
模型不能停,阿里又又又又要开源新模型:Qwen3-Next-80B-A3B
继阿里刚发布Qwen3-ASR模型之后,Qwen团队又在社区提交了全新的Qwen3-Next代码。这意味着阿里即将开源Qwen3家族的新成员。这个模型最大的特点是架构变化很大,与此前Qwen系列很不一样。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
继阿里刚发布Qwen3-ASR模型之后,Qwen团队又在社区提交了全新的Qwen3-Next代码。这意味着阿里即将开源Qwen3家族的新成员。这个模型最大的特点是架构变化很大,与此前Qwen系列很不一样。
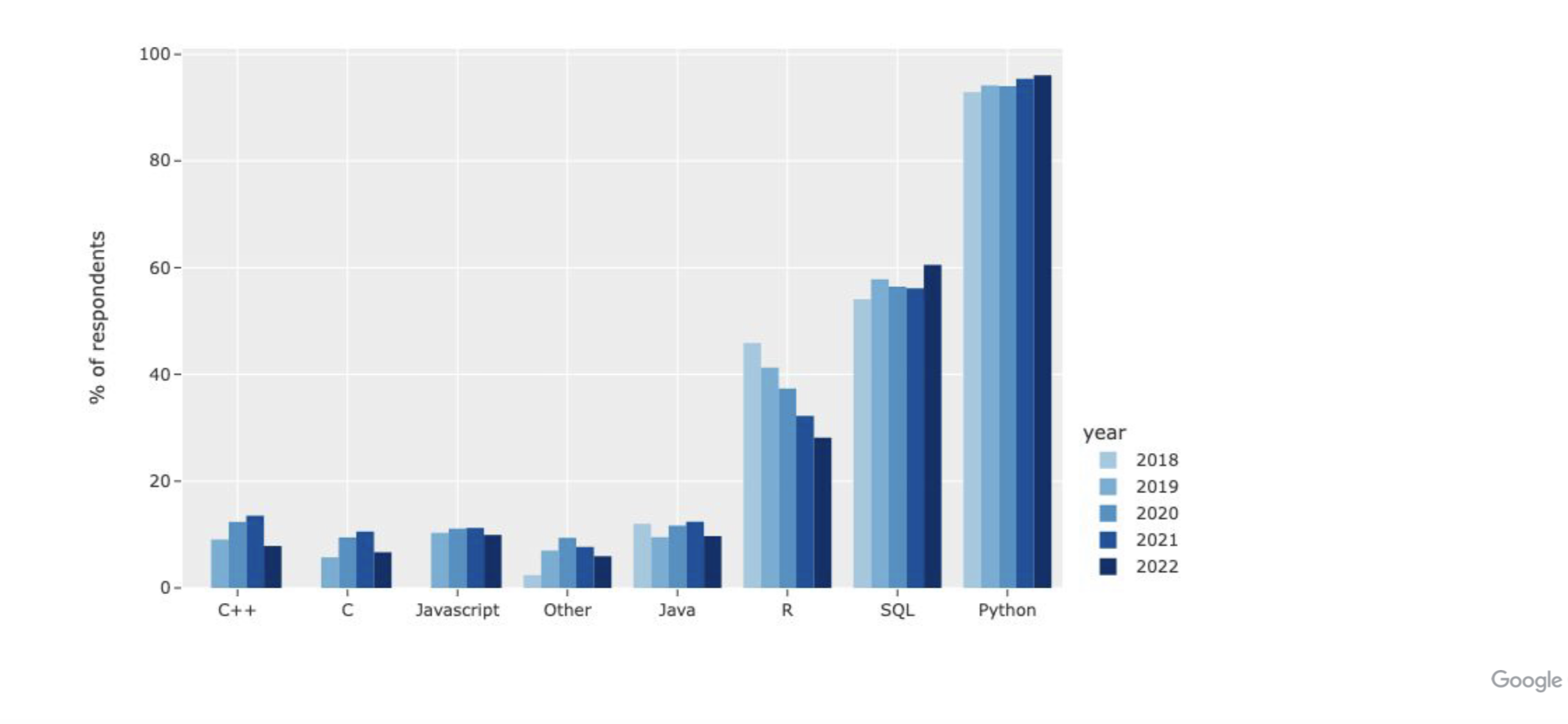
kaggle是各类机器学习竞赛的著名平台,上面聚集了大量的机器学习比赛和数据集,也有大量的数据处理相关专业人员。每年官方都会向平台用户发放问卷,调查数据科学家的工具使用和平台采用情况。今年的调查结果也在两天前发出,有很多有意思的结论。
Gemini是谷歌发布的一系列大语言模型。最早是2023年12月发布1.0版本,在2023年2月中旬,劈柴哥亲自宣布Gemini Pro升级到1.5版本。Gemini 1.5 Pro是一个全新的MoE模型(Mixture of Experts,混合专家),在各项评测结果中都接近Gemini Ultra 1.0的水平。而在今天,Gemini Pro 1.5再次迎来重大更新,包括音频理解、无限制文件阅读以及更好地指令遵从性等。本文将介绍这次更新,并做一些简单的实际测试。
恰巧,我最近发现了一个网站——Open ChatGPT,网址是 https://open-chat-gpt.com/cn。 简单来说,该网站调用 ChatGPT-4 (最新版) 的 API,让用户创建各种指定角色,服务于生活跟工作。不仅如此,还支持连ChatGPT官网都还没用上的AI画图功能。目前,相比其他网页各种限制使用次数的,这网站非常可贵在于可以无限次免费使用ChatGPT-4...
