大模型领域最著名开源模型小羊驼Vicuna升级!Vicuna发布1.5版本,可以免费商用了!最高支持16K上下文!
Vicuna是开源领域最强最著名的大语言模型,是UC伯克利大学的研究人员联合其它几家研究机构共同推出的一系列基于LLaMA微调的大语言模型。这个系列的模型因为极其良好的表现以及官方提供的匿名评测而广受欢迎。今天,LM-SYS发布Vicuna 1.5版本,包含4个模型,全部基于LLaMA2微调,最高支持16K上下文输入,最重要的是基于LLaMA2的可商用授权协议!免费商用授权!
Vicuna简介
近年来,大型语言模型(LLMs)的快速发展已经彻底改变了聊天机器人系统,OpenAI的ChatGPT显示出前所未有的智能水平。然而,尽管其表现出色,但ChatGPT的训练和架构细节仍然不清楚,这阻碍了在这个领域的研究和开源创新。
受Meta的LLaMA和斯坦福大学Alpaca项目的启发,Vicuna系列模型诞生,这是一个开源聊天机器人,具备增强的数据集和易于使用的可扩展基础设施支持。它由多个高校的老师和学生联合发布(包括UC伯克利分校、CMU等)。通过在从ShareGPT.com收集的用户共享对话上微调LLaMA基础模型,Vicuna-13B已经表现出与斯坦福大学Alpaca等其他开源模型相比的竞争性能。
Vicuna已经推出就在各个领域产生了巨大的影响,因为其效果很好,并且提供匿名评测,受到了广泛关注。在各个评测排行上也占据前排。不过可惜的是,Vicuna是基于LLaMA-1微调的,由于LLaMA-1的限制,Vicuna不可用在商业上。而今天发布的Vicuna1.5系列则是基于LLaMA2微调的,支持免费商用!
Vicuna 1.5介绍
