UWMadison前统计学教授详解大模型训练最重要的方法RLHF,RLHF原理、LLaMA2的RLHF详解以及RLHF替代方法
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。
威斯康星大学麦迪逊分校(University of Wisconsin-Madison)前统计学教授、现任LightningAI的首席AI专家Sebastian Raschka详细解释了RLHF的原理以及LLaMA2的RLHF方法,并总结了一些RLHF替代方法。本文将核心内容总结翻译。
需要注意的是,在Microsoft Build 2023大会上来自OpenAI的研究员Andrej Karpathy的报告也指出关于为什么RLHF效果更好的真正原因,目前没有一个大家可以都同意的观点。但是,大家都用的原因其实就是效果更好。不过需要注意的是在实际应用中,也有人发现,并不是所有情况下,RLHF模型都比基础模型更好。尽管RLHF模型可以更好地遵从人的意图,但是它丢失了一些entropy。意思是基础模型可以生成更加多样性的结果,而RLHF模型会生成更多peaky的结果。
RLHF简介
在此前的文章中,DataLearner已经总结过大语言模型的一般训练过程,主要包括预训练阶段、有监督微调阶段和对齐微调阶段(参考1:如何训练一个大语言模型?当前基于transformer架构的大语言模型的通用训练流程介绍;参考2:来自Microsoft Build 2023:大语言模型是如何被训练出来的以及语言模型如何变成ChatGPT——State of GPT详解)。
其中,最后一步的对齐微调阶段也可以继续分为2个步骤,一个是奖励建模阶段,主要是训练一个奖励函数对齐模型,然后再基于这个奖励模型继续进行强化学习,可以得到一个能支持与用户对话的类似“ChatGPT”的模型。
