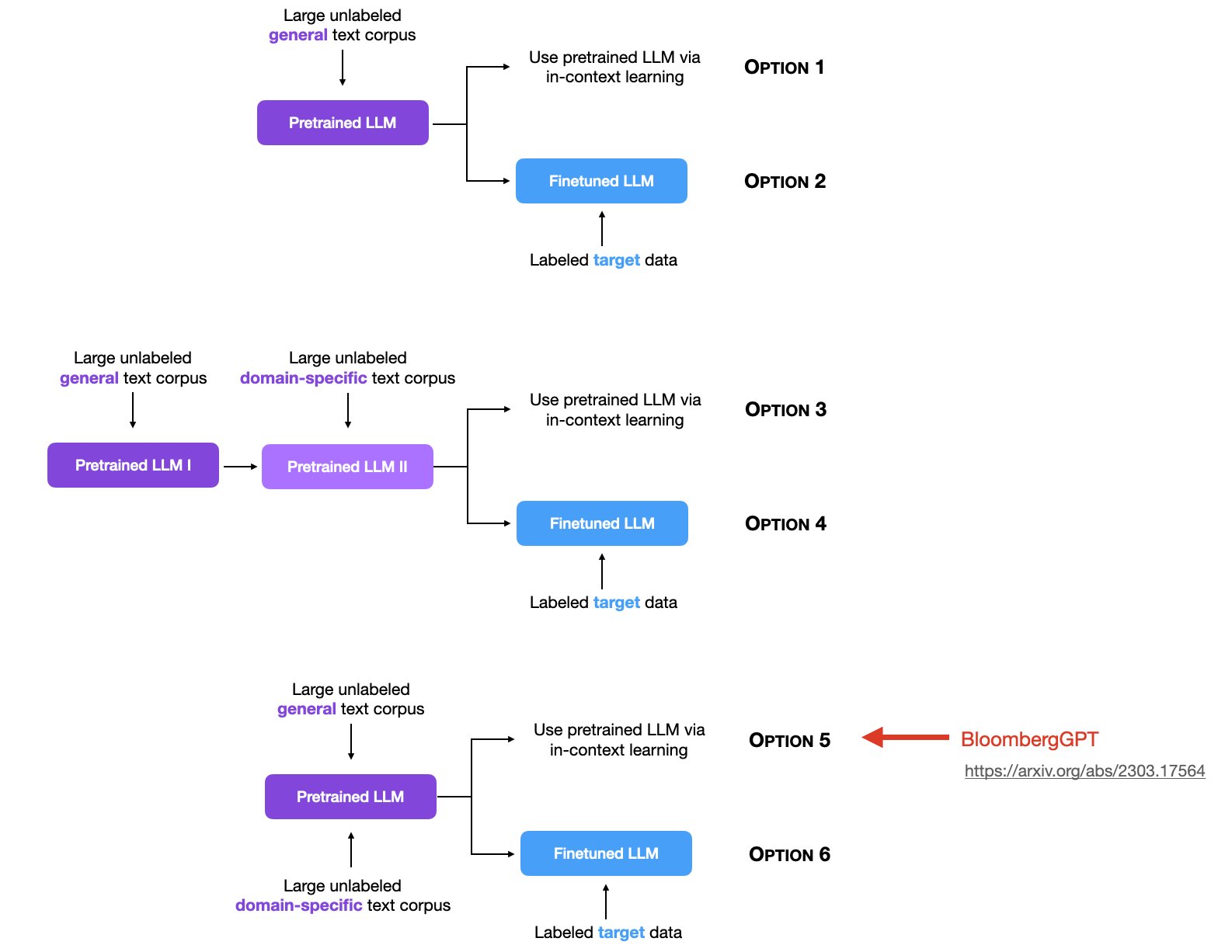
6种大模型的使用方式总结,使用领域数据集持续做无监督预训练可能是一个好选择
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的简介,也贡献了许多有价值的内容。在最新的一期统计中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于使用领域数据集做无监督预训练是目前讨论较少,但十分重要的一个方向。
汇总「大模型预训练」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的简介,也贡献了许多有价值的内容。在最新的一期统计中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于使用领域数据集做无监督预训练是目前讨论较少,但十分重要的一个方向。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。