Vicuna 1.5系列包含4个模型,与第一代相同参数的的Vicuna 7B(1.5)、Vicuna 13B(1.5)以及在此基础上拓展的支持最高16K上下文输入的Vicuna 7B 16K和Vicuna 13B 16K两个模型。
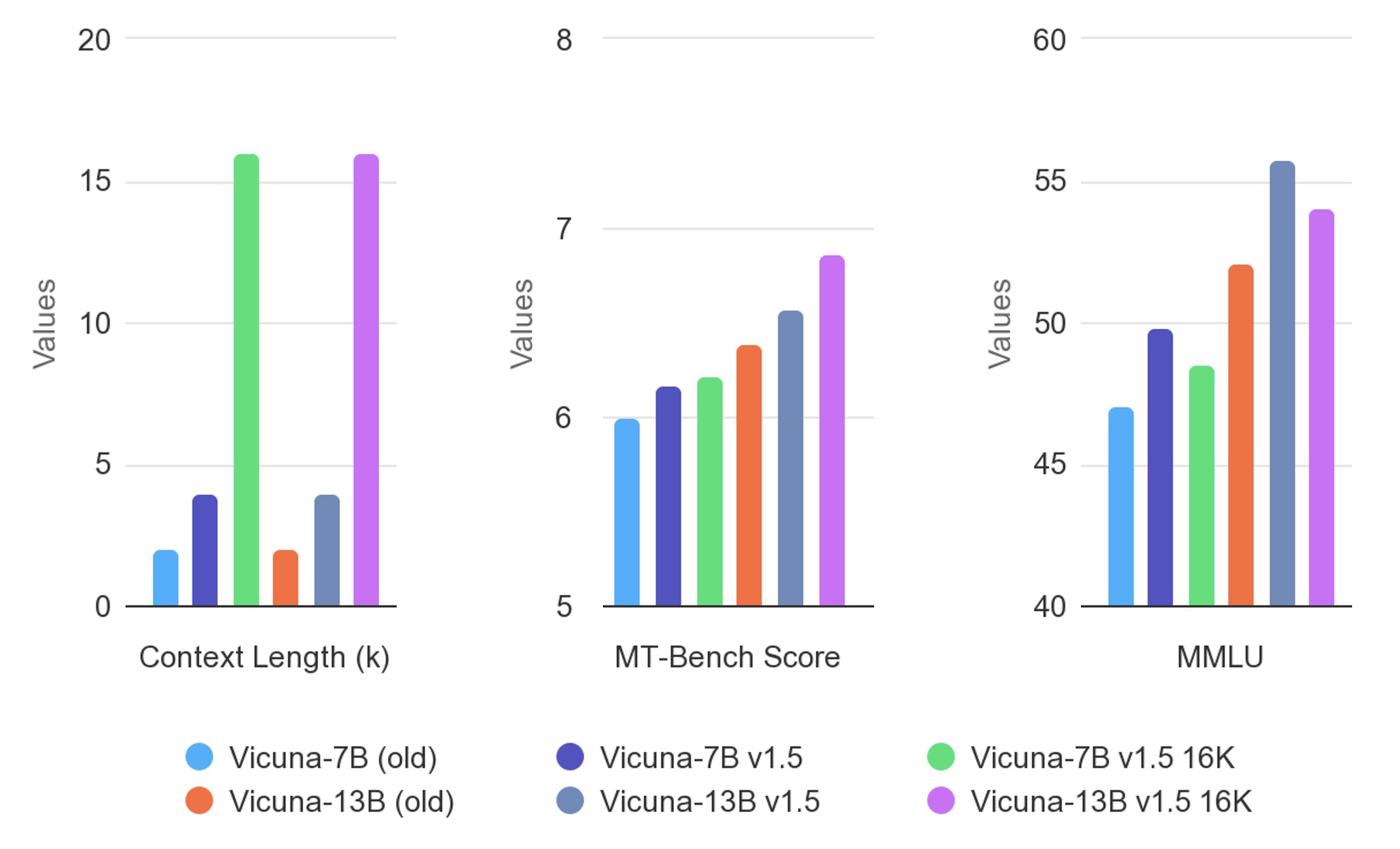
下图展示了Vicuna 1.5版本与旧版的性能对比。可以看到,在MT-Bench和MMLU两个评测结果上,Vicuna 1.5版本的效果都有提升。其中,在MT-Bench表现上,Vicuna 13B 16K模型已经接近了7分,而在第八周的评测上,7分以上的2个模型都是300亿参数,和闭源的GPT-4、Claude等。应该说提升很明显。
而在MMLU的评测上,1.5版本的Vicuna 13B提升明显,超过了55分。效果也是很不错的。
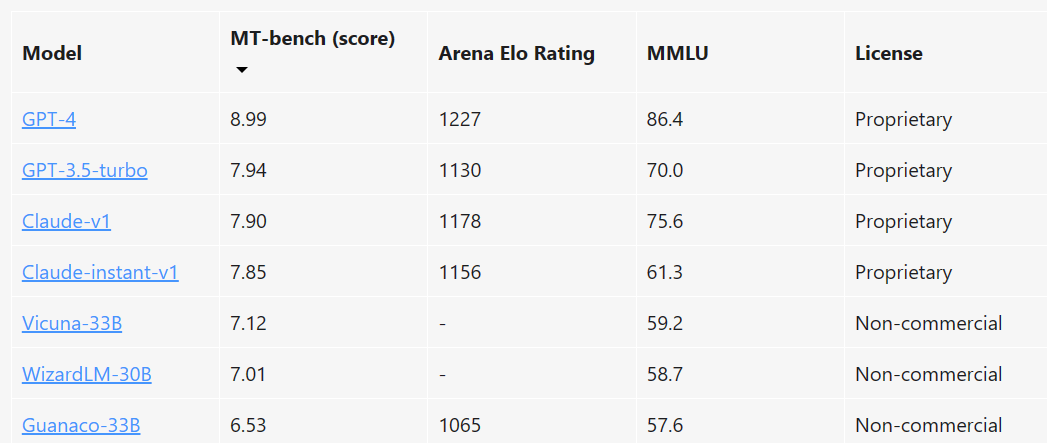
需要注意的是,此前MT-Bench排行靠前的是商业模型和不能商用的模型,而如果Vicuna 1.5系列能够进入前列,表明开源可商用的大模型有了更好的选择!
此外,本次的1.5版本暂时不包含33B的进展,原因应该是LLaMA2没有33B版本,有一个70B的版本,700亿规模的参数模型微调可能是比较耗费时间也可能比较贵~
但是按照其它2个版本的提升,如果能基于70B模型微调Vicuna 70B 1.5版本,那么将对我们来说是天大的好消息!
Vicuna 1.5版本模型地址
在DataLearner上已经更新了1.5版本的开源地址和其它资源信息,大家参考:
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
