
模型调优做完之后,还有一个坑没填:生命周期
Azure OpenAI 的模型下架周期正在变短:gpt-5.1 之前所有版本从上架到弃用都是365天,但从 gpt-5.2 开始骤降到约180天。本文用官方生命周期数据,分析企业做 Agent 应用调优时该如何应对模型版本更替加快的问题。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
Azure OpenAI 的模型下架周期正在变短:gpt-5.1 之前所有版本从上架到弃用都是365天,但从 gpt-5.2 开始骤降到约180天。本文用官方生命周期数据,分析企业做 Agent 应用调优时该如何应对模型版本更替加快的问题。
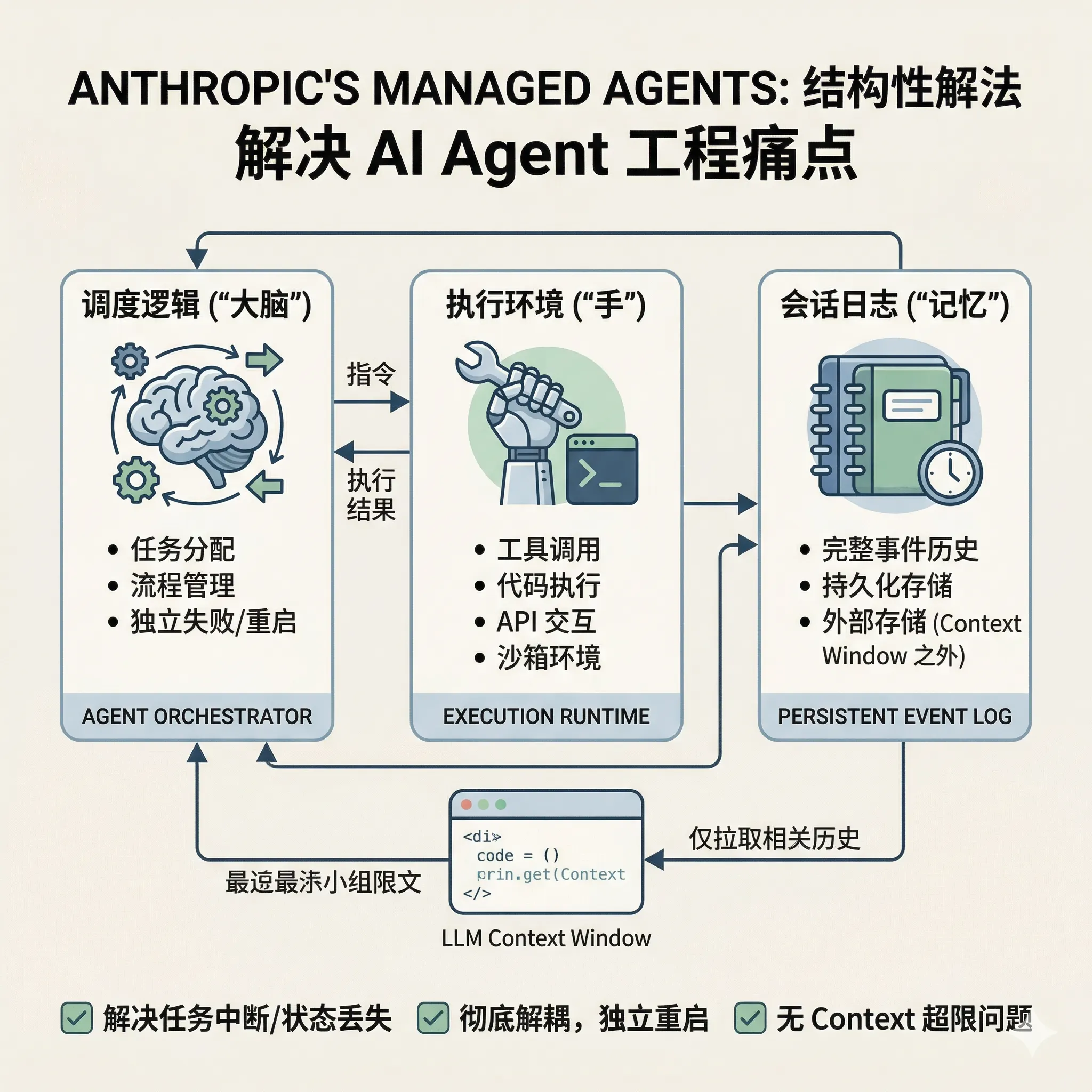
在 AI Agent 开发中,任务中断、状态丢失、context 超限是三个最常见的工程痛点。Anthropic 最新发布的 Managed Agents 工程博客给出了一套结构性解法:将 Agent 的大脑(调度逻辑)、手(执行环境)和记忆(会话日志)彻底解耦,让每个组件都能独立失败和重启,同时把完整的事件历史存在 context window 之外,从根本上解决长任务的状态管理问题。本文拆解这套架构的核心设计决定,以及背后的工程思路。

