大模型速度、效果与价格的完美结合?xAI发布Grok 4 Fast:性能接近Grok 4,成本降 98%,生成速度翻倍!
603 views
加载中...
Follow DataLearner WeChat for the latest AI updates


Grok 4 Fast最高支持200万tokens上下文,一个模型支持推理和非推理两种模式。Grok 4 Fast也是一个多模态大模型,支持文本和图片的输入,目前只支持文本的输出。
在过去几年里,大型语言模型的升级路径几乎都围绕着“更大、更强”展开。参数量、训练数据和推理深度不断增长,性能确实提升了,但代价也同样惊人:高昂的计算成本、庞大的延迟,以及对用户端不可忽视的价格压力。
Grok 3 Mini 尝试过提供轻量化替代方案,但在复杂推理任务中仍存在明显差距。Grok 4 则是旗舰级选择,表现顶尖,却意味着昂贵的成本和较高的门槛。
Grok 4 Fast 正是为打破这一“性能与成本的悖论”而生。 它通过大规模强化学习策略,最大化了所谓的“智能密度”——即在相同的推理步骤中产生更高质量的思维链,从而用更少的计算实现更优的结果。
换句话说:同样的题,别人要写两页草稿才能解出来,Grok 4 Fast 只需要半页,却正确率相同。