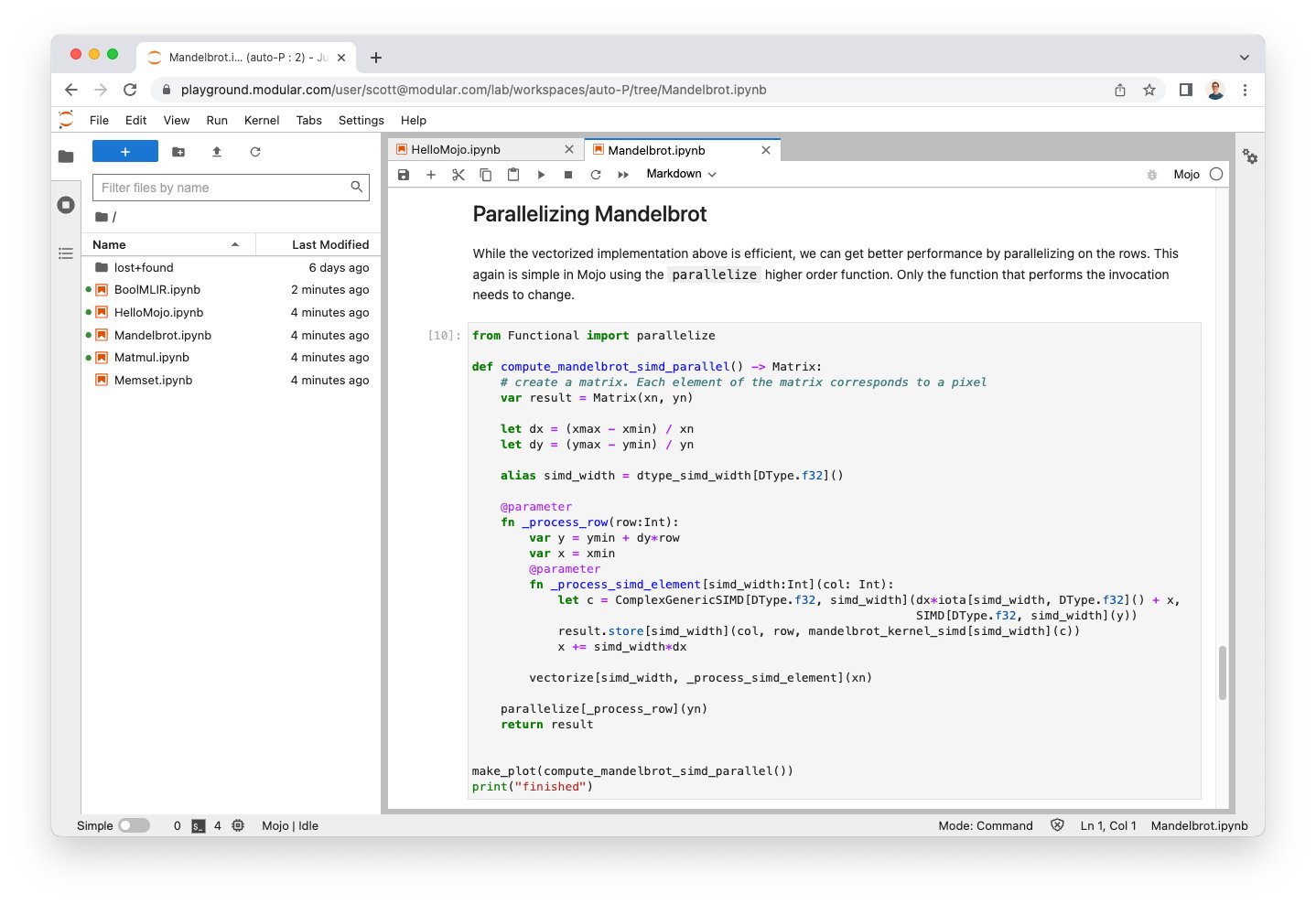
昨天,前苹果工程师、swift编程语言创建者Chris Lattner创立的ModularAI发布了一个新的编程语言Mojo。根据测试,该语言比Python最高提速35000倍!本文将简单介绍一下这个Mojo编程语言。

Sora2 的发布再次引爆了视频生成领域。你可能已经看到过一些令人惊叹的演示视频,但当你自己上手时,生成的作品可能并不尽如人意。问题出在哪里?很可能就在你的提示词(Prompt)上。

2023年3月23日OpenAI官方宣布ChatGPT即将支持Plugin模式。这是一种用插件的方式来解锁ChatGPT的能力,包括让ChatGPT可以浏览网页、从本地商店订购食材等。今天,沃顿商学院教授Ethan Mollick在推特上公布了自己收到了ChatGPT内测邀请,并使用它的代码解释器(Python Interpreter)插件让ChatGPT针对一份excel数据完成了非常专业的数据分析的工作。

重磅福利,斯坦福大学在去年秋季开设了应该是全球第一个transformers相关的课程,授课人员来自OpenAI、Google Brain、Facebook人工智能实验室、DeepMind甚至是牛津大学的业界与学术界的一线大牛。而这两天,这门课相关视频也都公开了,大家可以去观看学习了!

