AI大模型学习
原创AI博客
大模型技术资讯
大模型评测排行
大模型评测排行榜
大模型数学推理能力排行榜
大模型代码编程能力排行榜
大模型图片编辑能力排行榜
LMSys ChatBot Arena排行榜
Berkeley大模型工具使用能力排行榜
大模型综合能力排行榜(旧)
大模型编程能力排行榜(旧)
OpenLLMLeaderboard中国站
AI大模型大全
最新大模型列表
大模型部署教程
大模型对比工具
大模型评测基准
大模型评测基准
SWE Bench Verified
ARC-AGI-2
AIME 2025
FrontierMath-Tier4
MMMU
AI Agents列表
AI资源仓库
AI领域与任务
AI研究机构
AI数据集
AI开源工具
数据推荐
国产AI大模型生态全览
AI模型概览图
AI模型月报
AI基础大模型
AI工具导航
AI大模型工具导航网站
在线聊天大模型列表
Crowdclustering
小木
NIPS
2011-09
1684
2017/04/22 10:40:50
众包发展很快,也非常有用。作者提出的问题是众包是否可以用来发现类别?即众包除了可以将已有的实例分到已经存在的类别外,是否可以把它们分到一些从未定义过的类别中?比如,我们有很多的图片,不可能让一个人浏览所有的图片然后把它们分分类。此外,每个人都有不同的背景,在分类过程中还可能会产生冲突。但是使用众包的方式解决大规模分类依然是一种非常值得研究的话题。在这篇论文中,作者使用两个步骤来探索聚类的问题:1)首先将问题的数量降低到一个可以接受的规模,并让工作者进行人工聚类,2)然后提出了一个标注过程的模型,该模型可以自动聚合人们的标注数据。 #### 从工作者处收集信息 作者收集信息的方式是将展示M个图片的集合,然后让工作者使用鼠标进行分组。作者提供一些引导信息,但是不提供任何分类信息,让工作者自己去分组。工作者可以根据自己的标准将M个项目聚成几组。一个项目也可以独自为一个类。M的选择依赖于任务难度、图片解析度和引导信息之间的权衡。这些工作者的很多个M的任务就是我们计算的原始数据。 假设有N个项目,J个工作者,H个HIT(Human Intelligence Tasks)的任务,每个HIT的结果都是$C_M^2$个二元标签。我们从工作者那里获得的信息就是一组二元变量$\mathcal{L}$的集合,其中的每个标签的结果为$\\{+1,-1\\}$两种情况。假设总共有T个二元集合,第t个标签是一个四元组$(a_t,b_t,j_t,h_t)$,其中$a_t$是N个图片的一个,$b_t$是N个图片与之对比的另一个。标签的数量是$H \times C_M^2$。 #### 抽样过程 我们不能简单的将所有的任务分成不重复的集合,这有很大的问题。不同任务之间必须有重合或者是冗余:即每个项目必须属于多个任务。或者,我们也可以构建一些HIT的任务,是的每一个项目对至少出现在一个HIT中,因此每一个项目对都会被抽取。但这对有很多项目的任务来说成本太高,因为标签的数量是$T\in \Omega(N^2)$。然而,我们可以通过一个联通性质来解决这个问题,即如果项目a和b属于一个类,项目b和项目c可能在一组,那么项目a和c也就可能在一组。 作为基准抽样方法,作者使用了Strehl和Ghosh为对象分布聚类提出的一个随机抽样模式。一个完整数据的集合会从一部分数据的子集中学习得到。他们的这种模式使用参数V控制抽样的冗余,在这个问题中,就是每个任务应当属于的HIT任务的数量。N个项目,每个HIT任务就有$M/V$个项目,剩下的$M-M/V$的项目分配则通过对$M-M/V$的不重复抽样得到。因此,我们总共得到了$NV/M$个不同的任务。我们在这里引入一个参数R,它是每个HIT任务的不同工作者的个数,因此总共的任务结果是$R\times NV/M$个,同时在这里作者假设每个工作者不能做相同的任务。