为简单起见,Sebastian Raschka把RLHF流程继续分为三个独立的步骤(相比此前的步骤,主要是把前面的有监督微调也纳入到了RLHF中):
-
RLHF步骤1:对预训练模型进行监督微调
-
RLHF步骤2:创建奖励模型
-
RLHF步骤3:通过近端策略优化进行微调
如下所示,RLHF步骤1是监督微调步骤,用于创建进一步RLHF微调的基本模型。
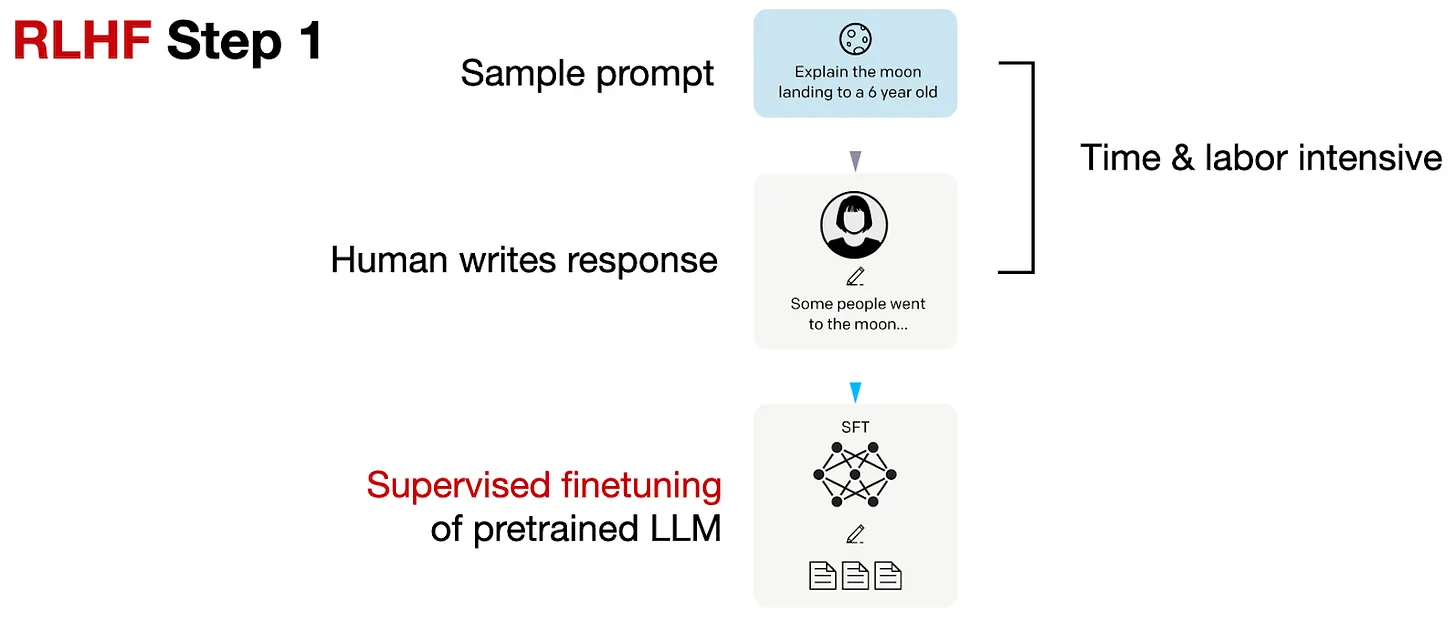
RLHF步骤1:对预训练模型进行监督微调
在RLHF步骤1中,我们创建或从数据库中抽样提示,并要求人类编写高质量的响应。然后,我们使用这个数据集以监督的方式微调预训练的基本模型。
请注意,这个RLHF步骤1与前面的监督微调基本上可以理解是一个步骤。
RLHF步骤2:创建奖励模型
在RLHF步骤2中,我们然后使用这个经过监督微调的模型创建奖励模型,如下所示。
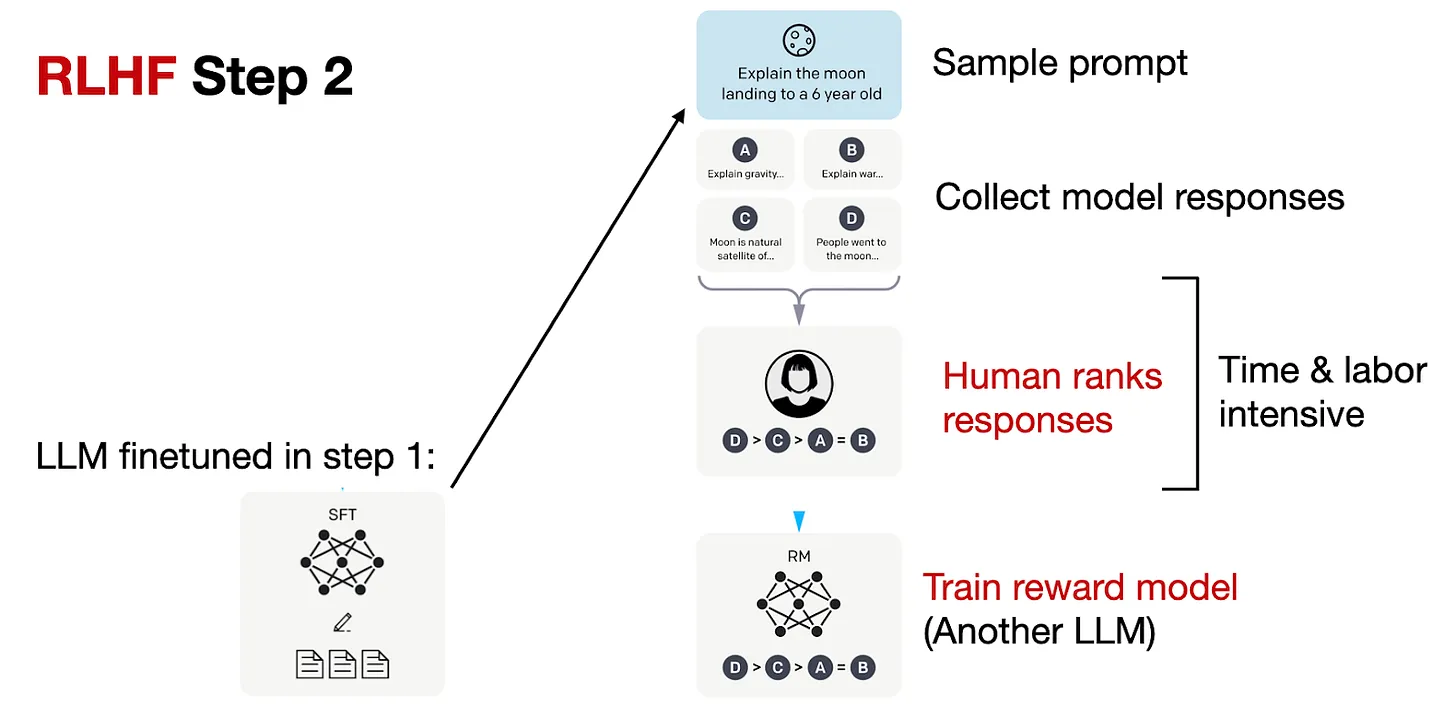
如上图所示,对于每个提示,我们使用在前一步创建的微调LLM生成四到九个响应。然后,个人根据他们的偏好对这些响应进行排名。尽管这个排名过程很耗时,但它可能比创建监督微调的数据集要少劳动密集。这是因为排名响应可能比编写响应更简单。
在编制了这些排名的数据集后,我们可以设计一个奖励模型,该模型将在RLHF步骤3中的优化后阶段输出奖励分数。这个奖励模型通常源自在前一监督微调步骤中创建的LLM。让我们将奖励模型称为RM,将监督微调步骤中的LLM称为SFT。为了将RLHF步骤1中的模型变成奖励模型,它的输出层(下一个令牌分类层)被替换为一个带有单个输出节点的回归层。
RLHF步骤3:通过近端策略优化进行微调
RLHF流程的第三步是使用奖励(RM)模型对来自监督微调的先前模型(SFT)进行微调,如下图所示。
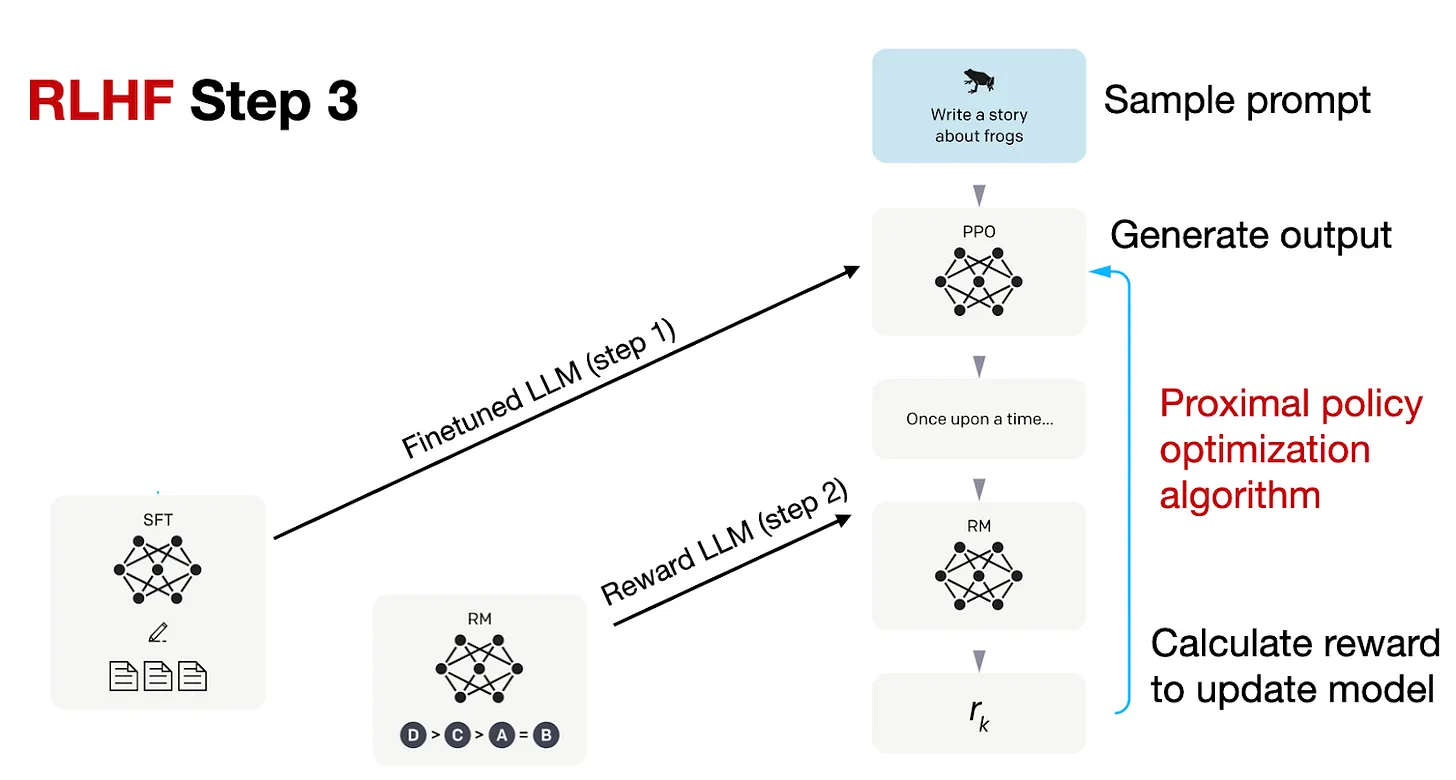
