AI大模型学习
原创AI博客
大模型技术资讯
大模型评测排行
大模型评测排行榜
大模型数学推理能力排行榜
大模型代码编程能力排行榜
大模型图片编辑能力排行榜
LMSys ChatBot Arena排行榜
Berkeley大模型工具使用能力排行榜
大模型综合能力排行榜(旧)
大模型编程能力排行榜(旧)
OpenLLMLeaderboard中国站
AI大模型大全
最新大模型列表
大模型部署教程
大模型对比工具
大模型评测基准
大模型评测基准
SWE Bench Verified
ARC-AGI-2
AIME 2025
FrontierMath-Tier4
MMMU
AI Agents列表
AI资源仓库
AI领域与任务
AI研究机构
AI数据集
AI开源工具
数据推荐
国产AI大模型生态全览
AI模型概览图
AI模型月报
AI基础大模型
AI工具导航
AI大模型工具导航网站
在线聊天大模型列表
Whose Vote Should Count More: Optimal Integration of Labels from Labelers of Unknown Expertise
小木
NIPS
2009-09
2454
2017/02/09 21:29:49
[TOC] 基于机器学习的计算机视觉技术需要大量人工标注的图像数据。随着网络的发展,研究者可以以较小的代价从全世界获取廉价的标注结果。但这面临一些挑战:1)标注者的水平不一,先验知识不同,甚至有想法的认知;2)图像识别的难度不同;3)对于同一个图像的标注结果必须最终可以联合得到图像真实的标签结果。在这篇文章中,作者提出了一个基于概率的模型来推断图像的真实标签。 ####标注过程的建模 假设有$n$个图片,每个图片只属于两个分类结果中的一个(比如是不是人脸、男性/女性、是不是笑脸等)。我们希望通过询问$m$个标注者得到每幅图片$j$的标签$Z_j$。观测到的标签结果依赖于几个偶然因素:1)图片识别的难度;2)标注者的专业程度;3)真实的图片标签。我们用$1/\beta_j \in[0,\infty)$来表示图片$j$的识别难度。这里$1/\beta_j = \infty$表明图片非常模糊并难以识别使得用户只有50%的概率标注正确。而$1/\beta_j =0$表明图片非常容易识别几乎所有的标注者都会标注正确。 每个标注者$i$的专业程度使用参数为$\alpha_i \in (-\infty,\infty) $来建模。这里$\alpha=+\infty$意味着标注者总能标注正确的结果,而$\alpha_i=-\infty$表示他总是标注错误,也就是说他可以区分出图片的结果,但总是标注出相反的结果。当$\alpha_i < 0 $的时候,标注者就是有对抗性的(adversial)。最后$\alpha_i=0$表明标注者无法区分图片的结果,即他对图片的真实标签一无所知。注意,作者并不需要标注者一定是人类,也就是说他也可以是一个算法。 