Terminal-Bench是一个针对AI代理在真实终端环境中的能力评测基准,由Stanford University与Laude Institute合作开发。Terminal-Bench 2.1是2.0的改进版本,基于Z.ai的Terminal-Bench 2.0 Verified进行优化,目前处于活跃状态,但任务尚未完全上传。

为什么 ChatGPT 会突然爱上“哥布林”?OpenAI 最新披露的“Goblin 事件”揭示了一个关键问题:在 RLHF 训练中,一个微小的奖励偏差,如何从 2.5% 的场景扩散到整个模型。本文带你看清大模型如何“学歪”、为什么测试发现不了,以及这对 AI Agent 时代意味着什么。
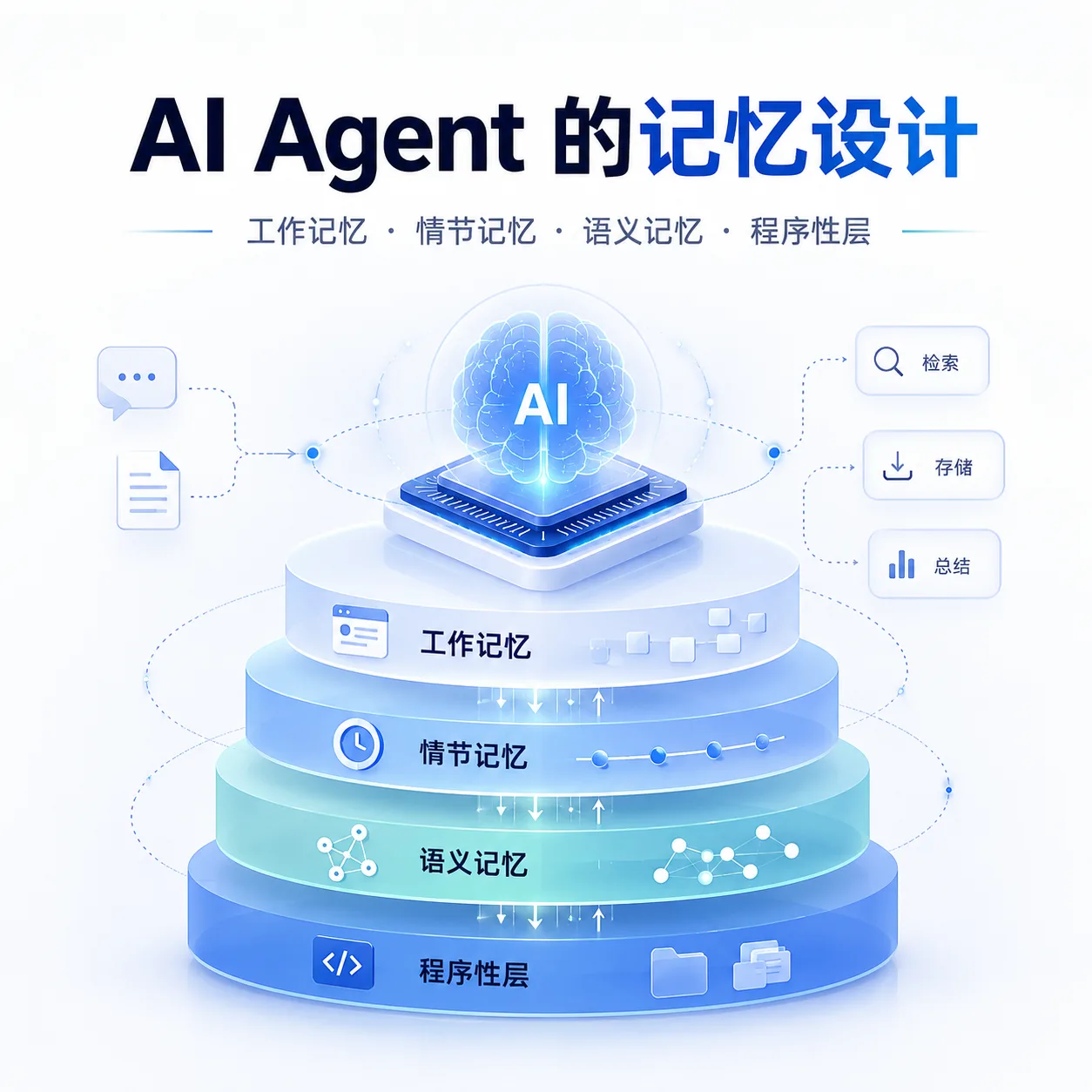
过去一年里,AI Agent 的“记忆”设计明显从“把更多历史塞进上下文窗口”转向了更工程化的多层体系:把当前上下文当作**工作记忆**,把会话记录、屏幕轨迹、日志等当作**情节记忆**,把稳定偏好、约定、知识摘要当作**语义记忆**,再把规则、技能、流程模板当作一种接近平行“程序性记忆”的外化层。