在RLHF步骤3中,最后一阶段,我们现在使用奖励模型的奖励分数来更新SFT模型,这是基于我们在RLHF步骤2中创建的奖励模型的奖励分数。
上述步骤也是来自于OpenAI 的 InstructGPT 论文中描述的 RLHF 过程。这个方法通常被引用为开发 ChatGPT 所使用的方法。但是实际上是否在ChatGPT中使用或者方法是否完全一致,OpenAI没有公布。
这里再次总结一下RLHF方法的主要要点:
-
监督微调(Supervised Fine-Tuning):RLHF的第一步通常是采用一个预训练的模型,然后通过监督学习的方式对其进行微调。在这个阶段,人类为模型提供示例,要求模型生成高质量的响应。这些示例可以是来自数据库的提示或人工创建的。监督微调的目的是让模型学习生成与人类期望相符的响应。
-
奖励模型的创建(Creating a Reward Model):在监督微调之后,RLHF使用微调的模型来生成一种奖励模型。这个奖励模型用于衡量模型生成的响应的质量。通常,人类会对给定的提示生成多个响应,并对这些响应进行排名或评分。这些排名或评分构成了奖励模型的基础,它们指导后续的学习和优化过程。
-
强化学习优化(Reinforcement Learning Optimization):在获得了奖励模型后,RLHF采用强化学习技术,如近端策略优化(Proximal Policy Optimization,PPO),来进一步微调模型。在这个阶段,模型尝试最大化其生成的响应的奖励分数。这意味着模型会更加聚焦于生成被认为是高质量的响应。
-
迭代优化(Iterative Optimization):RLHF通常涉及多轮迭代,其中人类提供的反馈和奖励模型的更新用于不断改进模型的性能。这个过程可以重复多次,以逐渐提升模型的表现。