这个抽样模式产生了$T=R\times (NV/M) \times C_M^2 \in O(RNVM)$个标签。 #### 通过贝叶斯众包聚类聚合结果 这个聚类问题就是一种联合多种可选择性数据的聚类问题,也称为一致性聚类、聚类聚合或者簇集。尽管这些方法可以处理部分输入聚类,大多数方法都无法处理输入的数据只是总体数据的一小部分。此外,现有的方法主要集中生产一个平均的聚类结果。但是,我们感兴趣的是不同的个人是如何划分数据的。我们寻找另一个数据的主要聚类结果,它可以用来描述个体工作者的倾向。我们把这些组的数据称为**原子聚类**。例如,假设一个工作者把物体分成高的对象和低的对象,但是其它的工作者把这些物体分成红色的物体和蓝色的物体。于是,我们的方法应当恢复出四种原子聚类:高红色物体,短红色物体,高蓝色和短蓝色物体。这两个工作者的行为可以被总结成使用一个院子聚类的混淆表(后面会说到)。第一个工作者把第一个和第三个原子类分到一起,第二个工作者把第一个和第二个原子类放到一起。 #### 生成模型 我们把数据点都表示成欧几里得空间里面的点,工作者则是空间中成对的二元分类器。然后我们使用DPMM把数据聚类成原子聚类,用来估计聚类数量。使用欧几里得表示数据的优点是它可以以一种紧凑的方式描述数据项目的特征。作者提出了一种因变量模型,它可以把成对的二元标签变成与工作者和图像相关的隐变量。这里的图模型如下图-1所示。这里的$x\_i$是一个D维的向量,其中$x\_{i,d}$是指项目$i$在嵌入空间$R^D$中的位置。对称矩阵$W\_j \in R^{D\times D}$,其中的项目为$W\_{j,d\_1,d\_2}$,和偏移$\tau\_j\in R$(在下一段中将会解释)用来定义一个成对的二元分类器,用来表示工作者$j$的标注行为。由于$W\_j$是对称的,我们只需要指定它的上三角部分就可以了:$\text{vecp}\\{W\_j\\}$是一个向量,它将$W\_j$ 的部分列“堆积”起来,按照$[\text{vecp}\\{W\_j\\}]\_1=[W\_j]\_{11}$,$[\text{vecp}\\{W\_j\\}]\_2=[W\_j]\_{12}$,$[\text{vecp}\\{W\_j\\}]\_3=[W\_j]\_{22}$这样的顺序堆积。$\Phi=\\{\mu\_k,\sum\_k\\}$是第k个高斯原子簇的均值和方差,$U\_k$是Dirichlet Process的stick breaking权重。 在这里,最关键的问题就是使用一个成对的四元逻辑回归似然,用来描述第$j$个工作者把图像$a\_t$和$b\_t$标注成$l\_t$的一个倾向: ```math p(l_t|x_{at},x_{bt},W_{jt},\tau_{jt})=\frac{1}{1+\exp(-l_tA_T)} ``` 在这里,我们把这个成对的四元活动定义成$A\_t=x\_{at}^TW\_{jt}x\_{bt}+\tau\_{jt}$。这里的对称的$W\_j$保证了$p(l\_t|x\_{at},x\_{bt},W\_{jt},\tau\_{jt})=p(l\_t|x\_{bt},x\_{at},W\_{jt},\tau\_{jt})$。这个形式的似然函数产生了一个紧凑且可解的方法,可以定义欧几里得空间里面成对的分类器。具有较大活动值的向量一般是属于同一个类的。作者发现这种形式的似然导致了$x\_i$数据点的簇可以很容易被混合模型聚类得到。 <center> 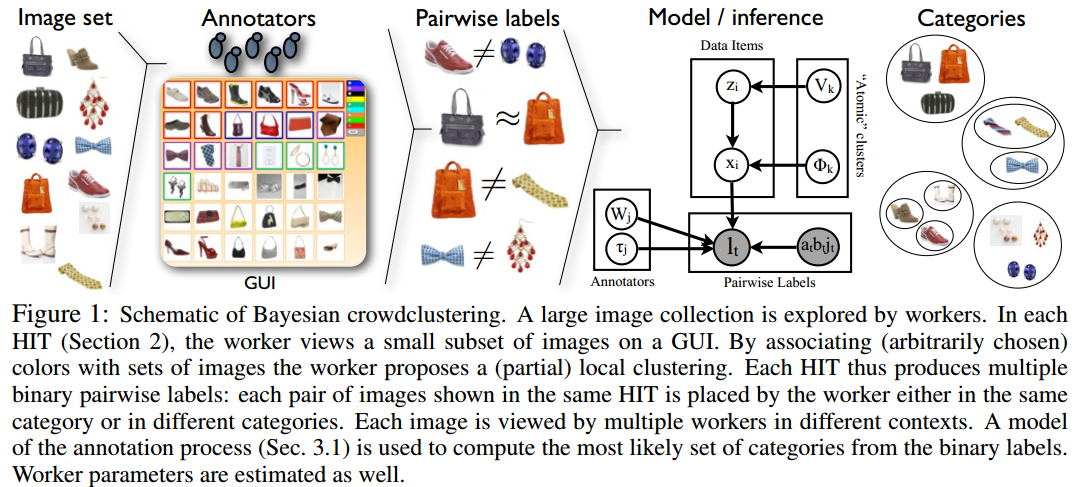 </center>
赏
支付宝扫码打赏
如果文章对您有帮助,欢迎打赏鼓励作者
Back to Top
 支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