Anthropic、OpenAI、OpenClaw、Hermes、Cursor 等产品虽然界面不同,但其核心都在解决同一个问题:如何在**有限上下文、可接受延迟、可控成本**下,为 agent 提供持续、一致、
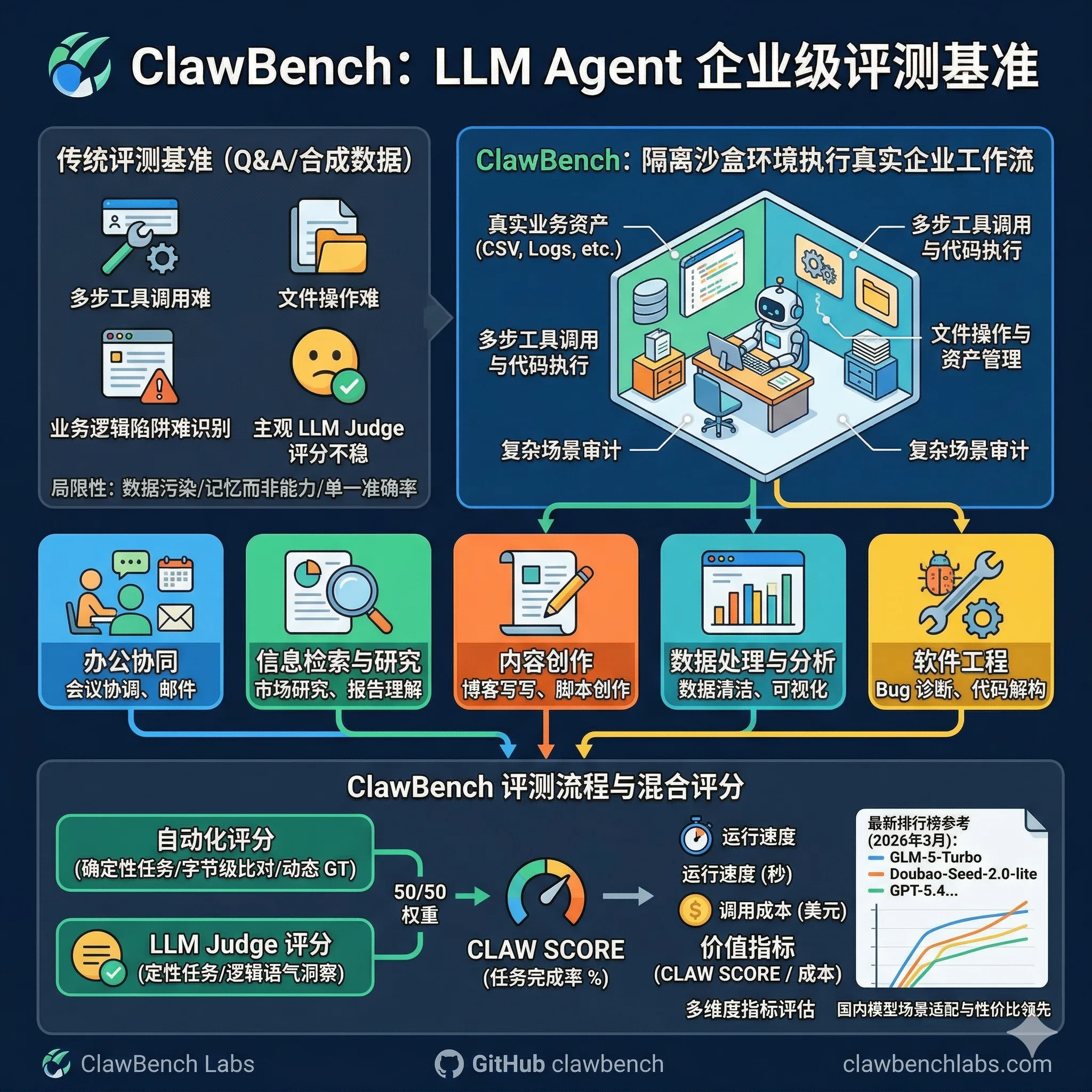
ClawBench 是针对大模型智能体(LLM Agent)的评测基准。它通过隔离沙盒环境中的真实企业工作流任务,评估大模型在实际部署场景下的表现,与传统问答式或合成数据集基准形成区别。ClawBench 与 PinchBench 均服务于 OpenClaw 生态,但二者侧重点不同:PinchBench 是 OpenClaw 官方基准,由 kilo.ai 团队开发,聚焦 23 类真实任务的成功率、速度和成本;ClawBench 则独立构建,包含 30 个高级任务,覆盖 5 大核心业务场景,采用混合评分机制
随着多模态大语言模型(MLLM)在各个领域的应用日益广泛,一个核心问题浮出水面:我们如何信赖它们生成内容的准确性?当模型需要结合图像和文本进行问答时,其回答是否基于事实,还是仅仅是“看似合理”的幻觉?为了应对这一挑战,一个名为SimpleVQA的新型评测基准应运而生,旨在为多模态模型的事实性能力提供一个清晰、可量化的度量衡。