OpenAI的Sora模型是最近两天最火热的模型。它生成的视频无论是清晰度、连贯性和时间上都有非常好的结果。在Sora之前,业界已经有了很多视频生成工具和平台。但为什么Sora可以引起如此大的关注?Sora生成的视频与此前其它平台生成的视频到底有哪些区别?有很多童鞋似乎对这些问题依然有疑问,本文将以通俗的语言解释Sora的独特之处。
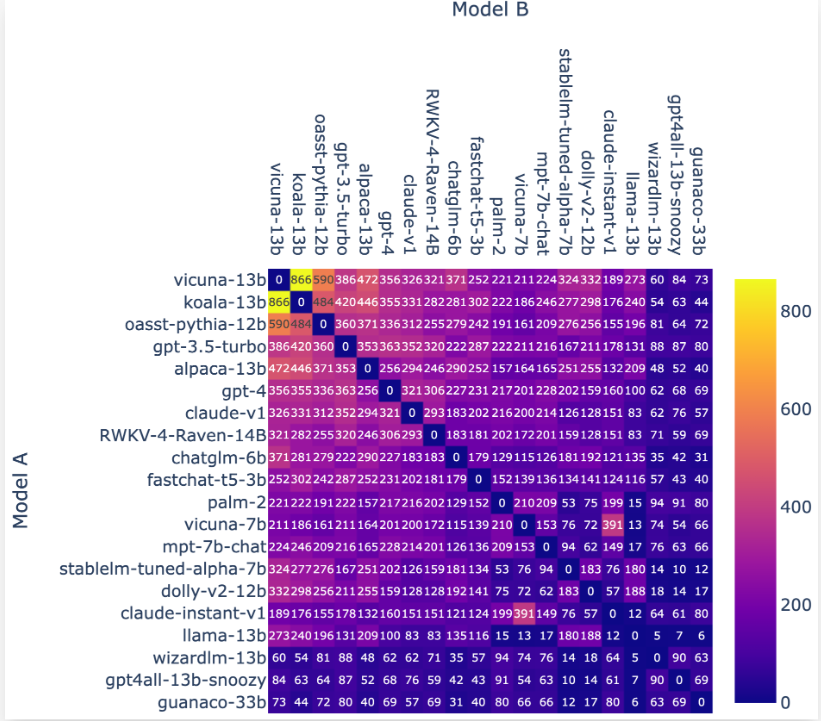
LM-SYS全称Large Model Systems Organization,是由加利福尼亚大学伯克利分校的学生和教师与加州大学圣地亚哥分校以及卡内基梅隆大学合作共同创立的开放式研究组织。该团队在2023年3月份成立,目前的工作是建立大模型的系统,是聊天机器人Vicuna的发布团队。今天开源 了包含3.3万包含真实人类偏好的对话数据集和3000条专家标注的对话数据集:Chatbot Arena Conversation Dataset和MT-bench人工注释对话数据集。