从公开测试数据来看,Grok 4 Fast 的竞争力几乎可以用“压倒性”来形容。主要是其价格太低,速度太快,但是效果很好。
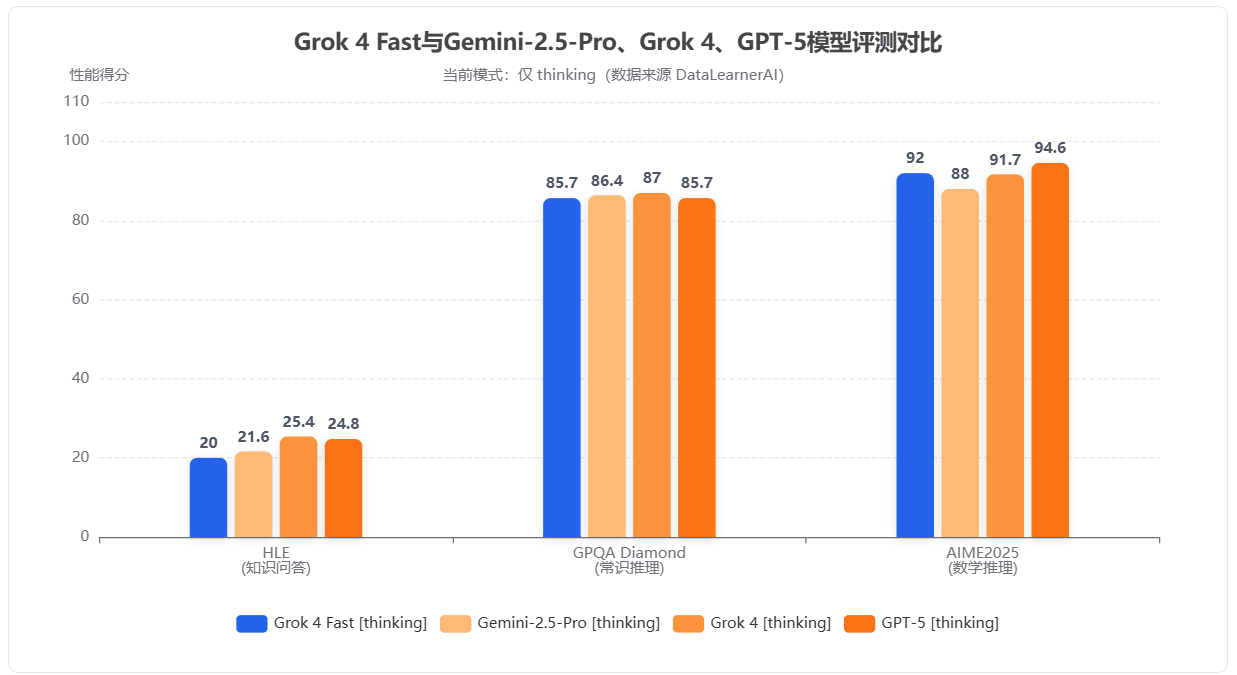
首先我们看一下Grok 4 Fast在不同评测集的效果。
与当前主流的Fast版本模型不同,当前大多数模型的Fast版本都是量化或者更小参数规模版本。因此性能损失都是比较明显的。然而,Grok 4 Fast似乎不太一样。它在某些测试结果上,甚至好于Grok 4的结果。在 AIME 2025 数学竞赛数据集上,它取得 92.0% 的正确率,超过了 Grok 3 Mini 的 83.0%,略高于旗舰 Grok 4(91.7%)。而且其它评测与主流模型相比也基本没有差别。
但是,上述评测结果不是最重要的,最重要的是Grok 4 Fast模型的推理速度和价格。首先,我们看一下推理速度对比:
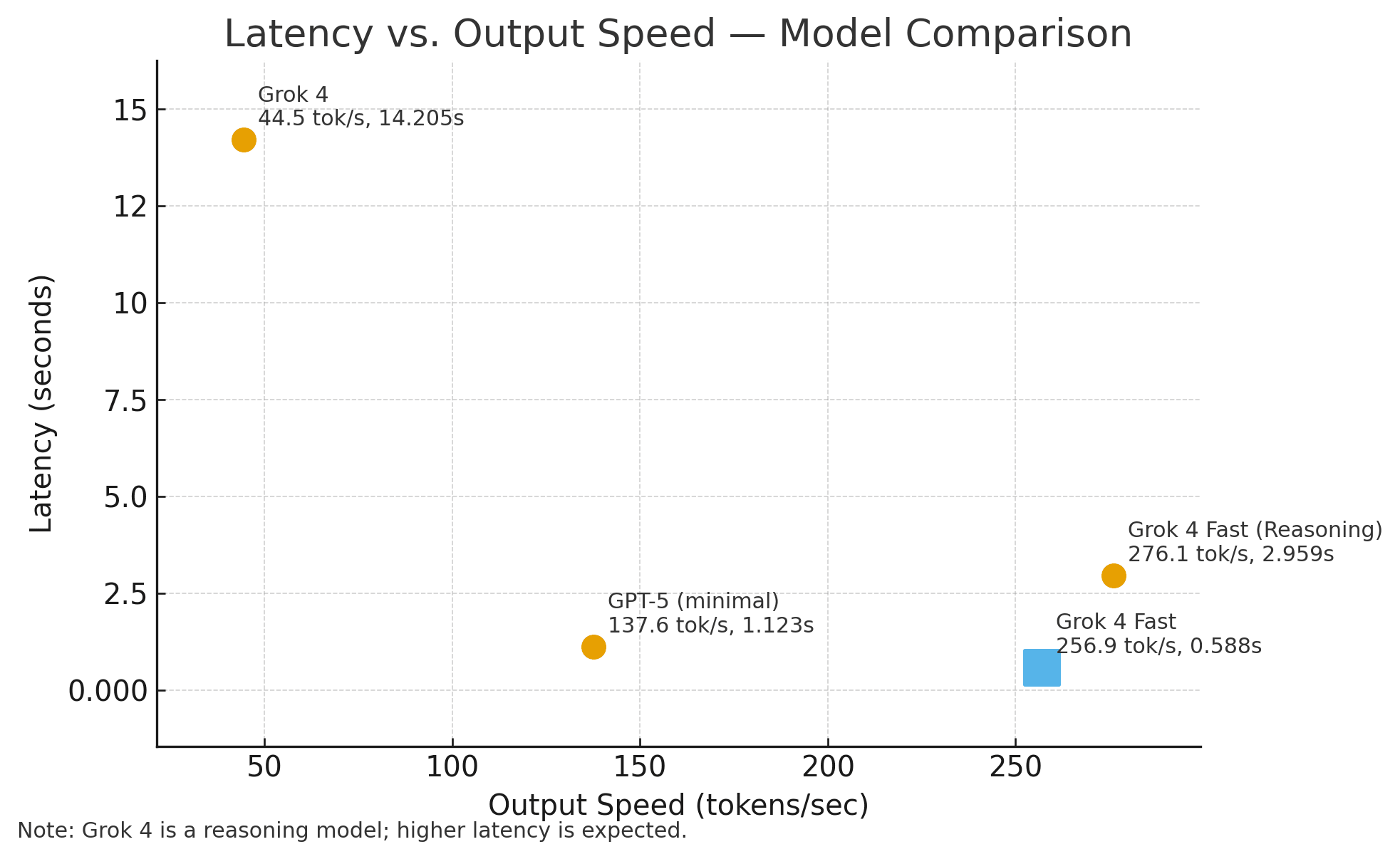
该数据来自Artificial Analysis。从上图我们可以看到,Grok 4 Fast在响应延迟(Latency)上表现出色,首字符时延仅0.588秒左右。