总的来说,基于人类反馈的强化学习方法允许机器学习模型通过与人类的互动来提高其性能,而不仅仅是通过传统的强化学习信号(奖励信号)进行训练。这种方法在自然语言处理、机器翻译、对话系统等领域取得了显著的成就,因为它能够充分利用人类智慧来指导模型的学习和决策,从而生成更自然、更符合人类期望的输出。然而,它也需要涉及人类的努力和反馈,因此在实践中需要权衡人力成本和性能提升之间的关系。
LLaMA2中的RLHF方法介绍
LLaMA2(https://www.datalearner.com/ai-models/pretrained-models/llama-2-7b )是由MetaAI开源的最新的的大语言模型,它集成了LLaMA的优良效果,在各方面的评测中提升也很大。最重要的是,它对模型的对齐微调做得非常严格,让该模型在很多方面受到了严格的限制。
Meta AI在创建 Llama-2-chat 模型时使用了 RLHF。然而,该方法与上述OpenAI公开的RLHF方法之间有一些区别。
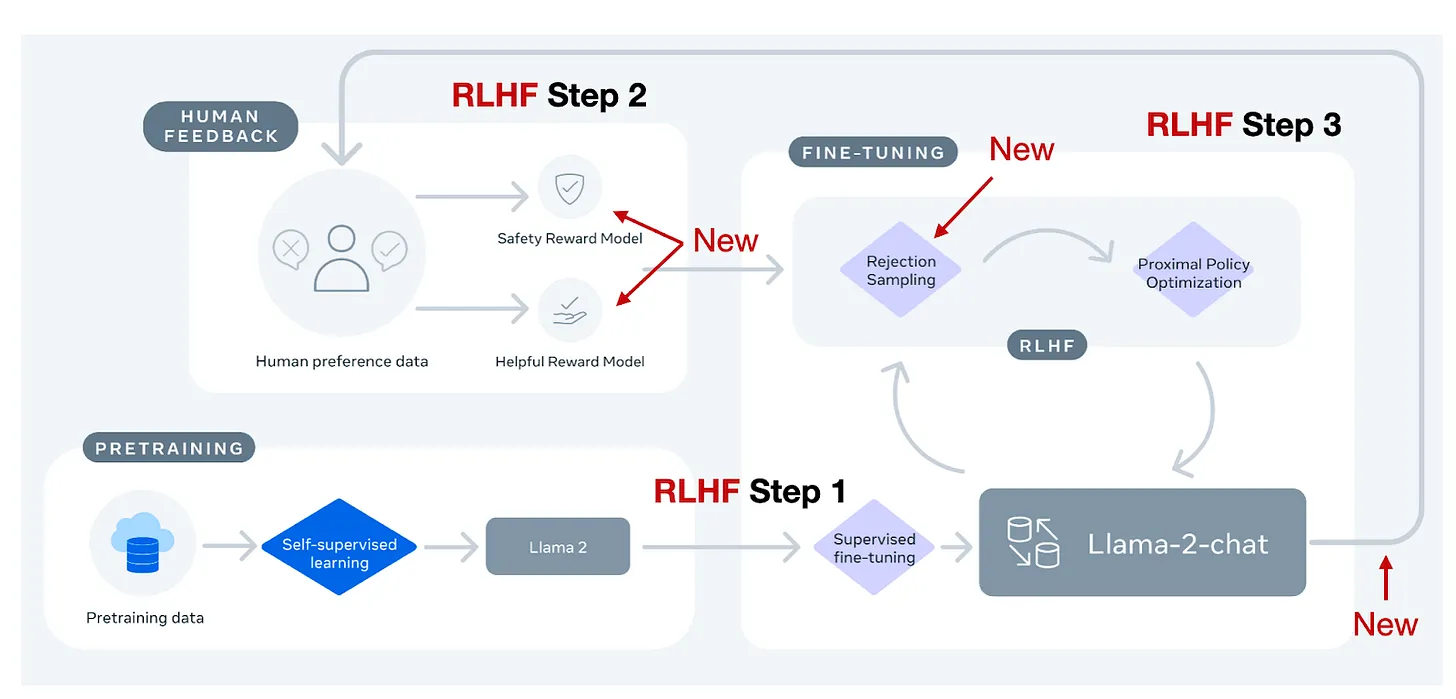
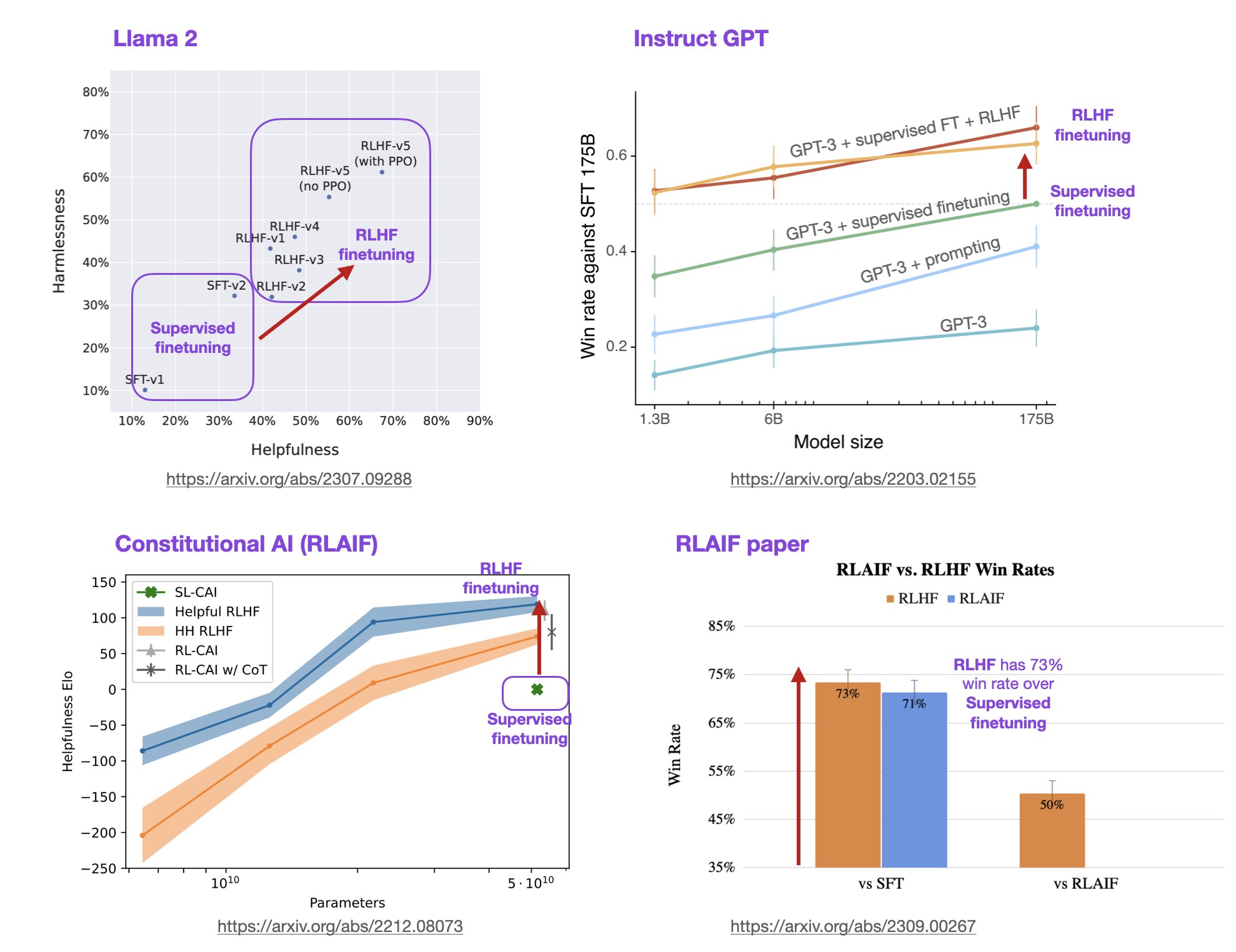
Sebastian Raschka教授在上图中做了总结,可以看到LLaMA2的RLHF的方法比OpenAI的方法实际上是多了一些新东西的。
总的来说,Llama-2-chat 在 RLHF 步骤 1 中与 InstructGPT 相同,都在指导数据上进行了监督微调。然而,在 RLHF 步骤 2 中,不同于只创建一个奖励模型,而是创建了两个奖励模型。此外,Llama-2-chat 模型经历了多个阶段,奖励模型根据从 Llama-2-chat 模型中出现的错误进行更新。还增加了拒绝抽样步骤。
边际损失
在上述带注释的图中没有展示的另一个区别与模型响应的排名方式有关,以生成奖励模型。在之前讨论的 RLHF PPO 的标准 InstructGPT 方法中,研究人员收集排名为 4-9 的输出响应,然后创建了“k 选择 2”比较。
