探索 OSWorld Verified:大模型AI Agent在真实计算机任务中的评估框架
OSWorld 是一个用于测试 AI 代理在真实计算机环境中的基准。这些代理是能处理文字、图片等信息的 AI 系统。基准包括开放式任务,比如操作文件或使用软件。OSWorld Verified 是它的改进版,通过修复问题和提升运行方式,提供更准确的测试结果。它支持不同操作系统,如 Ubuntu、Windows 和 macOS,并允许 AI 通过互动学习来完成任务。
现有基准的常见问题
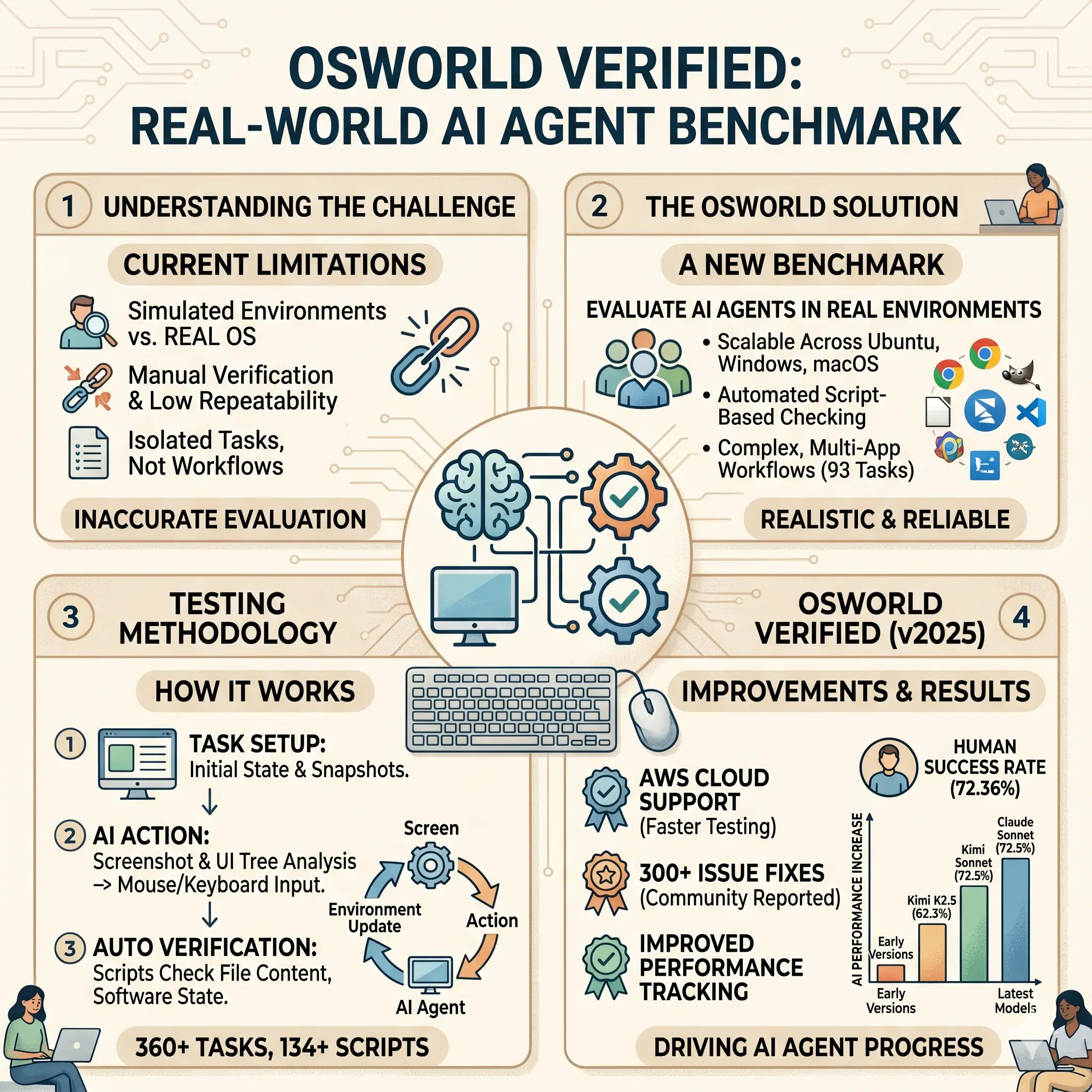
许多现有的 AI 测试基准使用模拟环境,而不是真实的计算机。这导致测试结果无法反映实际使用情况。主要问题包括:
- 模拟环境不能处理任意软件或操作系统文件。
- 测试依赖人工检查,难以重复和自动化。
- 任务只限于特定类型,忽略了涉及多个软件的复杂工作流程。
这些问题使评估 AI 在日常计算机任务中的表现变得不准确。
基准的起源与目的
OSWorld 由香港大学、销售力量研究、卡内基梅隆大学和滑铁卢大学共同开发。初版于 2024 年发布,相关论文发表于 NeurIPS 2024 会议。OSWorld Verified 于 2025 年 7 月 28 日推出,添加了 AWS 云服务支持,以加快测试速度,并修复了社区报告的 300 多项问题。
这个基准的目的是解决现有测试的不足,帮助评估 AI 代理在真实计算机中的能力。具体包括:
- 创建一个可扩展的环境,支持多种操作系统。
- 使用自动脚本检查任务完成情况,减少人工参与。
- 设计开放式任务,考察 AI 的界面识别、操作技能和规划能力。
测试方法与运行步骤
OSWorld Verified 使用虚拟机来模拟计算机环境。AI 代理通过查看屏幕截图和界面结构树来理解情况,然后执行动作,如鼠标点击或键盘输入。测试结果由脚本自动检查,例如验证文件内容或软件状态。
基准共有 369 个任务(如果排除 8 个需要网络的 Google Drive 任务,则为 361 个)。任务分类如下:
运行步骤包括:
- 使用虚拟机快照和脚本设置任务起始状态。
- AI 代理执行动作,最多 100 步。
- 脚本自动计算成功率。
- 支持本地运行或云端并行测试,通常在 1 小时内完成。
基准提供 134 个检查脚本,确保测试结果一致,并有工具供手动验证。
主流 AI 模型的表现与观察
根据 2026 年 2 月数据,部分模型在 OSWorld Verified 上的表现如下(成功率基于单次运行,最多 100 步):
人类在相同任务上的成功率为 72.36%。AI 模型的表现已从早期版本的 12.24% 显著提高。
观察显示:
- AI 在识别屏幕元素和操作软件时仍有困难,导致部分失败。
- 使用更高分辨率的截图能提高成功率 5-10%。
- 记录动作的文字历史比只用截图更有帮助。
- AI 对界面布局变化敏感,但在不同操作系统间表现一致。
其他模型如 Seed-1.8 (ByteDance) 达到 61.9%,显示通用模型在多任务处理上的优势。
基准的价值与未来
OSWorld Verified 通过真实环境和自动检查,推动 AI 代理的进步。它揭示了 AI 在任务规划和执行中的弱点,并提供数据用于改进。未来可扩展到更多操作系统和任务,支持学习方法和安全研究。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