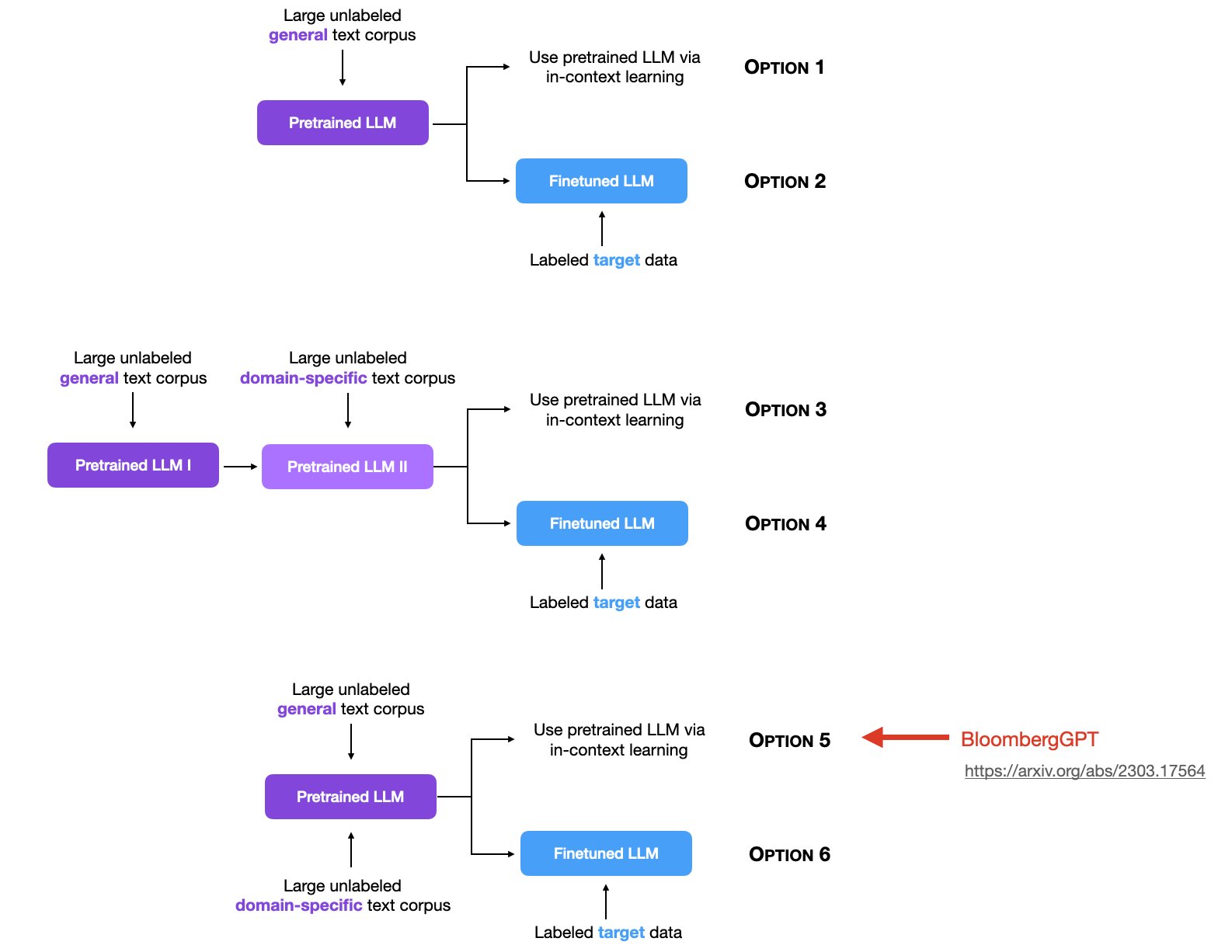
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的简介,也贡献了许多有价值的内容。在最新的一期统计中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于使用领域数据集做无监督预训练是目前讨论较少,但十分重要的一个方向。
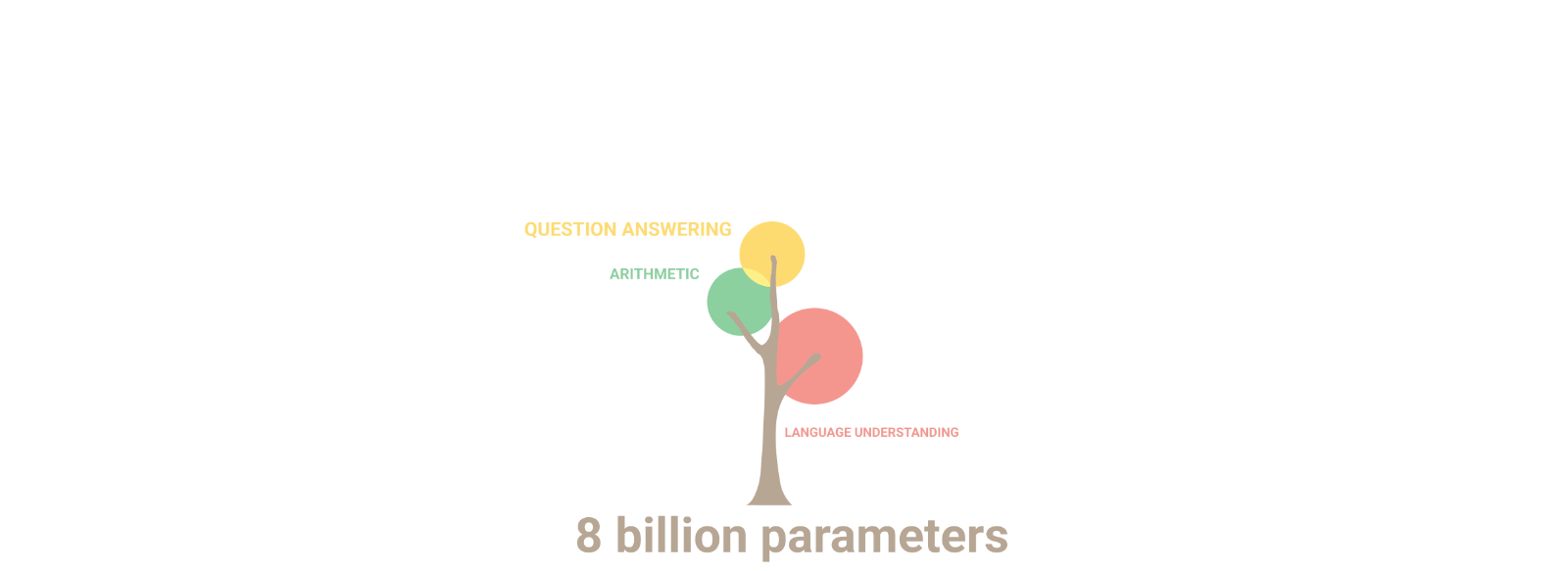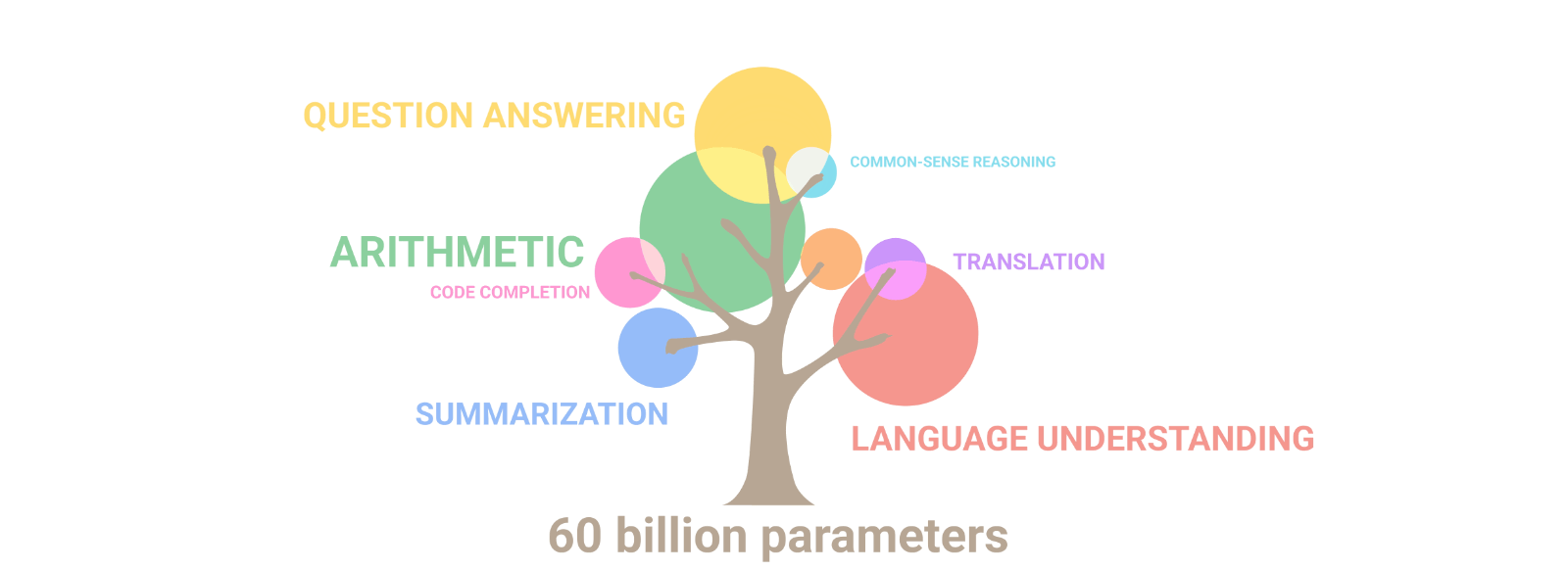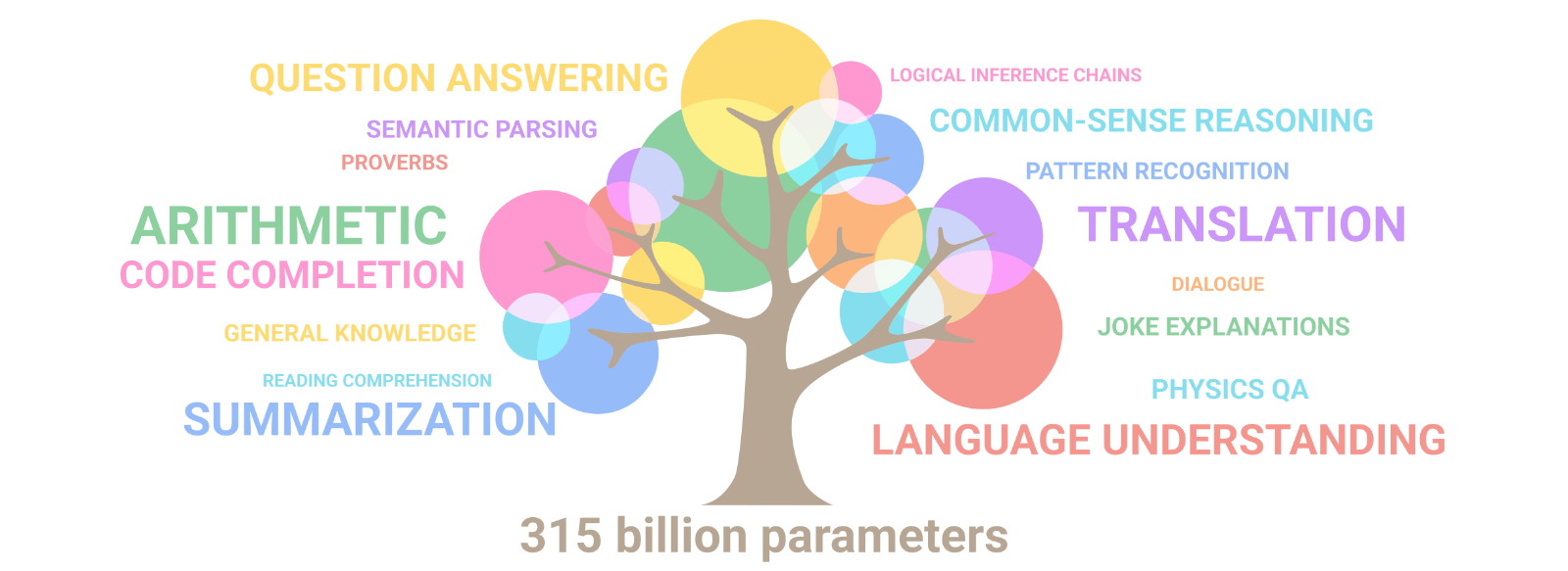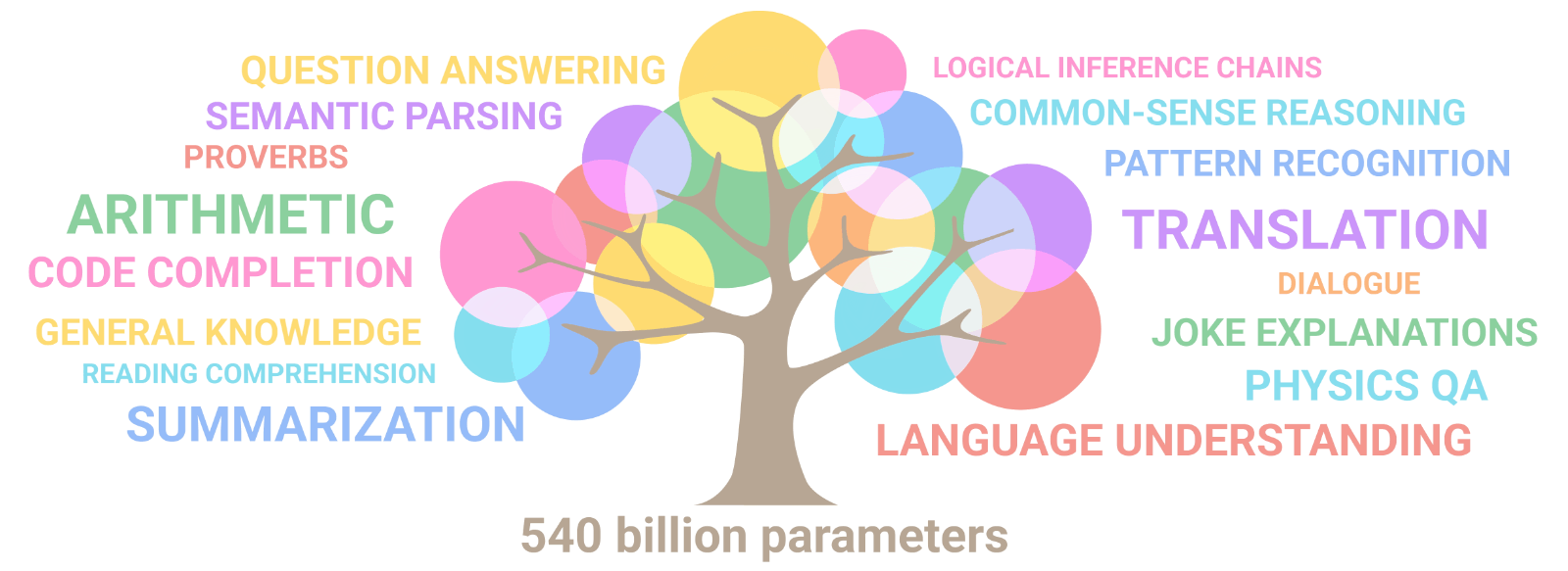
今天,Google介绍了一个新的语言模型,一个Pathways语言模型:PaLM,这是一个用Pathways系统训练的5400亿个参数、仅有dense decoder的Transformer模型,在数百个语言理解和生成任务上对PaLM进行了评估,发现它在大多数任务中实现了最先进的性能,在许多情况下都有显著的优势。