标注者$i$对图像$j$的标注结果用$L\_{ij}$表示,在本模型下有: ```math p(L_{ij}=Z_j|\alpha_i,\beta_j)=\frac{1}{1+e^{-\alpha_i\beta_j}} ``` 因此,在这个模型下,观测的标签的log几率(log odds)是一个关于图像难度和标注者水平的双线性函数: ```math \log \frac{p(L_{ij}=Z_j)}{1-p(L_{ij}=Z_{ij})} = \alpha_j\beta_j ``` 水平较高的标注者有更高的概率标注正确。随着图片识别难度的增加,它被标注正确的概率将接近0.5。而随着标注者水平的降低,其标注正确的概率也将接近于0.5。 <center> 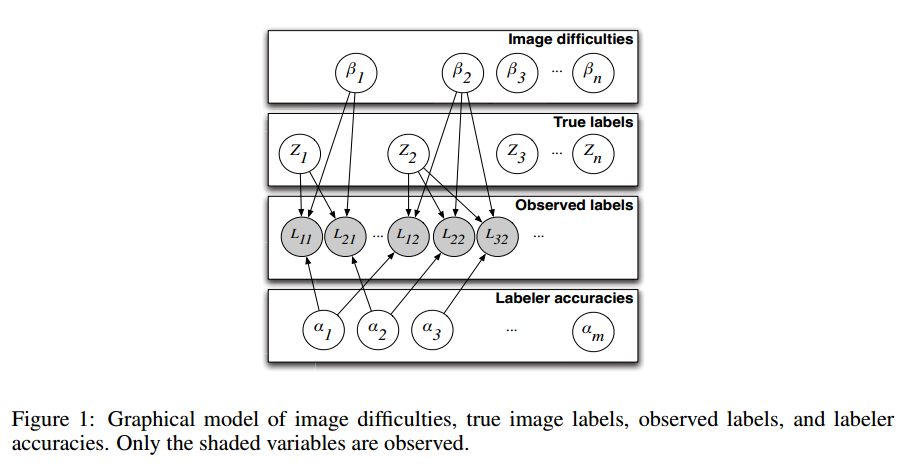 </center> ####模型的推断 观测到的标签是来自于$\\{L\_{ij}\\}$的随机变量。不可观测变量包括图片的真实标签$Z_j$,不同的标注者的正确率$\alpha_i$以及图像的难度$1/\beta_j$。在这里,作者使用[EM算法](http://www.datalearner.com/blog/1051486385181459 "EM算法")来获得这些变量的极大似然估计结果。 **E步骤:**假设图片$j$所有的标注结果为$l\_j$。注意,并不是每个标注者都要标注所有的图片,于是$l\_{ij}$里面的$i$是指标注过图片$j$的用户。我们需要计算所有给定$\alpha,\beta$(从M步骤计算得到的)情况下的真实标签的后验概率: ```math p(z_j|l,\alpha,\beta) \propto p(z_j|\alpha,\beta_j)p(l_j|z_j,\alpha,\beta_j) \propto p(z_j)\prod_ip(l_{ij}|z_j,\alpha_j,\beta_j) ``` 这里$p(z_j|\alpha,\beta_j)=p(z_j)$使用的是独立性假设。 **M步骤:**我们在这里要最大化辅助函数Q,它的定义是给定参数$\alpha,\beta$情况下的观测值和隐变量的联合log似然函数: ```math \begin{aligned} Q(\alpha,\beta) &= E[\ln p(lz,|\alpha,\beta)] \\ &=E[\ln \prod_j (p(z_j)\prod_ip(l_{ij}|z_j,\alpha_i,\beta_j))]\\ &=\sum_jE[\ln p(zj)]+\sum_{ij} E[ \ln p(l_{ij}|z_j,\alpha_i,\beta_j)] \end{aligned} ``` 使用梯度下降我们就可以找到局部最大化$Q$的$\alpha,\beta$了。 最后我们放一副作者的实验结果图。 <center> 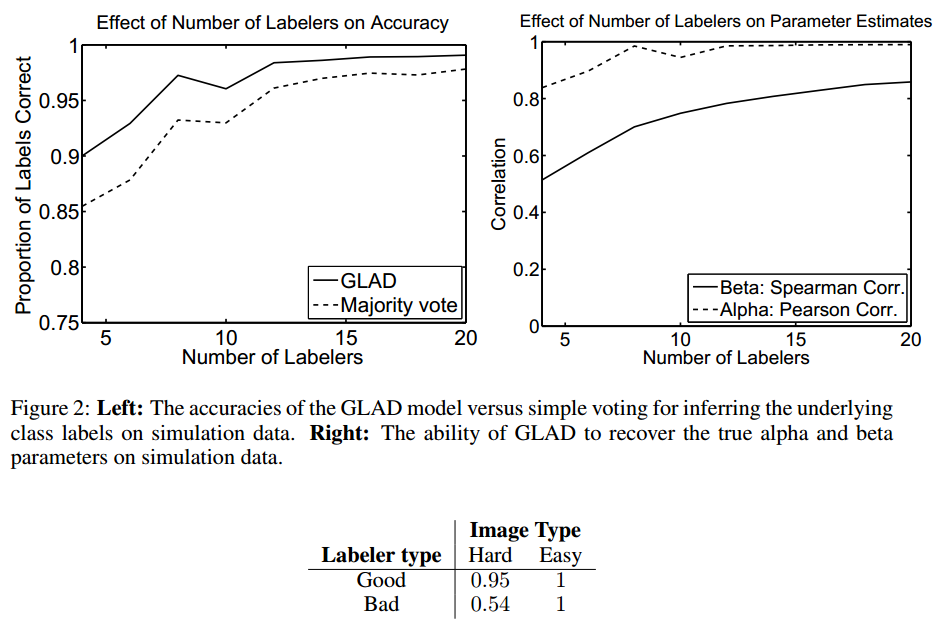 </center>
赏
支付宝扫码打赏
如果文章对您有帮助,欢迎打赏鼓励作者
Back to Top
 支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