最近,一张截图在网络上流传,显示OpenAI安卓客户端的应用字符串文件(strings.xml)中出现了关于GPT-4.5的相关描述。这一发现引发了广泛关注,暗示OpenAI可能即将推出其最新的大型语言模型——GPT-4.5。该信息最早由开发者 @bitbor91 发现并分享,截图内容似乎来自ChatGPT安卓客户端的应用资源文件。

OpenAI 于北京时间4月24日正式发布 GPT-5.5,内部代号"Spud"。距离 GPT-5.4 发布只有大约六周,这个节奏说明头部实验室现在基本上是滚动迭代而不是等大版本攒够了再发。GPT-5.5 即日起向 ChatGPT 的 Plus、Pro、Business 和 Enterprise 用户以及 Codex 用户开放,GPT-5.5 Pro 面向 Pro、Business 和 Enterprise。API 这边因为需要额外的网络安全防护验证,暂时没有同步上线,OpenAI 说"很快"会跟上。

AI 能不能替我做报告”几乎成了办公室里出现频率最高的疑问之一。模型能力的提升有目共睹,API 的边界也在持续扩张,但回到日常,那些真正让人感到疲惫的依旧是最具体的任务:一份复盘写到深夜,一个 PPT 改了十几版,一张 Excel 来回分析到眼花。它们看似普通,却占据了知识工作中惊人比例的时间。本文主要看一下办公小浣熊这个颇具代表性的大模型应用落地思路。