例如,如果一个人类标注者对四个响应(A-D)进行排名,如 A < C < D < B,那么就会产生“4 选择 2”的 6 个比较:
A < C A < D A < B C < D C < B D < B 类似地,Llama 2 的数据集基于响应的二进制比较,例如 A < B。但是,似乎每个人类标注者每次只呈现了 2 个响应(而不是 4-9 个响应)。
此外,新的地方在于每个二进制排名旁边还会收集一个“边际”标签(从“显著更好”到“微不足道更好”),可以选择通过附加的边际参数在二进制排名损失中使用,以计算两个响应之间的差距。
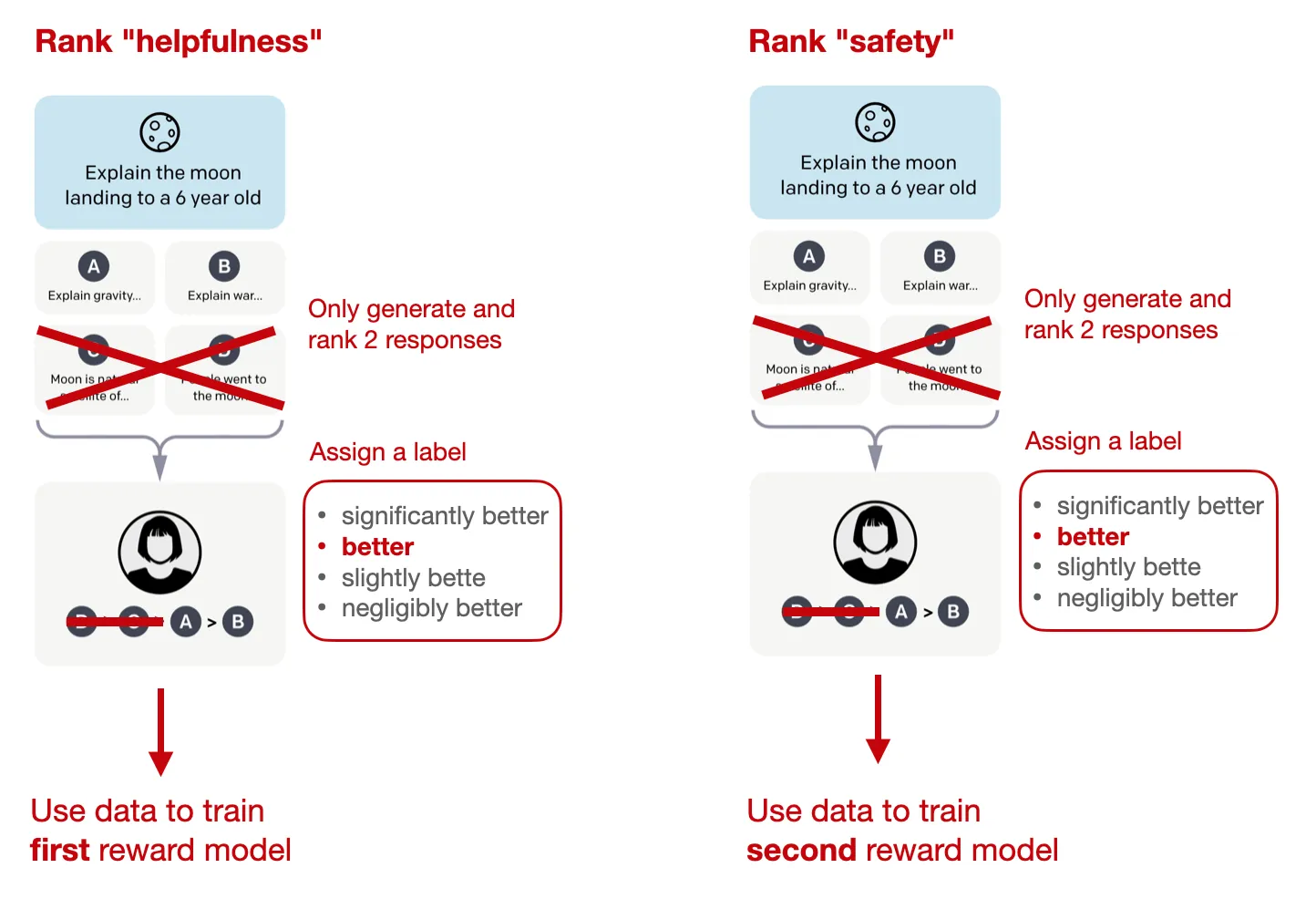
两个奖励模型
如前所述,Llama 2 中有两个奖励模型,而不是一个。一个奖励模型基于帮助性,另一个基于安全性。然后,用于模型优化的最终奖励函数是这两个分数的线性组合。
拒绝抽样
此外,Llama 2 的作者采用了一个训练管道,迭代地生成多个 RLHF 模型(从 RLHF-V1 到 RLHF-V5)。与我们之前讨论的仅仅依赖 RLHF 和 PPO 方法不同,他们使用两种算法进行 RLHF 微调:PPO 和拒绝抽样。
在拒绝抽样中,会选择 K 个输出,其中奖励最高的一个将在优化步骤中被选择,如下图所示。
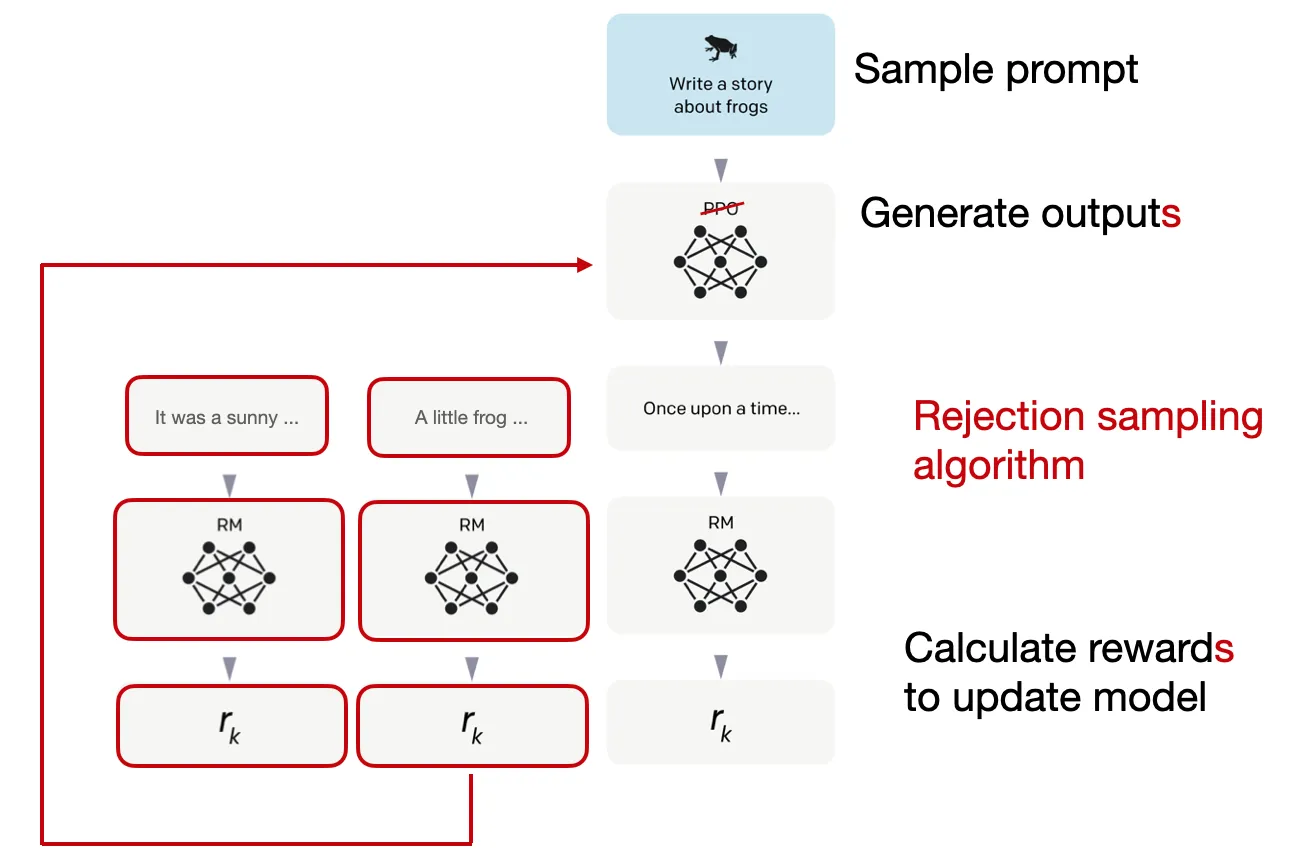
拒绝抽样用于在每次迭代中选择奖励得分较高的样本。因此,与基于单个样本进行更新的 PPO 相比,模型将使用更高奖励的样本进行微调。
在监督微调的初始阶段之后,模型将仅使用拒绝抽样进行训练,然后在后来将拒绝抽样和 PPO 结合使用。
研究人员绘制了模型在 RLHF 阶段的性能,显示了 RLHF 微调的模型在无害性和帮助性两个方面都有所改进。
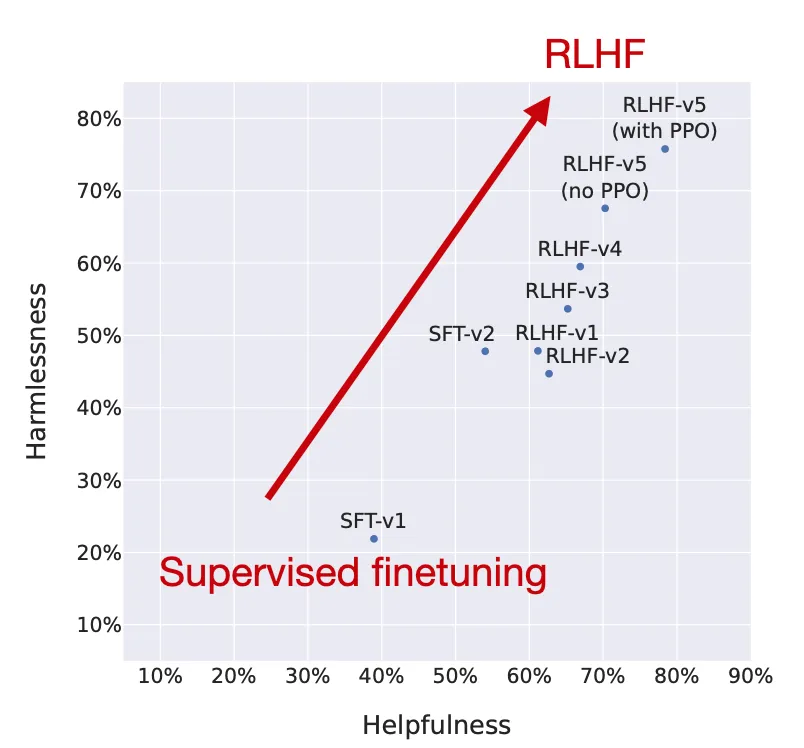