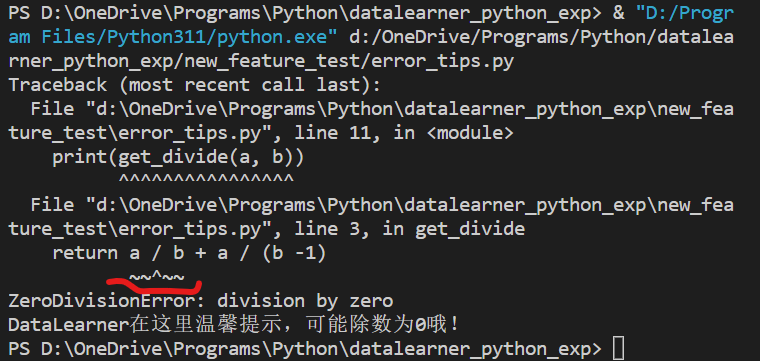
上个月Python的3.11版本发布了第一个beta版本,3.11带来了很多非常棒的新特性,例如错误提示更加具体,可以定位到具体代码位置等,十分友好,建议大家关注。这里简单为大家介绍一下。
KerasCV是由Keras官方团队发布的一个计算机视觉框架,可以帮助大家用来处理计算机视觉领域的相关任务和问题。这是2022年4月刚发布的最新产品,由于是官方团队出品的工具,所以质量有保证,且社区活跃,一直在积极更新。
OpenAI发布了一个全新的针对逻辑推理优化的大语言模型o1模型。官方宣称其推理能力相比较当前的大语言模型(GPT-4o)有了大幅提升。OpenAI宣称o1模型在编程竞赛问题(Codeforces)中排名第89百分位,在美国数学奥林匹克(AIME)的资格赛中位列美国前500名,并且在物理、 生物和化学问题的基准测试(GPQA)上超越了人类博士水平的准确率。