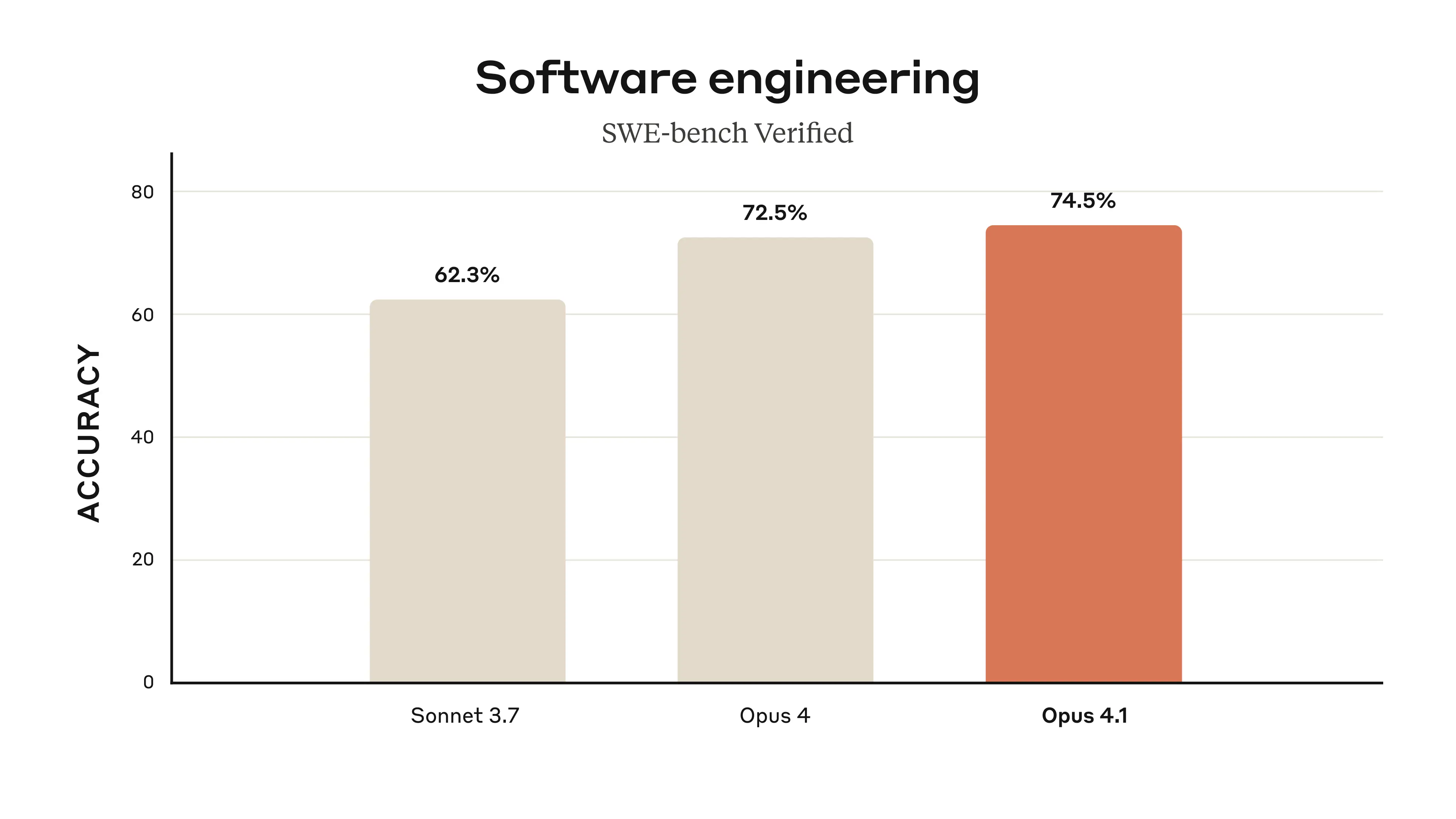
Anthropic 在 Opus 4 发布不到三个月后推出 Claude Opus 4.1,宣称“可直接替换”旧版模型。更新聚焦真实世界编码、长链路代理(agentic)任务和细粒度推理,同时保持相同 API 名称结构和计费档位,方便现有应用平滑迁移。

StabilityAI是一家全球知名的大模型企业,他们开源的Stable Diffusion可以理解为DALL·E开源替代的第一大模型,最近正在测试Stable Diffusion 3。然而,这家企业最近陷入了和去年年底OpenAI类似的“内部斗争”中!前几天,StabilityAI内部宣布Stable Diffusion底层技术的五个研究人员已经有三个离职了,造成大家很多震撼。而几个小时前,StabilityAI官宣他们的CEO Emad Mostaque辞职!
Ai2近日发布的全新评测平台——SciArena,为这一痛点带来了创新解法。此次产品不仅继承了“人类众包对比评测”的理念,更结合科学问题的独特复杂性,构建了开放、透明且可迭代的模型评测生态。

