LongChat-13B-16K - LongChat-13B-16K
模型详细情况和参数
LongChat-13B-16K
- 模型全称
- LongChat-13B-16K
- 模型简称
- LongChat-13B-16K
- 模型类型
- 基础大模型
- 发布日期
- 2023-06-29
- 预训练文件大小
- 26GB
- 是否支持中文(中文优化)
- 否
- 最高支持的上下文长度
- 16K
- 模型参数数量(亿)
- 130.0
- 模型代码开源协议
- Apache 2.0
- 预训练结果开源商用情况
- 开源不可商用 - 不可以商用
- 模型GitHub链接
- https://github.com/DachengLi1/LongChat
- 模型HuggingFace链接
- https://huggingface.co/lmsys/longchat-13b-16k
- 在线演示地址
- 暂无
- 基础模型
-

LLaMA
查看详情 - 发布机构
LongChat-13B-16K 简介
LongChat-13B-16K是由LM-SYS开源的一个支持超长上下文输入的聊天大语言模型。也是目前开源领域对超长上下文支持最好的模型之一。关于LongChat的基本介绍参考: https://www.datalearner.com/blog/1051688222070709
2023年6月29日,LM-SYS发布LongChat系列的时候除了这里的LongChat-13B-16K,还包括一个7B版本的模型,参考: https://www.datalearner.com/ai-models/pretrained-models/LongChat-7B-16K