而其输出速度(OutputSpeed)极快,达到了250 tokens/y以上,远超Grok 4和GPT-5。这个速度实在是让人惊喜!而Grok 4的推理速度只有44 tokens/s左右。
除了推理速度外,Grok 4 Fast也强调了其“智能密度”,即Grok 4 Fast可以以更少的tokens数获得相同的效果。如下图所示:
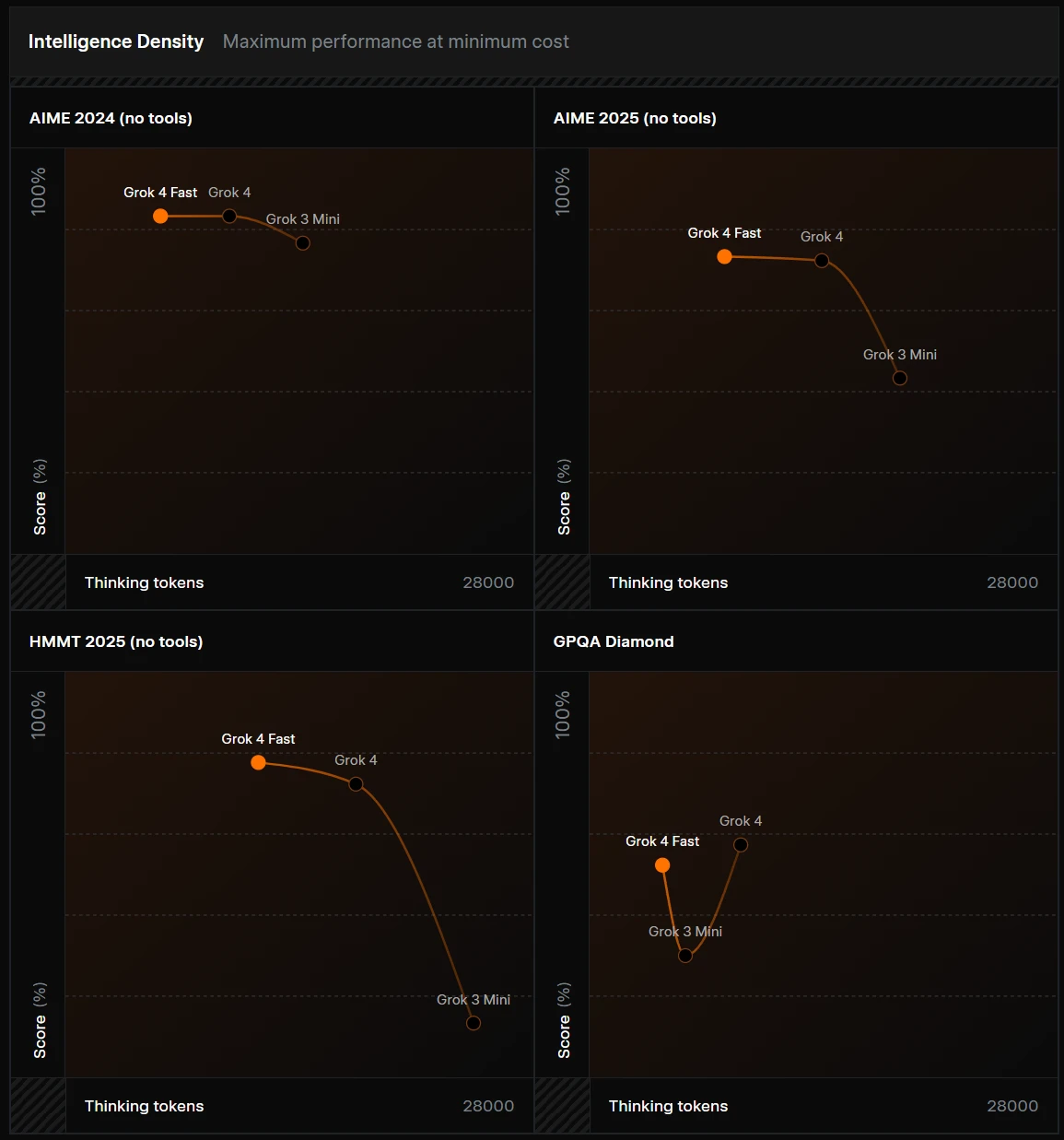
根据官方的数据,Grok 4 Fast可以使用比Grok 4少40%的tokens数获得差不多水平的结果!这样的知识密度不管是对价格还是推理速度来说都非常有益!
此外,xAI还将Grok 4 Fast价格下调了90%以上,如下图所示,我们展示了Grok 4 Fast价格相比主流最强模型的对比:
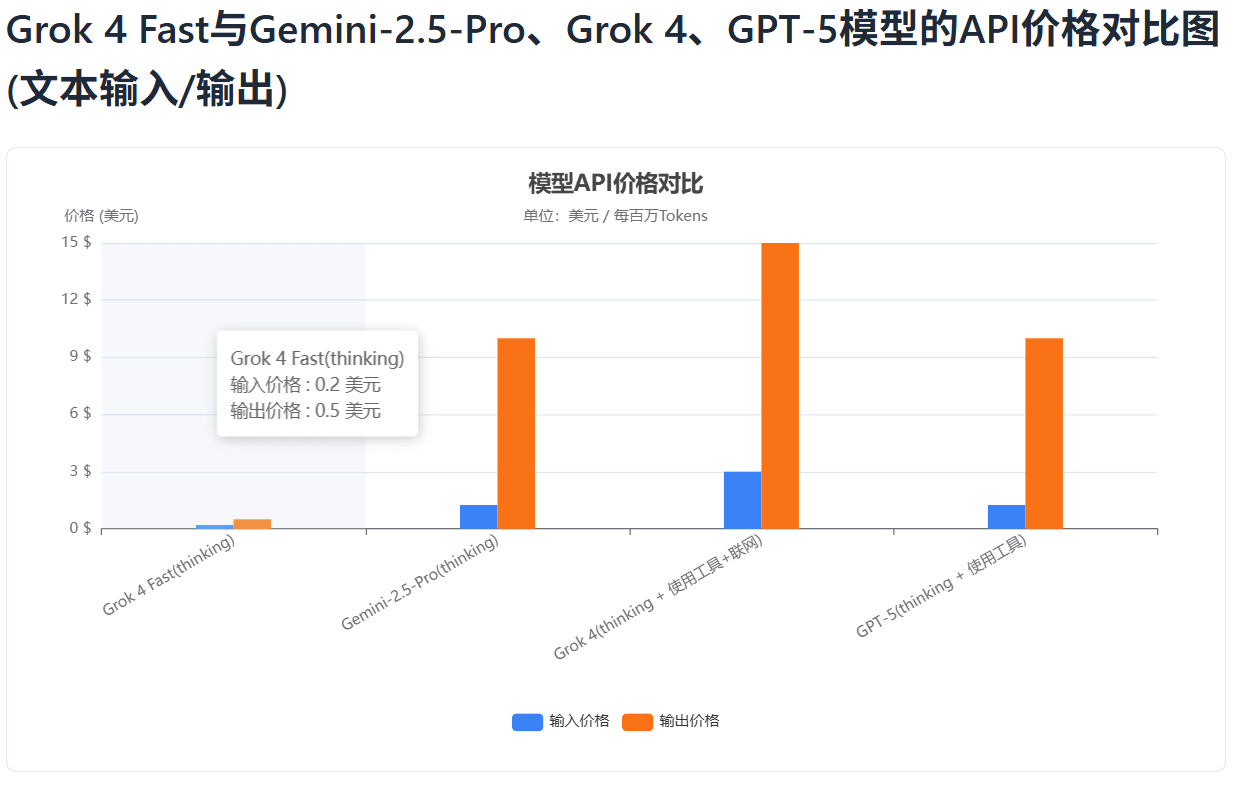
与 Grok 4 相比,Grok 4 Fast 在定价上实现了断层式下调:
而根据独立机构 Artificial Analysis 的评测,Grok 4 Fast 在 智能价格比(price-to-intelligence ratio) 上实现了业界最佳表现——与 Grok 4 相比,同等性能的价格下降幅度高达98%。
