AI大模型学习
原创AI博客
大模型技术资讯
大模型评测排行
大模型评测排行榜
大模型数学推理能力排行榜
大模型代码编程能力排行榜
大模型图片编辑能力排行榜
LMSys ChatBot Arena排行榜
Berkeley大模型工具使用能力排行榜
大模型综合能力排行榜(旧)
大模型编程能力排行榜(旧)
OpenLLMLeaderboard中国站
AI大模型大全
最新大模型列表
大模型部署教程
大模型对比工具
大模型评测基准
大模型评测基准
SWE Bench Verified
ARC-AGI-2
AIME 2025
FrontierMath-Tier4
MMMU
AI Agents列表
AI资源仓库
AI领域与任务
AI研究机构
AI数据集
AI开源工具
数据推荐
国产AI大模型生态全览
AI模型概览图
AI模型月报
AI基础大模型
AI工具导航
AI大模型工具导航网站
在线聊天大模型列表
Factorization vs. Regularization- Fusing Heterogeneous Social Relationships in Top-N Recommendation
Vanessa He
Internet Research
2011-04
1552
2017/02/13 16:30:56
**一、论文要点:** 1、研究目标:通过引入社交关系数据(好友关系和群成员关系)解决了新用户和不活跃用户的数据稀疏性问题。 2、存在问题:在稀疏数据条件下,社交关系在推荐精度上有较明显的提高;在密集数据条件下,社交关系在推荐精度上没有表现出明显的提高。 **二、基于社交融合的隐式分解研究思路:** **1、MF模型:** 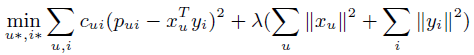 其中: (1)r_ui:在显示反馈数据集中表示用户u对产品i的偏好评分;在隐式反馈数据集中表示用户行为的观测,如,用户u购买产品i的次数、用户u观看节目i上频率或者用户u花费在网页i上的时间等等。 (2)p_ui:二元变量,表示用户u对产品i的偏好;如果用户u“touch”或者“click”产品i,则表明p_ui =1,反之则p_ui =0。 (3)c_ui:信度水平通常指用户花在产品上的时间,或者用户与产品互动的频率。论文中,因为输入的用户-产品矩阵是严格二元矩阵,没有额外时间或者频率的有效数据,所以c_ui在所有用户-产品对中都设置为1. (4)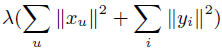是为了防止训练数据的过拟合化而引入的正则项。 是依赖于数据的,需要通过交叉验证方式确定。 另外,交替最小二乘法得到目标函数损失最小的结果如下: 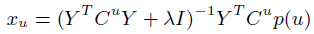 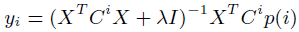 其中Y是item矩阵,n*f维,每一行是一个item_vec; C^u是n*n维的对角矩阵, 对角线上的每一个元素是c_ui;P(u)是n*1的列向量,它的第i个元素为p_ui。 **2、通过正则化项融合好友关系** 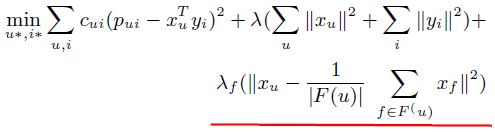••••式(1) 其中,λ_f是好友关系正则化系数。 同样采用交替最小二乘法来优化,结果如下: 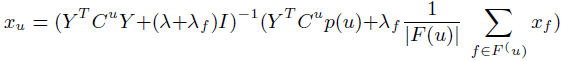 y_i的优化结果与矩阵分解中结果一致。 **3、通过分解模型融合群成员关系** 群成员关系涉及到用户和群两种实体,因此,用户-产品交互矩阵可被直接分解成两部分:用户隐向量和群向量,表示用户在群中的偏好和群在隐特征上的贡献。因此,论文采用联合矩阵分解方法解决这一问题,在论文实验部分证明了分解模型比正则化模型更加有效。 (1)通过分解模型融合群成员关系的公式如下: 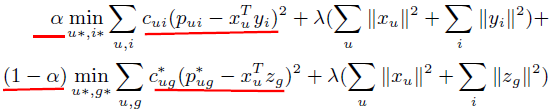 ••式(2) 参数α用于调整分解模型中用户-产品矩阵和用户-群矩阵的权重。其他参数的含义与矩阵分解中的类似。 同样采用交替最小二乘法来优化,用户向量和群向量优化结果如下: 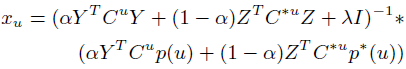 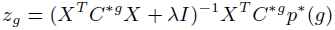 y_i的优化结果与矩阵分解中结果一致。 (2)如果是通过正则化模型融合群成员关系,想法是将用户-群矩阵转化成带有权重的用户-用户关系,举例来说,如果用户u和v有两个共同群,则认为两用户间有连接关系,设置权重为2。总结公式如下: 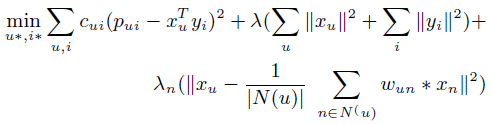 其中,λ_n是群成员关系的正则化系数,N(u)是与用户u有共同群的邻用户总数,x_n是邻用户向量,w_un是用户u和邻用户n之间的权重,定义如下: 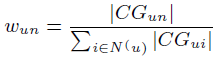 这里的|CG_un|表示用户u和n之间共有群数。 同样采用交替最小二乘法来优化,优化结果如下: 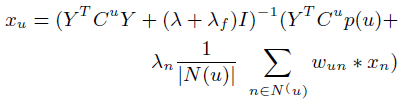 y_i的优化结果与矩阵分解中结果一致。 **4、融合群成员关系和好友关系的推荐** 好友关系的处理方式是正则化模型式(1),群成员关系的处理方式是联合矩阵分解模型式(2),所以融合结果如下: 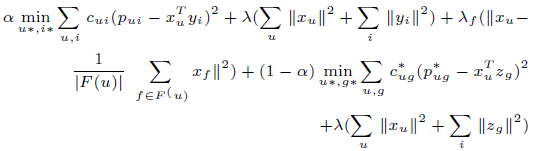 所以,优化结果如下: 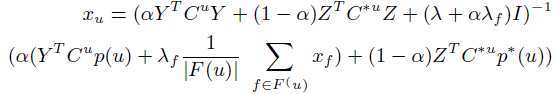 产品向量y_i的优化结果与矩阵分解中结果一致,群向量z_g的优化结果与通过分解模型融合群成员关系优化结果一致。 **5、Top-N推荐** 为了给每一个用户u产生一个Top-N推荐,对候选产品集Φ_u中的每一个产品i,通过如下公式计算预测评分并根据评分向用户进行Top-N推荐,预测评分公式如下: 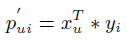 其中,x_u和y_i分别表示用户隐特征向量和产品隐特征向量。这一预测评分可以被用于第4点中的融合模型中。
赏
支付宝扫码打赏
如果文章对您有帮助,欢迎打赏鼓励作者
Back to Top
 支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