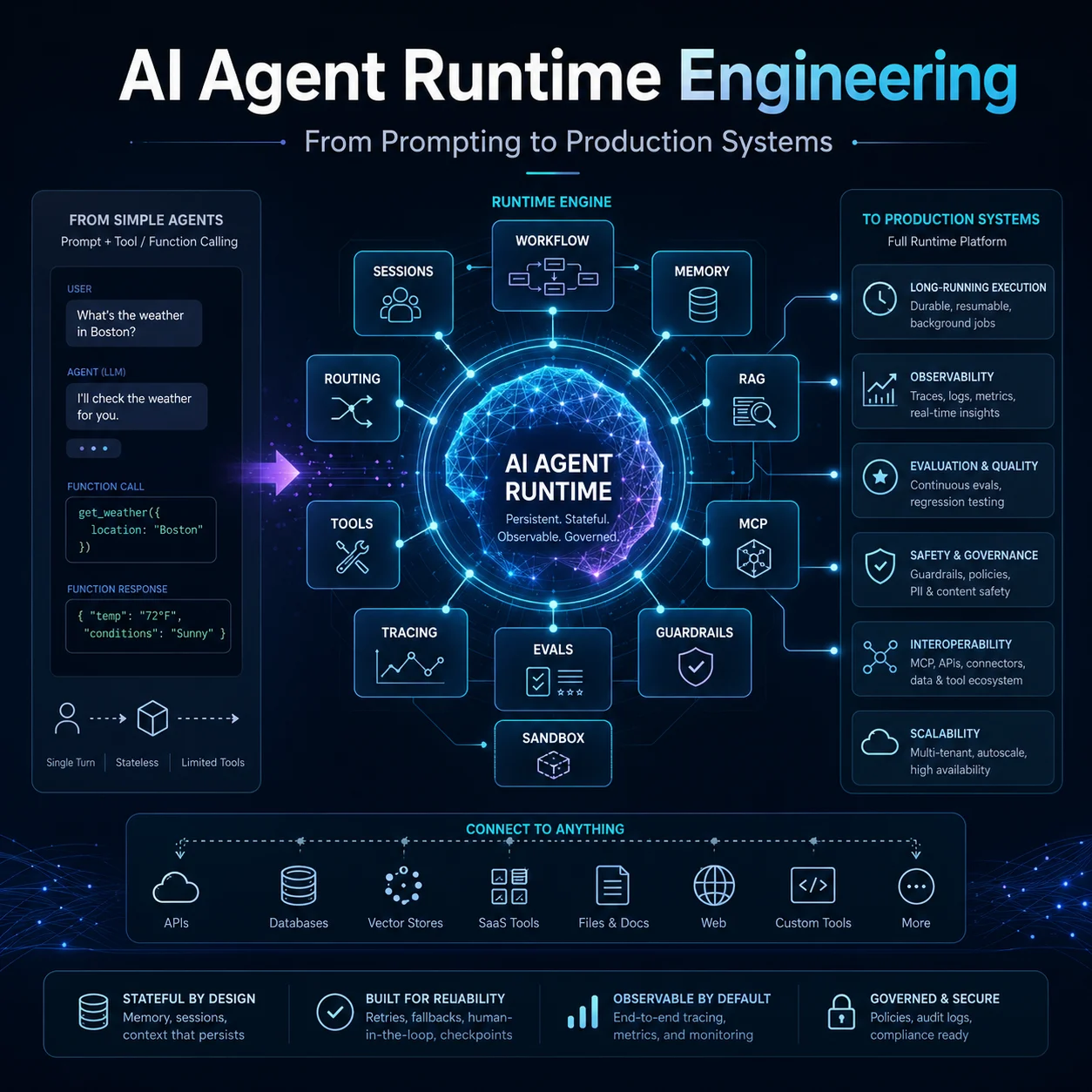
过去两年,AI Agent 的重心已经明显从“把更强模型接上几个函数”转向“把模型放进一个可恢复、可观测、可治理、可扩展的运行时系统”。最强的行业信号并不只是模型能力升级,而是 OpenAI 把 Background mode、Sessions、Agents SDK、Tracing、Evals 做成一等开发面;Anthropic 把 Skills、MCP、Memory、Compaction、Context Editing、Advisor、Managed Agents 逐步补齐;Google 把 ADK、A
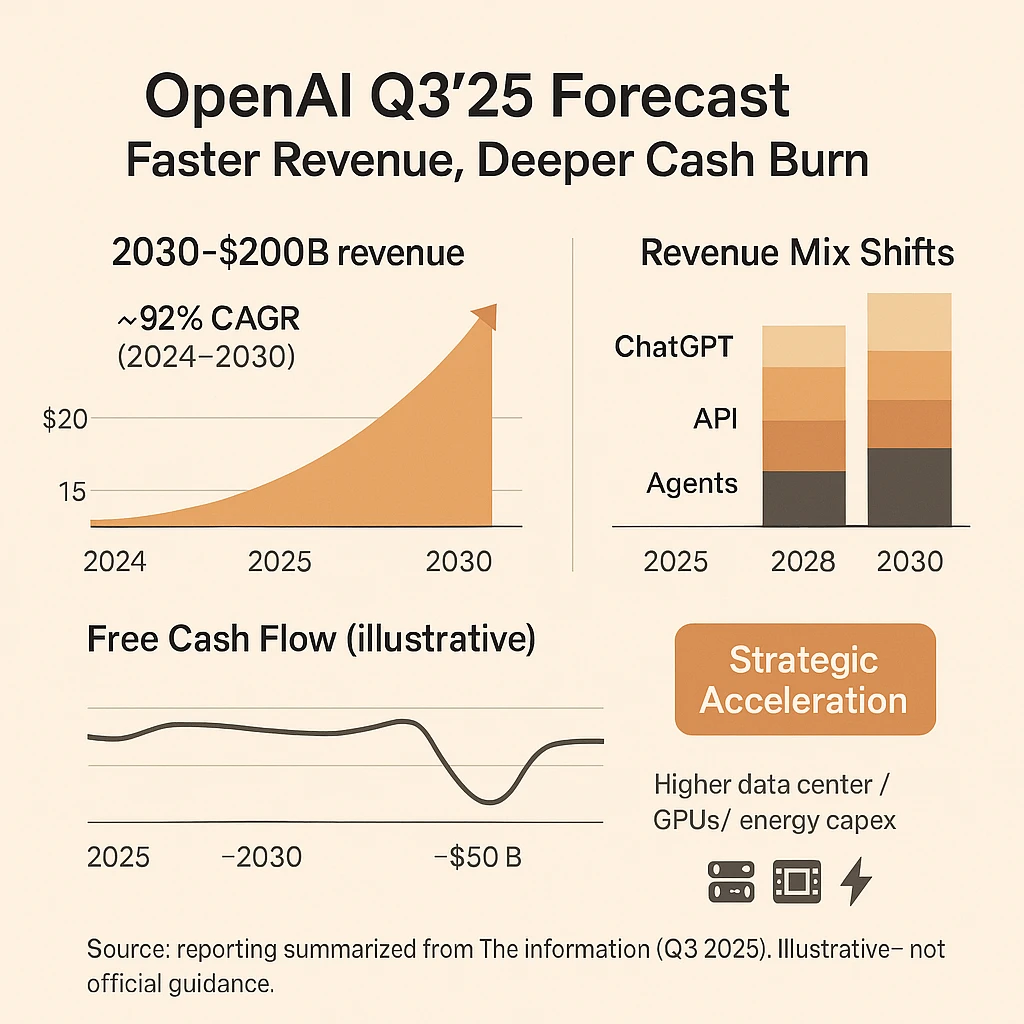
根据TheInformaiton的披露,近期OpenAI更新了他们最新财务预测(截至2025年第三季度)。这份收入预测展示了当前OpenAI的收入情况,并描绘了一幅引人注目的未来图景。