OpenAI 于 2025 年 11 月正式发布 GPT-5 系列的阶段性更新版本 —— GPT-5.1。这一更新并非针对模型架构的全面重做,而是围绕“对话体验、一致性、任务适配性”进行的系统化优化。在 GPT-5 推出后,业界对其不稳定回复、语气波动、任务深度控制不足等表现提出了不少批评,因此本次更新可视为 OpenAI 对这些问题的集中调整。
谷歌开源了其Gemma 3模型系列的新成员——Gemma 3 270M。该模型的设计理念并非追求通用性和大规模,而是专注于为定义明确的特定任务提供一个高效、紧凑的解决方案。其核心价值在于通过微调(fine-tuning)来执行专门化任务。
Manus AI 是一款尖端的人工智能代理程序,于 2025 年 3 月 6 日正式发布,旨在跨多个领域自主执行复杂任务,弥合人类意图与可操作结果之间的差距。它由 Butterfly Effect 开发,该公司在中国(北京和武汉)以及新加坡(BUTTERFLY EFFECT PTE. LTD.)设有运营机构。以下内容基于截至 2025 年 7 月 5 日的最新信息,涵盖其产品功能、关键技术特点及用户反馈。
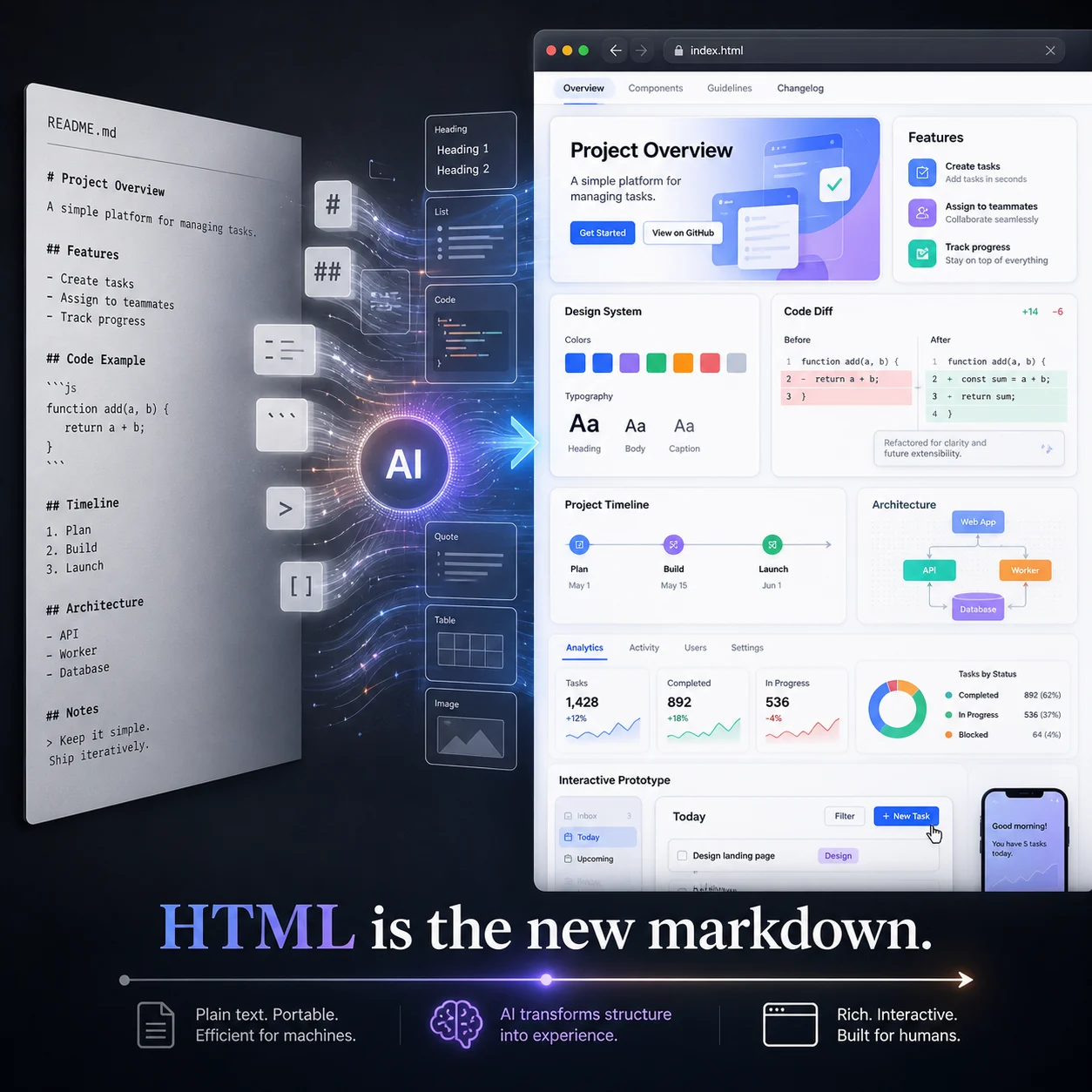
