抛弃Spark?Flink会是下一代大数据计算引擎吗?
Apache Spark是目前应用最广泛、最流行的大数据计算平台之一,在2.X版本中,Apache Spark已经开始摒弃RDD的数据模型,采用Spark SQL的Dataset作为统一的数据模型来构建更加高效的计算框架。然而,2015年成为Apache顶级项目的Apache Flink却被很多人认为是未来最有可能取代Spark的新一代大数据计算引擎。本文将简单介绍二者的区别以及为什么会有这种说法。
Spark的流行除了本身是一个很优秀的框架外也有一些大数据生态的因素。众所周知,虽然MapReduce框架开启了大数据批处理的时代,但是因为自身的限制导致编程的灵活性受到很大影响,而Spark一开始采用的RDD数据模型则有更加高效灵活的编程方式,并且支持内存计算,这使得Spark更受欢迎。
除此之外,还有个重要的因素是在大数据生态的多样性。之前,包括批处理、实时处理、SQL查询、交互分析等,在大数据生态中都有各自的一套组件,每一个应用场景都有着好几种可替代的技术方案,但正常情况下,实际应用的场景都相对比较复杂,因此,构建一个适合自己业务场景的大数据引擎通常面临着很多的技术方案,不同的方案优缺点不同,因此,构建一个完整的支撑业务场景的大数据引擎也要使用多种种技术,这导致了很多问题:如技术学习曲线陡峭、开发和运行效率低下、运维的困难等。
而Spark从一开始就使用一个统一的引擎进行批处理、流处理、交互分析等,使得应用价值大大提高。

尽管Spark在批处理上有很大优势,但是在流处理方面依然有很大的缺陷。首先,Spark Streaming是准实时的,它处理的方式是微批处理模型。在动态调整、事物机制、延迟性、吞吐量等方面并不优秀。但是由于Spark位于Spark生态中,它可以很好的与其他应用结合,因此使用的人也不少。
然而越来越多的公司发现,很多场景需要对流数据进行处理,流数据处理的价值也越来越高。如网络故障检测、欺诈行为检测等。这些问题使用流处理将有更高的价值。这就是Flink的机会。
Apache Flink是一个分布式处理引擎,用于对无界和有界数据流进行有状态计算。 Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。可以说,它为流处理而生。
Apache Spark和Apache Flink的主要差别就在于计算模型不同。Spark采用了微批处理模型,而Flink采用了基于操作符的连续流模型。
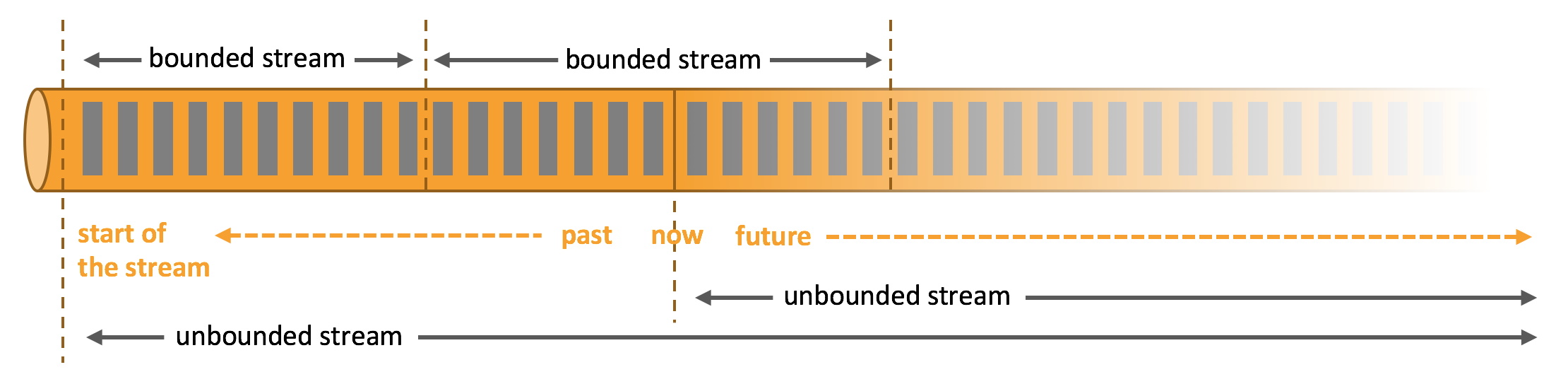
Flink 的基本数据模型是数据流,及事件(Event) 的序列。数据流作为数据的基本模型可能没有表或者数据块直观熟悉,但是可以证明是完全等效的。流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,这样就是批处理。
而Spark现在也提供了Structured Streaming Programming,目的也是要和Flink竞争,防止被踢出局。同样的,有Spark的经验,Flink也提供了多个基于统一框架的高层次组件。

由于流处理在应用的场景越来越多,而Flink在流处理上的优秀表现使得很多公司也开始采用这个计算引擎。由于Flink也提供了类似Spark的SQL/ML等组件,因此有人认为Flink是下一代大数据计算引擎。然而,随着Spark在流上的处理,也未必见得Flink就能赢。从Google Trends上看二者的趋势,Spark目前仍然远比Flink受欢迎的多。其社区也更加活跃。但Flink的处理方式也有很多值得借鉴的地方。而且阿里巴巴也是Flink社区的活跃者,也在自己的业务上运行Flink,并做了一个基于Flink的Blink框架。值得大家尝试。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
