AI大模型学习
原创AI博客
大模型技术资讯
大模型评测排行
大模型评测排行榜
大模型数学推理能力排行榜
大模型代码编程能力排行榜
大模型图片编辑能力排行榜
LMSys ChatBot Arena排行榜
Berkeley大模型工具使用能力排行榜
大模型综合能力排行榜(旧)
大模型编程能力排行榜(旧)
OpenLLMLeaderboard中国站
AI大模型大全
最新大模型列表
大模型部署教程
大模型对比工具
大模型评测基准
大模型评测基准
SWE Bench Verified
ARC-AGI-2
AIME 2025
FrontierMath-Tier4
MMMU
AI Agents列表
AI资源仓库
AI领域与任务
AI研究机构
AI数据集
AI开源工具
数据推荐
国产AI大模型生态全览
AI模型概览图
AI模型月报
AI基础大模型
AI工具导航
AI大模型工具导航网站
在线聊天大模型列表
Interactive Topic Modeling
小木
Machine Learning
2014-06
2400
2017/02/06 09:55:36
主题模型是一个非常有用的工具,可以用来探索大规模文档的相关内容。然而,主题模型,如LDA获得的主题并不总是能被人们所理解。本篇文章提出了一种交互式话题模型来获得更好的主题结果。其主要工作包括: 1)作者建立了一个机制,可以将用户的反馈整合到交互式话题模型中。作者主要针对的信息是一个话题内部的词的相关性。目标是为了提升话题的一致性。作者主要的工作是针对树结构的先验(因为基于树的先验保留了共轭的性质,且更加容易用Gibbs抽样来进行推断)。基于此,作者提出了一个有效的基于树的话题模型框架。 2)当把用户的意见整合到模型中候,作者提出了一个交互式话题模型框架,保留了主题模型中用户满意的部分,重新学习了用户不满意的词语。 3)最后,作者使用了实际数据来检验模型的有效性。 #####基于树的主题模型 LDA虽然可以找出主题的词分布,但是它并不知道每一个单词的含义。单词只是从一个多项式分布中抽取的结果。由于LDA只是发现文档级别的词共现信息,所以它缺少发现语义或者语法上的含义的能力。为了解决这个问题,可以使用基于树结构的分布。树是一种非常好的编码词典信息的结构。作者借助Andrzejewski的工作,使用树结构来整合两种信息,即话题内部具有相关性的词语和不相关的词语。作者将每个主题下的多项式分布换成了树结构的分布,从而在树种产生了一组多项式分布的集合。其每个叶子节点是一个单词,每个单词至少出现在一个叶子节点中。当该树结构只有一个中心店,其他所有的V个单词都是叶子节点的时候,那么它就和经典LDA是一回事了。这种情况下,产生一个单词也很简单,就是$w\_{d,n} \sim \text{Mult}(\pi\_{z\_{d,n}},root)$ 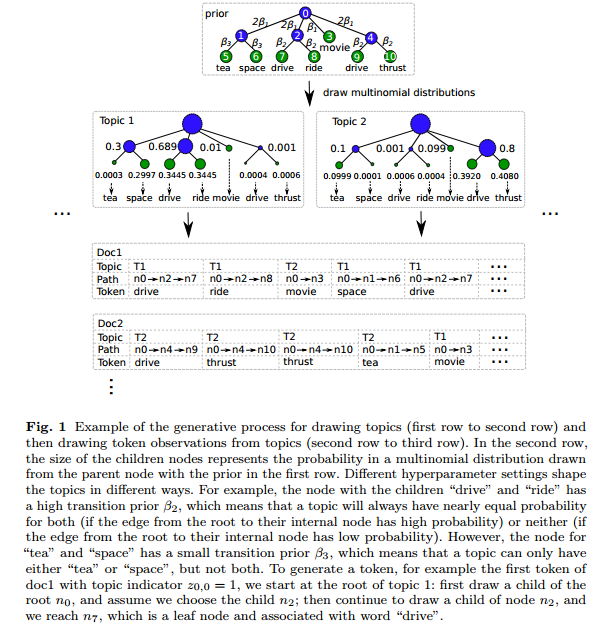 现在让我们看一个非退化的例子。为了从主题k中产生单词$w\_{d,n}$。我们从一个树的路径$l\_{d,n}$出发,它是一个从根节点出发的节点列表:我们从根节点$l\_{d,n}$出发,选择一个子节点$l\_{d,n}[1]$,我们按照这种情况继续选择子节点$l\_{d,n}[i] \sim \text{Mult}(\pi\_{k,l\_{d,n}}[i-1])$直到叶子节点。然后选择叶子节点的单词。这个沿着树寻找的步骤,我们用来替换之前从一个主题中抽取一个单词的过程。剩下的过程就与经典的LDA是一样的了。 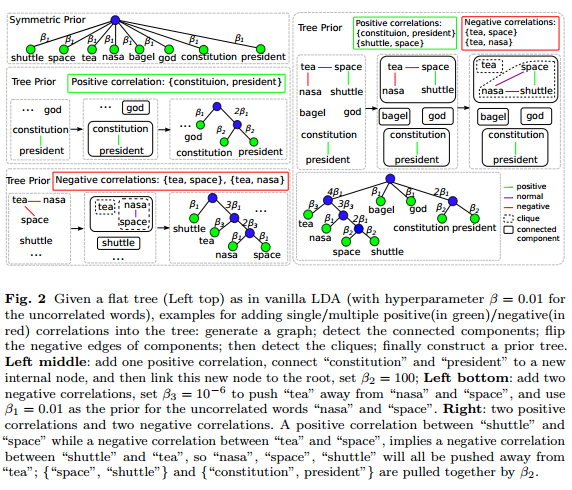 我们简单说一下如何把用户反馈的单词相关性整合到树结构中。首先,任何不包含重复单词的相关性很容易变成树的结构。假设经典LDA的对称先验,所有的单词都是根节点的子节点,如图2所示。为了编码一个相关性,我们可以把所有相关的单词替换成一个新的子节点的根,把相关的单词都变成这个根的子节点。图2描述了如何把“constitution”和“president”的正相关放到一起的。 如果不同的相关性中有相同的单词,那么我们就把他们分开并分别放到新的节点中。对于编码负相关的单词,作者使用了相关图的只是,将每个单词用一个负向边和一个节点相连接。具体我们就不说了。 最后,作者改进的是SPARSELDA,用来加速推断其结果。这里也就不提了。 作者的实验也很有意思,作者并没有直接比较交互式LDA的指标。而是让一些未经训练的人通过使用两种不同的系统来回答问题,用以比较哪个系统好,哪个系统差。
赏
支付宝扫码打赏
如果文章对您有帮助,欢迎打赏鼓励作者
Back to Top
 支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