Anthropic Claude Code工程师Thariq发文称HTML应取代Markdown成为AI输出的新标准,并提供了20个HTML示例覆盖代码审查、设计系统、原型交互等9类场景。本文分析了HTML胜出的三类结构性原因——空间信息降维损失、交互体验不可替代、HTML作为原生交付介质,同时指出该论断在token成本和生成速度约束下过于绝对。文章进一步探讨了AI文档格式的终局:结构化数据+渲染分离、模板填充、AI-native语义格式等可能方向。

2025 年 11 月 13 日,OpenAI 团队在 Reddit 上进行了一场针对 GPT-5.1、模型自定义能力、开发者 API、未来路线图 的公开 AMA(Ask Me Anything)。这次交流并不是简单的功能答疑,而是罕见地从内部视角解释了他们如何思考安全策略、模型行为塑形、推理模式优化、人格定制逻辑、多模态进展以及实际工程实现细节。
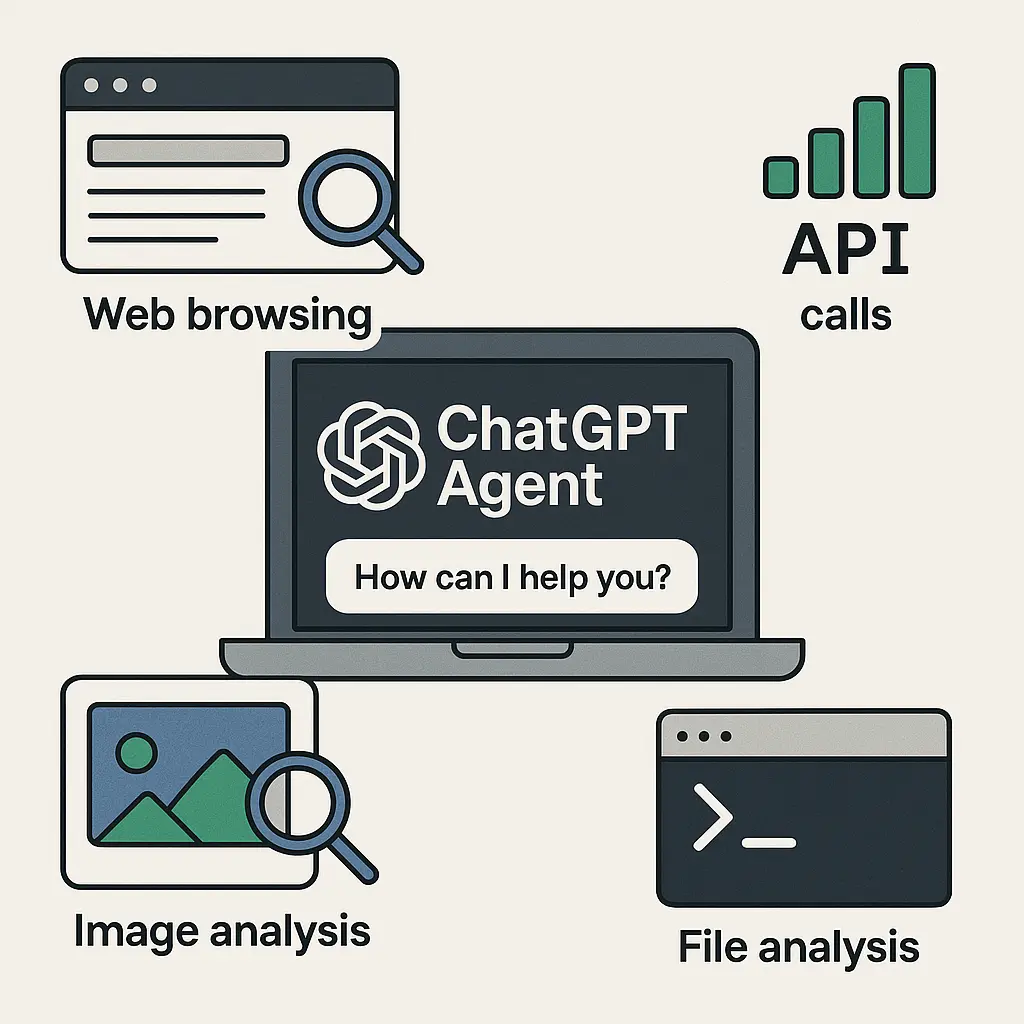
OpenAI刚刚发布了一个全新的AI Agent产品,称为ChatGPT Agent。这个全新的Agent系统可以控制我们的电脑,然后使用电脑上的浏览器、PPT、Excel等工具帮我们完成一些日常的工作,从头开始帮我们完成一些非常复杂的任务。