更直观地说:如果把达到同样智能水平的运行成本定为 100 美元,Grok 4 Fast 只需要 2 美元。
Grok 4 Fast 是首批经过端到端工具使用强化学习训练的模型之一,能自主决定何时调用浏览器或代码执行工具。
它的搜索能力尤其突出:
具体案例:当被问到“Path of Exile 2 升到满级需要多少经验值”时,Grok 4 Fast 会自动检索 Reddit、Wiki、PoE2 数据库,综合信息后给出 4,250,334,444 点经验 的精确结果。
这意味着,它不仅能“知道答案”,还能“找到答案”。
在行业里早已形成一种“默认”:大模型的输出价格,通常是输入价格的 5–10 倍,这并不只是“想多赚”,而是由技术开销与商业治理共同决定的。而 Grok 4 Fast 把这个倍数拉到了 2.5 倍——这并不常见,也很值得单拎出来讨论:它既可能反映了底层技术路径的变化,也可能传递出清晰的商业策略信号。
当前大模型的主流技术架构的输出是自回归生成,每产出 1 个 token,都要跑一遍完整前向计算,并依赖前文上下文;而输入多为一次性并行编码。结果是生成阶段的并行度更低、时延更高、算力利用更难做满。因此输出价格会贵很多。
Grok 4 Fast 把输出/输入倍数压到 ≈2.5,明显低于行业常态。这就有意思了。我们可以做两个层面的合理猜测(不代表官方结论):
技术猜测:把“每个输出 token 的隐性后台成本”降下来了
商业猜测:用“低倍数”去重塑谁来用、用来做什么
当然,并不是所有这些策略都是单位输出token成本的降低,可能是综合原因。
Grok 4 Fast 已经面向所有用户全面开放。
普通用户:
此外,OpenRouter上线了免费的接口服务,可以直接访问:https://openrouter.ai/x-ai/grok-4-fast:free 获取。不过,这个接口达到速度似乎只有150 tokens/s。
关于Grok 4 Fast更多的信息以及详细的评测结果参考:https://www.datalearner.com/ai-models/pretrained-models/Grok-4-Fast
Grok 4 Fast和其它模型的对比可以参考DataLearnerAI大模型对比工具:https://www.datalearner.com/compare/result?modelInputString=677,611,626,578&benchmarkInputString=&mode=thinking-only