6种大模型的使用方式总结,使用领域数据集持续做无监督预训练可能是一个好选择
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的见解,也贡献了许多有价值的内容。在最新的一期推文中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于领域大模型的一些争论引起了DataLeanerAI的注意,也可能是当前一个广受关注的大模型路线,即使用领域数据集做无监督预训练是否有前途。

本文将先简单介绍一下这6种大模型的使用方式,然后就其中的领域大模型做进一步讨论。
6种大模型的使用方法简述
简单来说,Sebastian Raschka将大模型的使用分为2个阶段,一个阶段是预训练阶段,另一个阶段是使用阶段(有监督微调/上下文学习)。前者当前有3种范式,后者有2种范式,组合之后有6种情况,就是下图的6个选项。
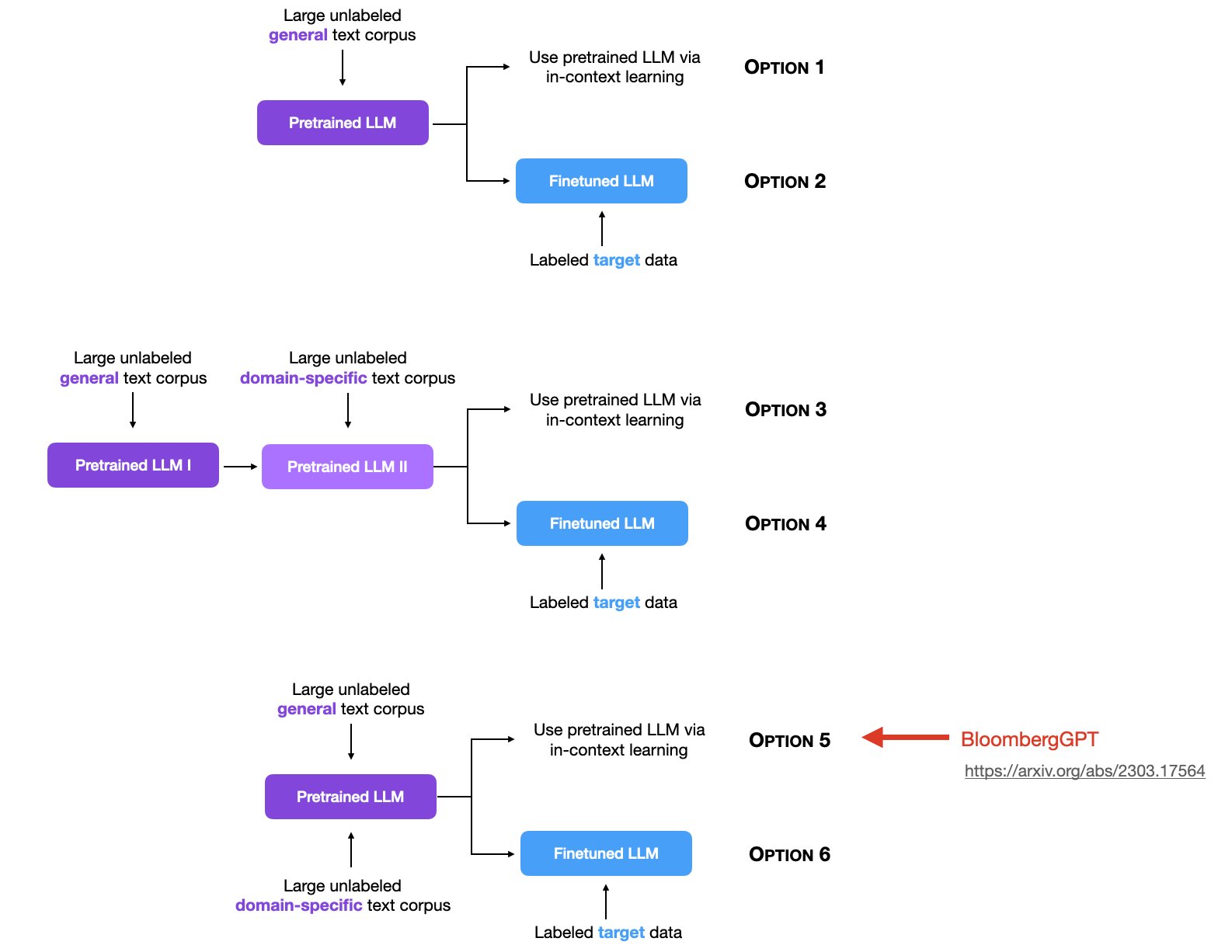
预训练的目标是让大模型学习通用知识,提高模型在广泛任务和数据上的泛化能力(即见更多更广的数据),而后续使用则是针对目标任务进行上下文学习或者是有监督微调。
大模型的2种使用方式
我们先简单描述一下大模型的2种使用方法。在ChatGPT爆火之后,大模型已经是当前技术领域最火爆的话题。与传统机器学习算法不同的是,大模型因为训练成本和强大的能力导致了两种新的使用方法,即In-context learning(上下文学习)和Fine tuning(微调)。
上下文学习(In-Context Learning)
简单来说,大模型因为本身已经有了非常强的能力,可以完成很多任务。即使是在训练过程中没有遇到过的任务,也可以通过一种叫做In-context Learning的方式完成。这种技术使得模型能够在没有改变自身参数的情况下,通过阅读和分析输入的上下文来适应和执行特定的任务。
想象一下,你有一个会讲故事的朋友,他记得全世界所有的故事。如果你给他一些故事的开头,他就能根据这个开头告诉你故事的后续发展。这就有点像大模型的上下文学习。
大模型就像那个记忆力超群的朋友,他通过阅读网上的大量文章、书籍、对话等内容来“预训练”,学习了很多关于语言和世界的知识。这个过程让模型理解了语言是如何工作的,比如单词是什么意思,怎样组合成句子,句子怎样连贯地组织成段落。
现在,当你给这个模型一段文字时,它会用它之前学到的知识来理解这段文字,并基于这个上下文生成回答。因为它已经学习了大量的文本,所以它能够理解不同的话题和风格,甚至能够模仿它们。
当前我们说的提示工程(Prompt Engineering)就是利用大模型强大的上下文学习能力,通过调整输入来提高大模型的输出效果。
