Spark之RDD、Dataset和DataFrame
一、Dataset简介以及与之前的数据集区别
Spark的最早使用的数据集是RDD(弹性分布式数据集,Resilient Distributed Dataset)。它是Spark对数据的一种抽象,是一种数据结构。
从一开始RDD就是Spark提供的面向用户的主要API。从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层API进行并行处理。
与RDD相似,DataFrame也是数据的一个不可变分布式集合。但与RDD不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样。设计DataFrame的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。它提供了特定领域内专用的API来处理你的分布式数据,并让更多的人可以更方便地使用Spark,而不仅限于专业的数据工程师。
借用网上的一组图:
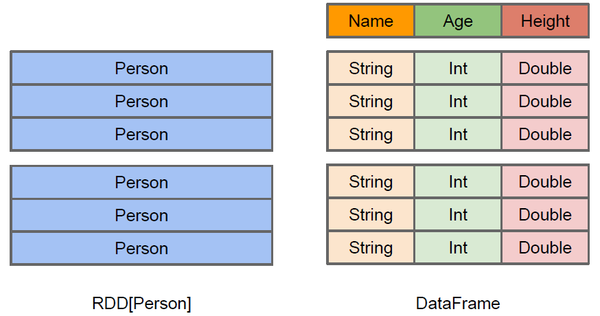
我们可以看到,其实DataFrame相比较RDD能更了解数据内部的结构。
从Spark2.0开始,Spark整合了Dataset和DataFrame,前者是有明确类型的数据集,后者是无明确类型的数据集。根据官方的文档:
Dataset是一种强类型集合,与领域对象相关,可以使用函数或者关系进行分布式的操作。每个Dataset也有一个无类型的试图,叫做DataFrame,也就是关于Row的Dataset。简单来说,Dataset一般都是Dataset[T]形式,这里的T是指数据的类型,如上图中的Person,而DataFrame就是一个Dataset[Row]。
关于Dataset的优点其实主要是执行效率更高,运行时类型安全。可以参考InfoQ的翻译文章: 且谈Apache Spark的API三剑客:RDD、DataFrame和Dataset
因此,以后Spark的数据集操作都可以统一成使用Dataset。Dataset包含两种操作,一种是转换操作(transformations),一种是活动?操作(actions)。转换操作是产生一个新的Dataset,而actions操作则是出发一个计算并返回结果。转换操作包括如map、filter、select以及aggregate(groupby)。actions则包括count、show或者将数据集写入文件。
Datasets是懒加载的,即只有actions被调用的时候才会触发计算。在内部,Dataset代表一个逻辑计划,用来描述产生数据需要的计算。当一个action被调用的时候,Spark的query优化器会优化这个逻辑计划并以分布式的方式在物理上进行实际的计算操作。想要了解逻辑计划以及优化的物理方案,可以使用explain函数查看。
有两种创建Dataset数据集的方式,一种是读取文件,一种是通过转换操作:
// 读取
val people = spark.read.parquet("...").as[Person] // Scala
Dataset<Person> people = spark.read().parquet("...").as(Encoders.bean(Person.class)); // Java
// 转换
val names = people.map(_.name) // in Scala; names is a Dataset[String]
Dataset<String> names = people.map((Person p) -> p.name, Encoders.STRING));
二、Encoder
这里还介绍一个Encoder概念。Encoder是用来支持Dataset的领域对象的,我们知道,Dataset中的每一行可以当做一个Bean,这是需要Encoder来支撑的。它的作用是把领域对象T变成Spark内部的类型系统。例如,给定一个类Person,它包含两个字段一个是name(string)一个是年龄age(int),那么一个encoder用来告诉Spark在运行时产生一些代码,将Person对象序列化成一个二进制的结构。在Scala中,Encoder会被自动计算,而Java中则要显示制定Encoder对象。如:
val people = spark.read.parquet("...").as[Person] // Scala
Dataset<Person> people = spark.read().parquet("...").as(Encoders.bean(Person.class)); // Java
Encoder是Spark SQL中序列化和反序列化最基本的概念。 Encoder特征:
trait Encoder[T] extends Serializable {
def schema: StructType
def clsTag: ClassTag[T]
}
进一步的,这里的类型T代表一条记录的类型,同时可以被Encoder[T]处理。一个T的encoder类型即Encoder[T]是用来将任意JVM对象或者原始类型和Spark SQL的内部行(这是一个二进制的行形式)相互转换的。
三、Dataset操作
接下来我们说一些关于Dataset的典型操作。
3.1、Actions
Actions操作是对数据进行计算,主要的操作如下:
1、返回指定行的操作collect()、collectAsList()、takeAsList(n)和toLocalIterator() 这个操作是将Dataset变成一个数组或者列表。也就是数据结构的转换了。前面两个是返回所有的数据,第一个返回一个数组,第二个返回一个列表,里面的一个元素就是一个T(之前说的一个对象)。takeAsList是返回前n行数据成一个列表。最后一个toLocalIterator返回一个迭代器,可以循环得到所有数据
2、take()、take(n:Int)、head()、head(n:Int)和first() 这几个操作都是返回前几行数据的操作。其中take操作和head操作完全一样(不知道为啥定义两个方法,有人说是为了和pandas对齐),没有参数默认返回第一行,有参数n返回前n行。而first()直接返回第一行。
3、show() show相关的操作就是展示数据,以表格的形式展示数据,可以指定行数
4、统计相关的summary()和describe() 这两个操作都是统计相关的操作,前者是返回字符列和数值列的统计信息,后者是返回指定列的统计结果(包括行数、均值、方差、最大值、最小值)。
3.2、转换操作
转换操作主要包含两类,一种是有类型的转换,一种是无类型的转换。有类型的转换操作是Dataset的API,用来对带有Encoder的Dataset做转换,但是不包含RowEncoder。
2.2.1、有类型的转换
1、换名字方法alias(alias: Symbol)、alias(alias: String)、as(alias: Symbol)、as(alias: String) 这个其实就是给数据集换个名字
2、去重操作distinct()、dropDuplicates(col1: String, cols: String*)、dropDuplicates(colNames: Array[String])、dropDuplicates(colNames: Seq[String])、dropDuplicates() 可以去除重复数据,如果给了列的参数,那么就只考虑给定列名的重复结果。
3、两个数据集之间的操作 except(other: Dataset[T]):返回一个数据集,只包含当前数据集的行,但是不包含给定数据集的行,相当于java中list.removeAll(list1) intersect(other: Dataset[T]):返回一个数据集,在两个数据集中都包含的行 joinWith[U] (other: Dataset[U], condition: Column):按照指定的列与其他数据集做连接操作 joinWith[U] (other: Dataset[U], condition: Column, joinType: String) union(other: Dataset[T]):把两个数据集加到一起,相当于在第一个数据集后面增加行,因此需要列相同 unionByName(other: Dataset[T])
4、筛选操作 filter()、where() 都一样的,没啥区别
5、选择操作 select() 可以选择而某些列
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