请注意,研究人员在最后一步中使用了 PPO,继续之前通过拒绝抽样更新的模型。正如上图中的“RLHF-v5(带 PPO)”和“RLHF-v5(无 PPO)”的比较所示,最后阶段使用 PPO 训练的模型要比仅使用拒绝抽样训练的模型更好。 (个人而言,我很想看看它与仅使用 PPO 而不使用拒绝抽样微调的模型相比如何。)
RLHF的替代方法
从前面的描述也可以看到RLHF是个非常复杂的过程。但是从实际测试的结果看,这个过程是值得大家费时间去做的。在前面的图中,我们已经看到RLHF对于模型带来的提升了。
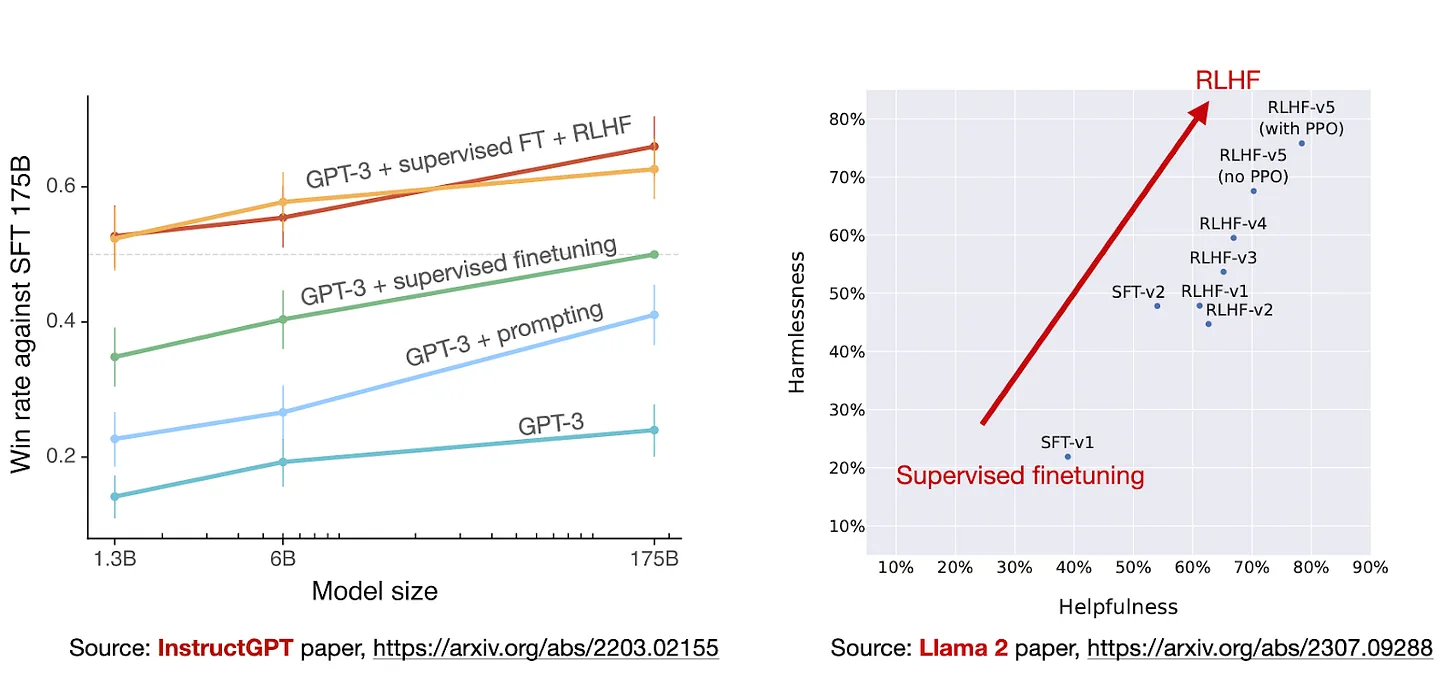
然而,许多正在进行的研究都集中在开发更高效的替代方法上。Sebastian Raschka总结了一些RLHF的替代方法。
(1)Constitutional AI: Harmlessness from AI Feedback(2022年12月,https://arxiv.org/abs/2212.08073)
研究人员提出了一种基于人类提供的规则列表的自我训练机制。类似于前面提到的InstructGPT论文,所提出的方法使用了一种强化学习方法。
来自AI反馈的图中研究人员使用的术语“红队测试”是指一种源自冷战军事演习的测试方法,最初指的是一组扮演苏联角色以测试美国战略和防御的团队。在AI研究的网络安全背景下,“红队测试”一词现在用来描述一种过程,即外部或内部专家模拟潜在对手,通过模仿现实世界攻击者的策略、技术和程序来挑战、测试和最终改进感兴趣的系统。
(2)The Wisdom of Hindsight Makes Language Models Better Instruction Followers (2023年2月,https://arxiv.org/abs/2302.05206)