微调(Fine Tuning)
而微调则是另一种大模型使用方式。即使大模型有很强的上下文学习,但也不是可以解决所有目标任务,对于一些非常具有领域特征的任务来说,使用领域有标注数据对大模型进行微调则是另一种高效的方式。与上下文学习不同的是,微调会改变大模型的参数。通过微调,模型在保留了通用语言处理能力的同时,还获得了处理特定任务的能力。这就像篮球运动员已经懂得篮球的基础,但通过特别训练,他们可以在特定的技能(如三分球)上变得更加专业。
大模型的3种预训练方式
大型语言模型的预训练是一种使用大量数据对模型进行训练的过程,目的是使模型能够理解和生成自然语言。大模型之所以可以通过上下文学习和微调获得强大的性能,也是因为预训练阶段学习了大量的知识。
当前主流的大模型预训练都是在大量的无标注数据集上,通过预测下一个token来完成超大规模预训练。在动辄几千万几万亿tokens的数据集上做预训练,是不可能通过人工标注的方式完成的。所以都是做的无监督预训练。
Sebastian Raschka根据当前主流的大模型预训练过程,将当前的大模型预训练阶段分为三种情况。分别是1)无标注通用数据预训练;2)先做无标注通用数据预训练,在此基础上继续使用领域无标注数据预训练;3)通用无标注数据与领域无标注数据混合预训练;
无标注通用数据预训练
这也是最早大模型预训练使用的方法。包括GPT-3/GPT-4、LLaMA1/LLaMA2系列等。都是通过收集大量无标注的通用数据集,使用transformer架构的模型进行预训练得到。预训练结果的模型已经足够强大,然后大家就使用这样的预训练结果做上下文学习使用或者针对特定任务微调。
这里特定任务微调包括针对聊天进行对话优化或者是针对特定任务做指令优化。这应该也是目前最主流的大模型预训练方式。
先做无标注通用数据预训练,再做领域无标注数据预训练
这也是训练领域大模型常用的方法,如EleutherAI提出的LLEMMA大模型,就是将Code LLaMA模型继续在大量的科学、数学领域的数据集上进一步做无监督预训练得到的。结果显示,这样训练得到的模型在GSM8K任务上是原始CodeLLaMA成绩的3倍,在MATH评测上的4倍。
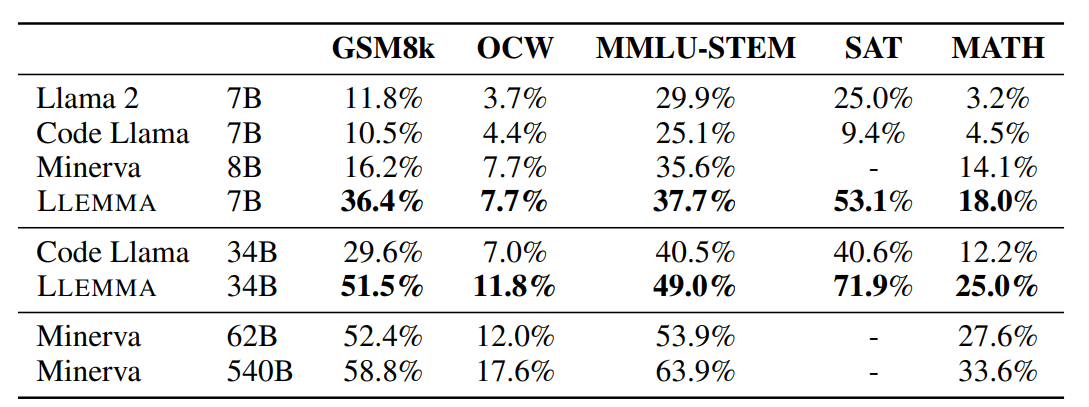
需要注意的是,这里是一个顺序预训练,即先在通用数据集上预训练一个大模型,再在特定领域的无标注数据集上进一步预训练。
通用无标注数据与领域无标注数据混合预训练
这是另一种思路,与第二种顺序预训练不同。这是只做一次预训练过程。但是在一开始就把通用数据和特定领域的无标注数据混合在一起。这个训练方式最有名的就是彭博社发布的BloombergGPT。