与2025年第一季度OpenAI自己的预测相比,新数据不仅上调了收入预期,也揭示了公司因基础设施投入而面临的巨大现金消耗压力。本文将简单解读一下这份数据,包括OpenAI的收入情况,不同产品占比,如ChatGPT的比重等。

XVERSE-13B是元象开源的一个大语言模型,发布一周后就登顶HuggingFace流行趋势榜。该模型最大的特点是支持多语言,其中文和英文水平都十分优异,在评测结果上超过了Baichuan-13B,与ChatGLM2-12B差不多,不过ChatGLM2-12B是收费模型,而XVERSE-13B是免费商用授权!

Aquila-7B是北京人工智能研究院(BAAI)开源的一个可商用大语言模型。因为其良好的推理效果和友好的商用协议,使用的人较多。今天,BAAI再次开源2个基于Aquila-7B微调的编程大模型:AquilaCode-7B-multi和AquilaCode-7B-py。
7月28日,智谱AI(Zhipu AI)向开源社区投下了一枚重磅炸弹,正式发布了其最新的旗舰模型系列:GLM-4.5。该系列包含两个新成员——GLM-4.5和GLM-4.5-Air,两者均以开源权重形式提供。官方技术报告详细阐述了其设计理念、技术细节以及在多项基准测试中的表现。本次发布的核心目标是打造一个能够统一推理、代码和Agent智能体能力的模型,以应对日益复杂的AI应用需求。本文将深入解析这份官方报告,剖析其核心技术、性能表现,并探讨其在当前大模型竞争格局中的战略定位。

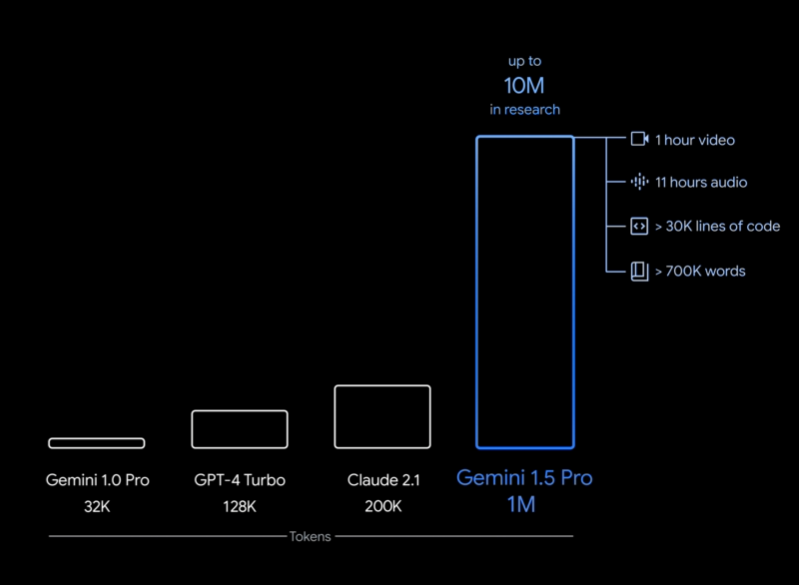
在2023年12月份,Google发布了Gemini系列大模型(参考:谷歌发布号称超过GPT-4V的大模型Gemini:4个版本,最大的Gemini的MMLU得分90.04,首次超过90的大模型),包含3个不同参数规模的版本。其中,Gemini Ultra号称在MMLU评测上超过了GPT-4,并且在月初也将Bard更名为Gemini,开放了Gemini Ultra的付费使用。刚刚,Google的CEO劈柴哥宣布发布了Gemini 1.5 Pro,这意味着仅仅一个半月,Gemini有了重大更新。