LongChat-13B-16K是基于MetaAI开眼的LLaMA-13B进行微调得到的。使用ShareGPT中提供的用户与GPT的对话数据微调得到。原始的LLaMA模型只支持2048长度的输入。而LongChat-7B则通过将原始输入长度进行重新编码后得到支持16K长度的上下文输入。具体方法参考: https://www.datalearner.com/blog/1051688257255268
官方公布的评测结果看,在发布的时候LongChat-13B-16K是开源领域对长输入支持最好的模型。官方的两个评测任务中,LongChat-13B-16K都是只比商业模型GPT-3.5和Claude-1.3差。
下图是超长主题检索评测结果总结:
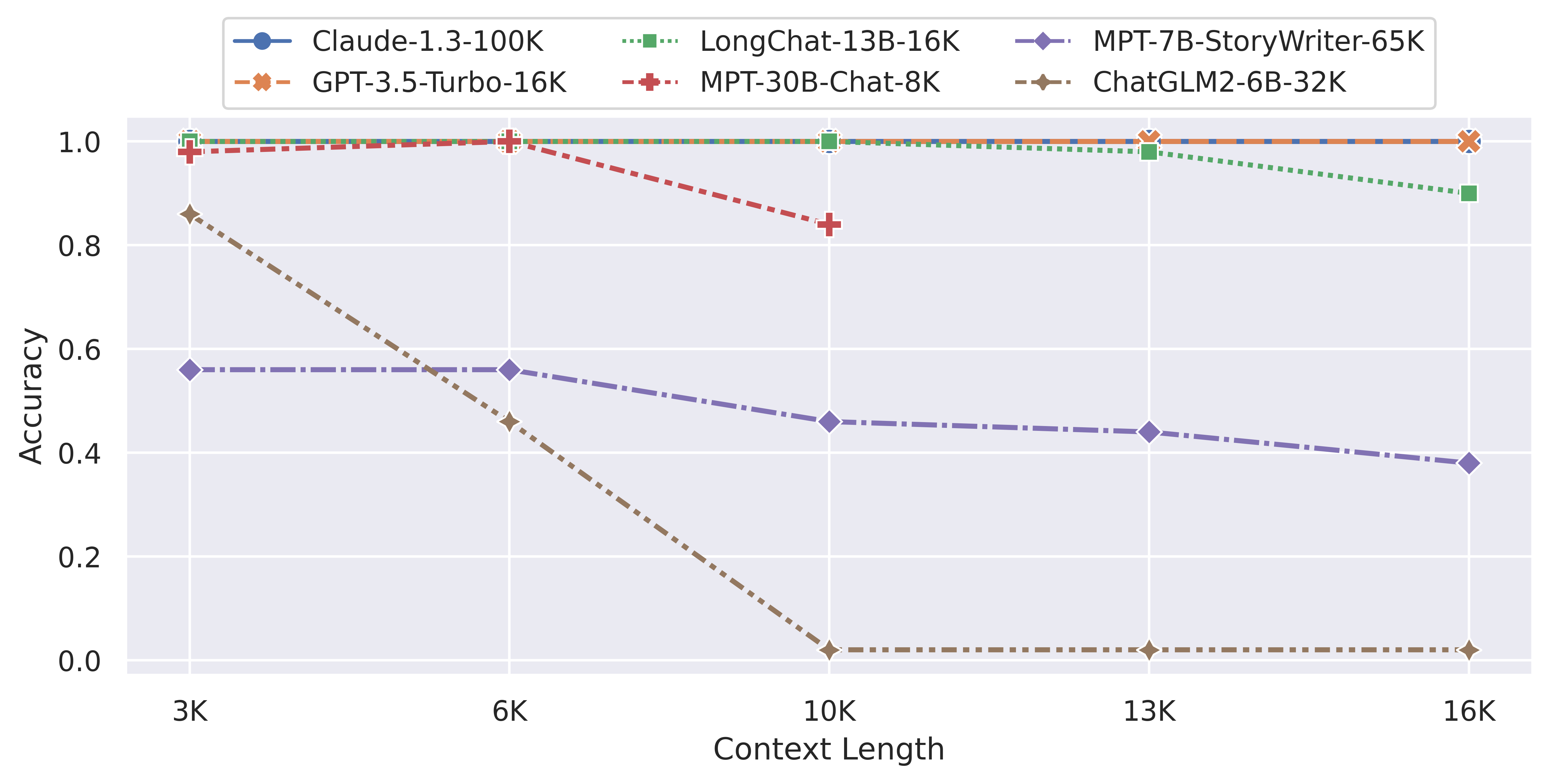
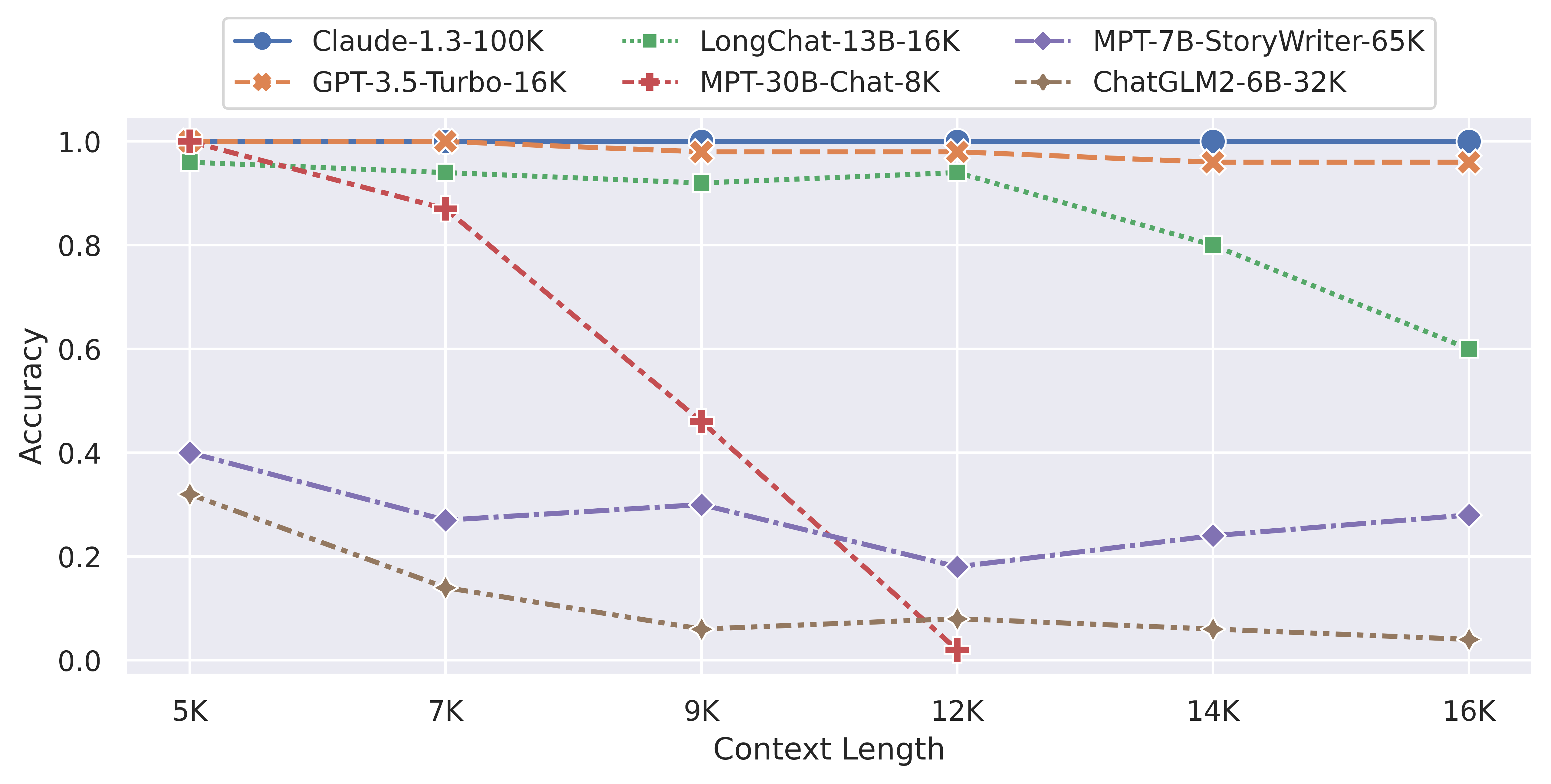
下图是超长行检索评测结果总结
上述2个任务介绍:
任务1 - 粗粒度主题检索:在现实生活中的长对话中,用户通常会与chatbot交谈和切换多个主题。主题检索任务模拟了这种场景,要求chatbot检索长对话中包含多个主题的第一个主题。
任务2 - 精细粒度行检索:为了进一步测试模型从长对话中定位和关联文本的能力,LongChat引入了一种更精细粒度的行检索测试。在这项测试中,LLM需要从长文档中精确检索出一个编号,而不是从多轮长对话中检索一个主题。
官方宣称这两个任务都是大家在使用LLM遇到的比较多的超长上下文的应用场景,代表了模型在支持现实中超长上下文使用的真实场景。
欢迎大家关注DataLearner官方微信,接受最新的AI模型和技术推送