“事后睿智使语言模型更好地遵循指令”表明,监督方法对于LLM微调确实可以很好地工作。在这里,研究人员提出了一种基于重新标记的监督方法,用于微调,该方法在12个BigBench任务中优于RLHF。
所提出的HIR(事后指令标记)是如何工作的?简而言之,HIR方法包括两个步骤,取样和训练。在取样步骤中,将提示和指令提供给LLM以收集响应。根据对齐分数,适当地重新标记指令,然后将重新标记的指令和原始提示用于微调LLM。通过使用这种重新标记的方法,研究人员有效地将失败案例(LLM创建不符合原始指令的输出的情况)转化为用于监督学习的有用训练数据。
请注意,这项研究与InstructGPT中的RLHF工作并不直接可比较,因为它似乎在使用启发式方法(“然而,由于大多数人类反馈数据难以收集,我们采用了一种脚本化的反馈函数...”)。然而,HIR事后方法的结果仍然非常引人注目。
(3) Direct Preference Optimization: Your Language Model is Secretly a Reward Model(https://arxiv.org/abs/2305.18290,2023年5月)
直接偏好优化(DPO)是一种用于RLHF的PPO的替代方案,研究人员在其中展示了RLHF中奖励模型的交叉熵损失可以直接用于微调LLM。根据他们的基准测试,使用DPO更高效,通常在响应质量方面也优于RLHF/PPO。
(4)Reinforced Self-Training (ReST) for Language Modeling(2023年8月,https://arxiv.org/abs/2308.08998)
ReST是RLHF的替代方案,它通过采样方法创建改进的数据集,迭代地在越来越高质量的子集上进行训练,以完善其奖励函数。根据作者的说法,ReST与标准在线RLHF方法(如InstructGPT或Llama 2中使用的RLHF PPO方法)相比,更加高效,因为它在离线生成其训练数据集,但与标准RLHF PPO方法的全面比较缺失。