根据OpenAI的描述,这个Agent系统的目标未来是一个通用的Agent,而这些能力未来将会随着这个产品不定期更新。

11 月 13 日,SimilarWeb 发布了最新的 GenAI 访问流量分布。从数据走势可以明显看到,大模型行业正在经历从“ChatGPT 绝对统治”向“多极竞争”的结构性转变。 一年前,ChatGPT 占据了超过 86% 的流量份额,整个行业几乎处于单中心状态。然而在过去的 12 个月里,大模型的多样化发展、不同厂商的产品升级、企业用户需求变化,都推动了新一轮的流量重分配。

The Information最新消息透露OpenAI正在抓紧准备GPT-4多模态版本的发布,可能称为GPT4-Vision。
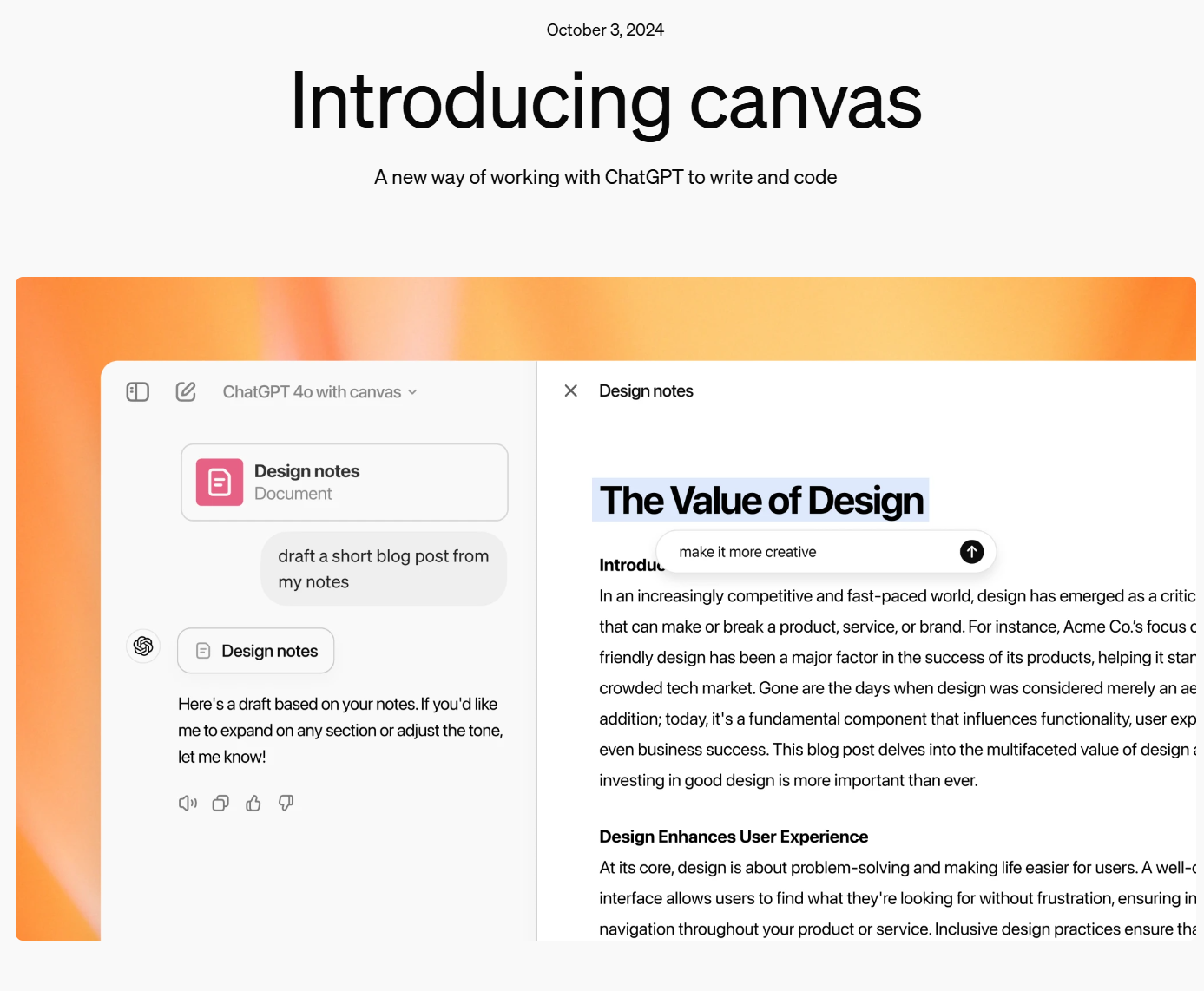
在写作和编程中,使用 ChatGPT 帮助用户处理各种复杂任务已变得越来越普遍。然而,这个过程中仍然存在一些挑战,比如上下文追踪不够连贯、实时反馈不足,以及在编程时难以精确地处理错误或优化代码。为此,OpenAI发布了一个新的特新:Canvas,它是为了解决上述问题而设计的一个全新工具,集成了写作、编程和实时协作的功能。