BloombergGPT是2023年4月份由彭博社发布的金融领域大模型,参数规模500亿,但是在7000亿tokens数据集上预训练得到。其中金融领域数据约3630亿个tokens。这已经是非常早的领域大模型了。而且方式也非常独特,在预训练阶段就把通用数据和领域数据混合(详情参考:https://www.datalearner.com/blog/1051680353668306 )
领域数据该怎么用?领域数据无监督预训练vs领域数据有监督微调
可以看到,这里的划分方法主要区别在于预训练阶段是否使用领域无标注数据集,以及如何使用领域无标注数据集。
不管是按顺序的预训练(即先做通用数据预训练再做领域数据预训练)还是用混合数据预训练,这可能都不是当前最主流的方法。
在当前主流的领域大模型训练路线中,大多数的领域模型都是使用通用大模型+领域有标注数据集来微调得到的。微调需要的数据量相对更少。根据经验(仅仅是经验),单个任务的微调通常只需要几千条有标注数据即可。原因是微调的主要目标是识别指令,对齐目标。而非学习领域知识。但是,领域数据有监督微调通常是教会模型在特定领域执行特定任务,如医疗文本分类、法律文件分析等。模型能够学习如何精准地执行任务,理解特定领域内的语言和术语。但是任务必须非常具体,且有高质量的标记数据可用时才合适。
前面已经说过,无监督预训练的目的是让大模型学习更广泛的数据,因此需要大量的领域数据才合适。领域无监督数据可以增强模型对特定领域语言和知识的整体理解。当需要模型对特定领域有广泛的理解,但没有具体的任务目标时。这是非常合适的方式。
二者对比如下:
领域数据无监督预训练的发展
而根据当前的模型技术的发展,通用数据无监督预训练的模型在少量有监督微调下有了非常大的发展。BloombergGPT当初花费数百万美元训练,其结果在金融领域表现也非常好。然而,半年后,AdaptLLM-7B仅仅花费100美元,其金融领域评测的平局分已经超过了BloombergGPT了。如下图所示:
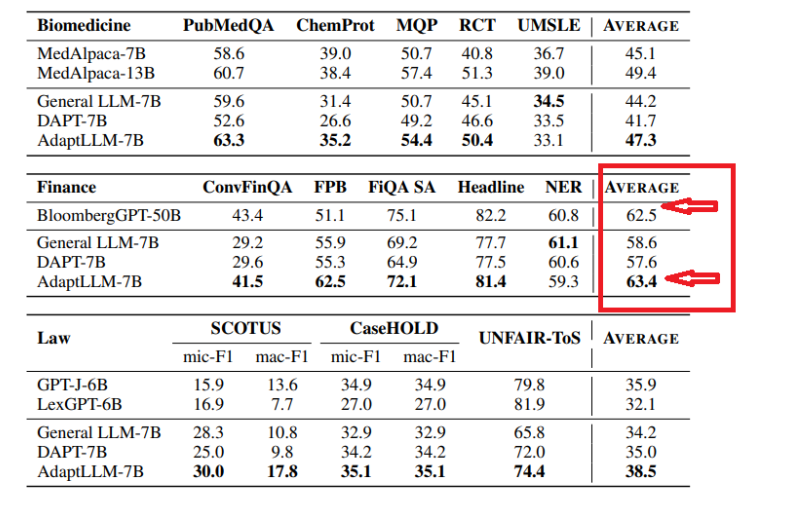
不过,从实际的对比来看,AdaptLLM-7B只是在FPB得分很高,实际评测中BloombergGPT依然在其它三个金融任务上领先。AdaptLLM-7B是在通用无监督数据集基础上,继续使用领域数据无监督持续预训练的方法。
尽管在领域进行有监督微调是一种方法,但持续预训练提供了一种更具灵活性和广泛适用性的方法。也应该是大家关注的重点。即如何不降低通用能力的情况下,提高领域数据无监督预训练的效果,可能是未来非常有效的领域大模型的发展方向。