(5) RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback(2023年9月,https://arxiv.org/abs/2309.00267)
最近的强化学习与AI反馈(RLAIF)研究表明,在RLHF中用于奖励模型训练的评级不一定必须由人类提供,而可以由LLM(此处为PaLM 2)生成。人类评估者一半的时间更喜欢RLAIF模型,而不是传统的RLHF模型,这意味着他们实际上对这两种模型没有偏好。
参考文献和原文地址
原文地址:https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
部分关于PPO的参考文献如下:
(1)《深度强化学习的异步方法》(2016)由Mnih、Badia、Mirza、Graves、Lillicrap、Harley、Silver和Kavukcuoglu介绍了基于策略梯度方法作为深度学习强化学习中Q学习的替代方法。
(2)《近端策略优化算法》(2017)由Schulman、Wolski、Dhariwal、Radford和Klimov提出了一种修改的近端策略强化学习过程,比上述普通策略优化算法更具数据效率和可伸缩性。
(3)《从人类偏好中微调语言模型》(2020)由Ziegler、Stiennon、Wu、Brown、Radford、Amodei、Christiano、Irving等人阐述了PPO和预训练语言模型的奖励学习概念,包括KL正则化以防止策略偏离自然语言太远。
(4)《从人类反馈中学习摘要》(2020)由Stiennon、Ouyang、Wu、Ziegler、Lowe、Voss、Radford、Amodei、Christiano等人介绍了流行的RLHF三步流程,后来也在InstructGPT论文中使用。
