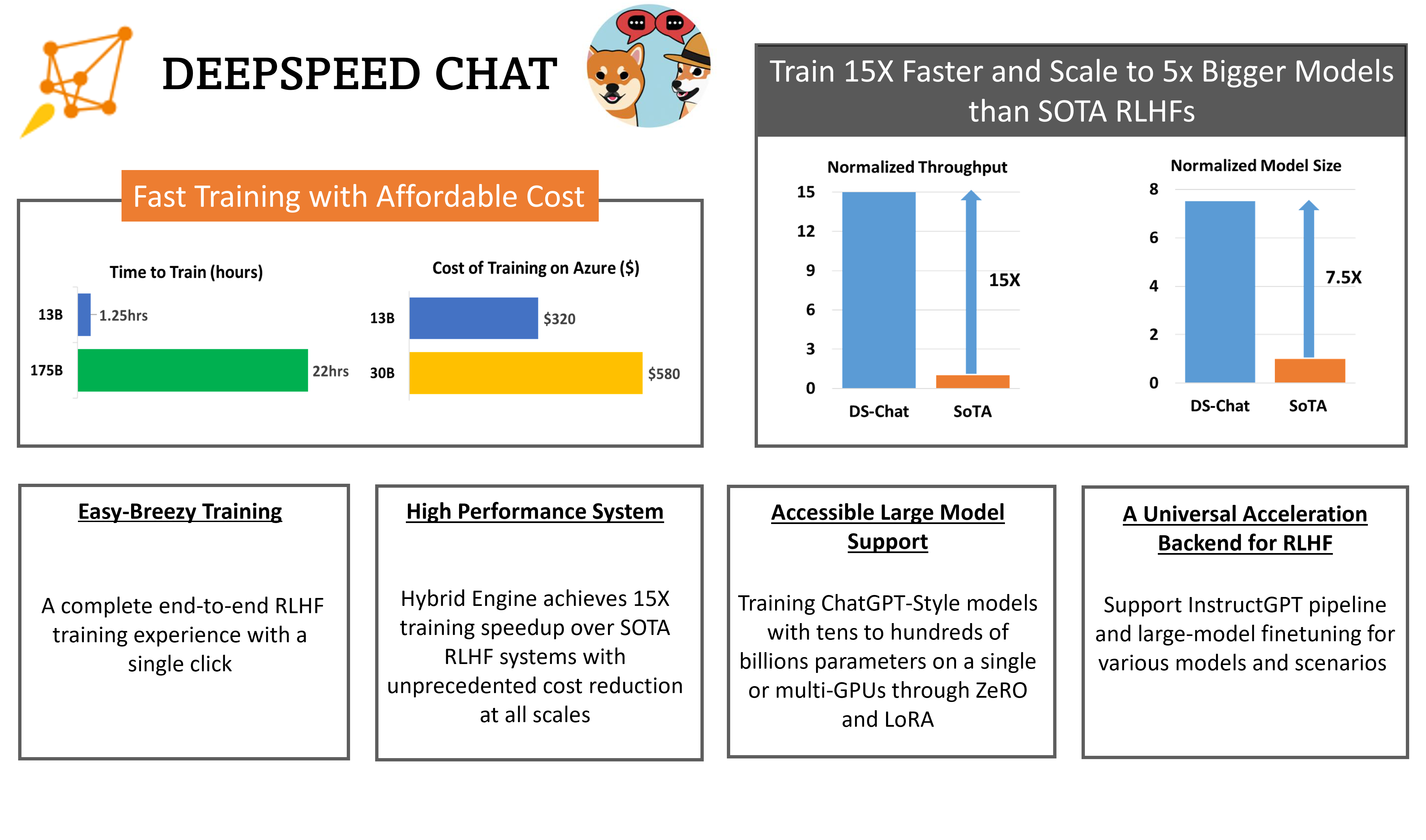
RLHF全称Reinforcement Learning from Human Feedback,是随着ChatGPT火爆之后而被大家所关注的技术。昨天,微软开源了业界第一个RLHF的pipeline框架,可以用来训练类似ChatGPT的模型。

最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。