
GPT-5.5为什么喜欢用哥布林做比喻回答你?哥布林从何而来——OpenAI 亲自揭秘一次训练跑偏的全过程
为什么 ChatGPT 会突然爱上“哥布林”?OpenAI 最新披露的“Goblin 事件”揭示了一个关键问题:在 RLHF 训练中,一个微小的奖励偏差,如何从 2.5% 的场景扩散到整个模型。本文带你看清大模型如何“学歪”、为什么测试发现不了,以及这对 AI Agent 时代意味着什么。
汇总「大模型训练」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
为什么 ChatGPT 会突然爱上“哥布林”?OpenAI 最新披露的“Goblin 事件”揭示了一个关键问题:在 RLHF 训练中,一个微小的奖励偏差,如何从 2.5% 的场景扩散到整个模型。本文带你看清大模型如何“学歪”、为什么测试发现不了,以及这对 AI Agent 时代意味着什么。
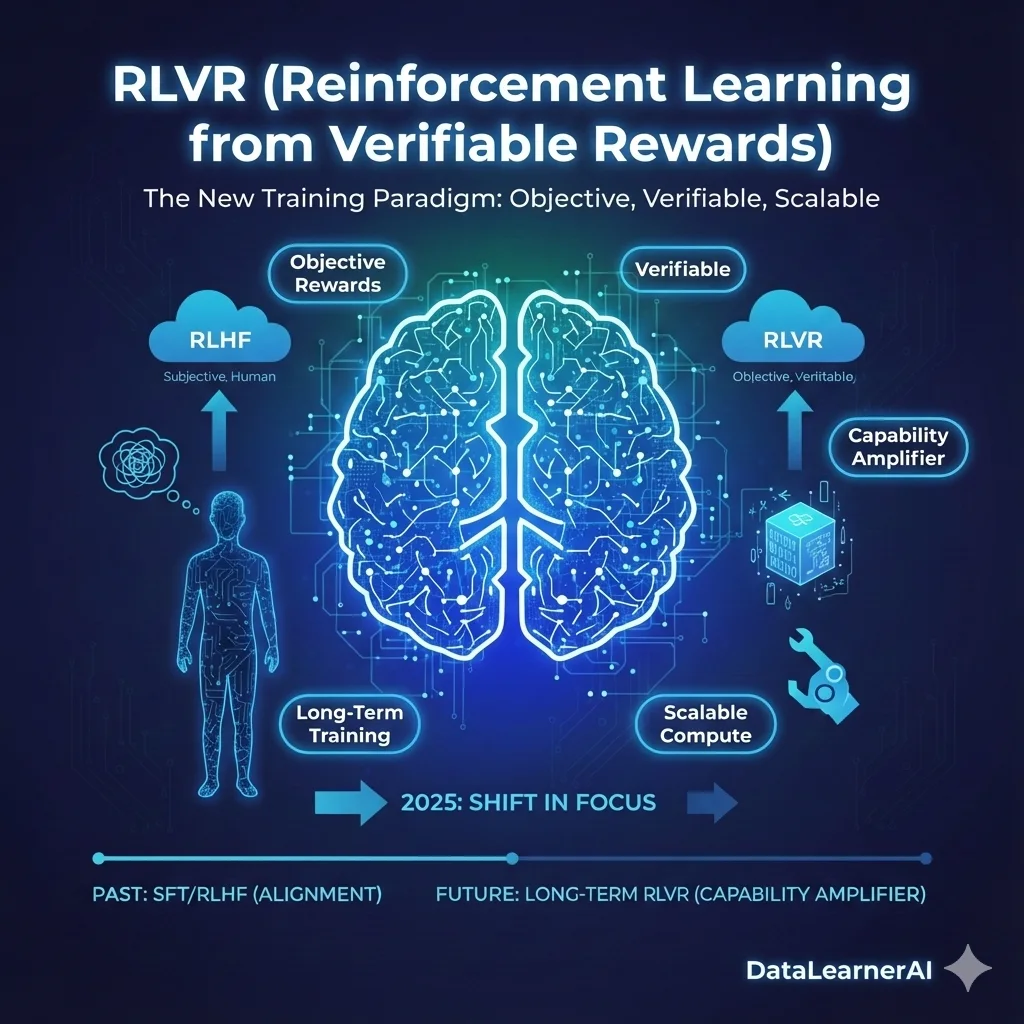
过去几年,大语言模型的训练路线相对稳定:更大的模型、更长的预训练、更精细的指令微调与人类反馈对齐。这套方法在很长一段时间内持续奏效,也塑造了人们对“模型能力如何提升”的基本认知。但在 2025 年前后,一种并不算新的训练思路突然被推到台前,并开始占据越来越多的计算资源与工程关注度,这就是**基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards,RLVR)**。

在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。
大语言模型的训练和微调的硬件资源要求很高。现行主流的大模型训练硬件一般采用英特尔的CPU+英伟达的GPU进行。主要原因在于二者提供了符合大模型训练所需的计算架构和底层的加速库。但是,最近苹果M2 Ultra和AMD的显卡进展让我们看到了一些新的希望。
大语言模型训练的一个重要前提就是高质量超大规模的数据集。为了促进开源大模型生态的发展,Cerebras新发布了一个超大规模的文本数据集SlimPajama,SlimPajama可以作为大语言模型的训练数据集,具有很高的质量。除了SlimPajama数据集外,Cerebras此次还开源了处理原始数据的脚本,包括去重和预处理部分。官方认为,这是目前第一个开源处理万亿规模数据集的清理和MinHashLSH去重工具。
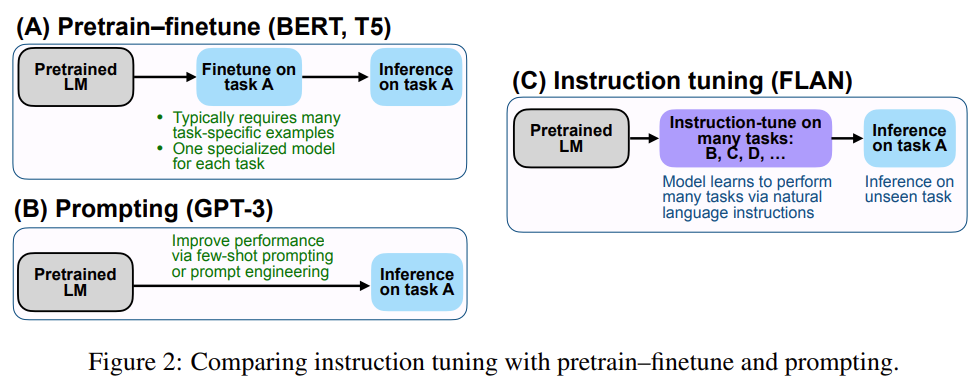
Prompt-Tuning、Instruction-Tuning和Chain-of-Thought是近几年十分流行的大模型训练技术,本文主要介绍这三种技术及其差别。