阶跃星辰StepFun开源激活参数只有11B的Step-3.5-Flash模型,但是评测结果和Kimi K2.5、Qwen3-Max-Thinking差不多,最高推理速度可以达到350tokens/s!
576 views
Stepfun AI(阶跃星辰)正式发布了其最新开源基础模型StepFun-Flash-3.5。这款模型以“快速、锐利、可靠的 agentic 智能”为核心设计,采用稀疏混合专家(Sparse MoE)架构,总参数量 196B,但每 token 仅激活 11B 参数,实现高效推理的同时保持前沿级性能。它支持 256K 超长上下文、多 token 并行预测(MTP-3),推理速度可达 100-300 token/s,甚至在编码任务中峰值 350 token/s。

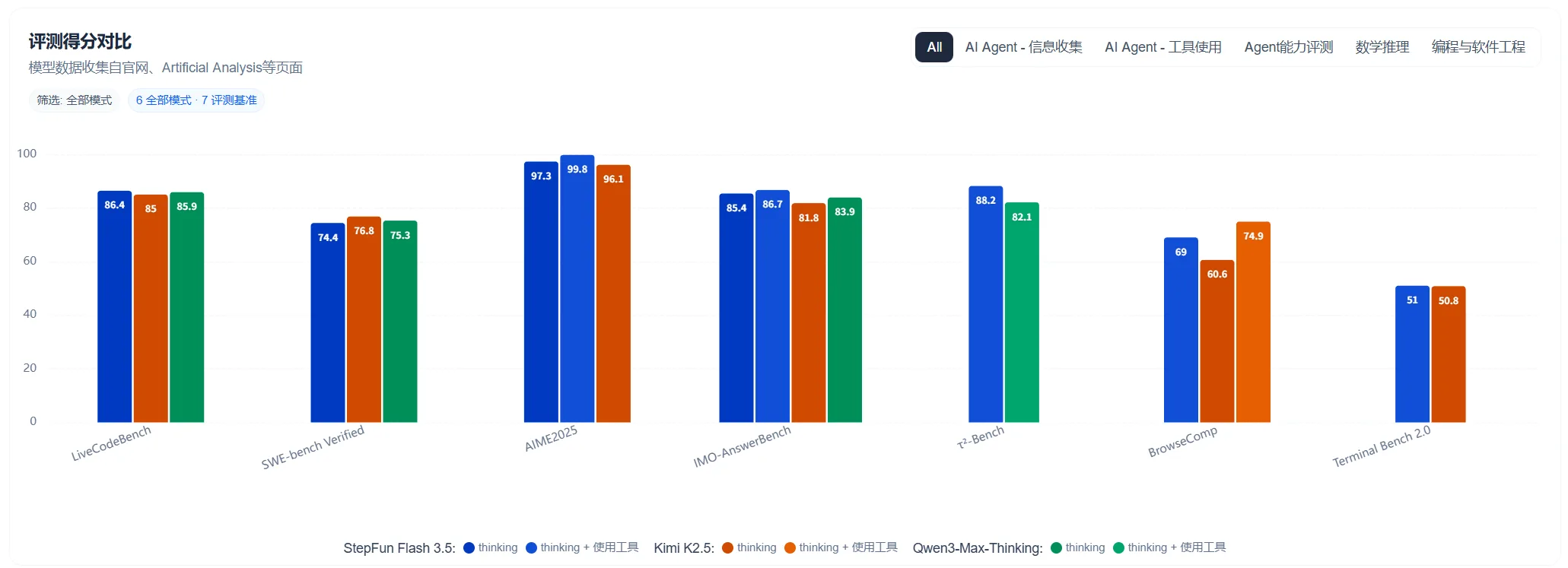
作为一款专为智能体(Agent)场景优化的开源模型,StepFun-Flash-3.5 一发布便在多个 agentic 和编码基准上表现出色,有很多人测试反馈速度非常出色,性能表现也很亮眼。
对比当前国内另外两个刚发布不久的最强模型(以下简称 Kimi K2.5)和, 在多项任务上接近或超越,但在资源占用和推理速度方面占据绝对优势。