7种交叉验证(Cross-validation)技术简介(附代码示例)
交叉验证是一种用于估计机器学习模型性能的统计方法。它是一种评估统计分析结果如何推广到独立数据集的方法。简单来说,就是将数据集分成不同的部分,然后某些部分训练,某些部分测试,某些部分验证,这样可以最大程度避免过拟合以及测试模型在陌生数据集的性能。

一、概述
在交叉验证中,我们使用我们的初始训练数据来生成多个小型的训练-测试分片。使用这些分片来调整你的模型。例如,在标准的k-fold交叉验证中,我们将数据划分为k个子集。然后,我们在k-1个子集上反复训练算法,同时使用剩下的子集作为测试集。通过这种方式,我们可以在完全未见过的数据上测试我们的模型。本文将介绍7种最常用的交叉验证技术以及它们的优点和缺点。并且会有每种技术的代码片段。
二、HoldOut Cross-validation(Train-Test Split)
在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法。
优点:很简单很容易执行。
缺点1:不适用于不平衡的数据集。假设我们有一个不平衡的数据集,有0类和1类。假设80%的数据属于 "0 "类,其余20%的数据属于 "1 "类。这种情况下,训练集的大小为80%,测试数据的大小为数据集的20%。可能发生的情况是,所有80%的 "0 "类数据都在训练集中,而所有 "1 "类数据都在测试集中。因此,我们的模型将不能很好地概括我们的测试数据,因为它之前没有见过 "1 "类的数据。
缺点2:一大块数据被剥夺了训练模型的机会。
在小数据集的情况下,有一部分数据将被保留下来用于测试模型,这些数据可能具有重要的特征,而我们的模型可能会因为没有在这些数据上进行训练而错过。
sklearn中有现成的方法,代码如下:
from sklearn.model_selection import train_test_split
# iris数据集,X是特征,Y是标签
X=iris.data
Y=iris.target
# 直接划分成训练集的特征与标签,测试集的特征与标签
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)
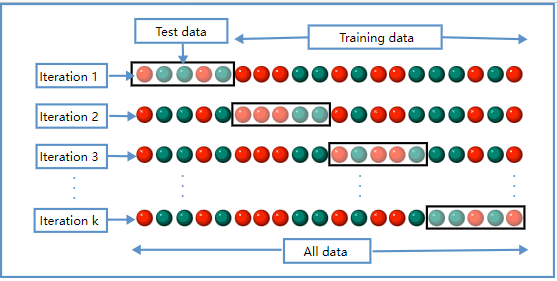
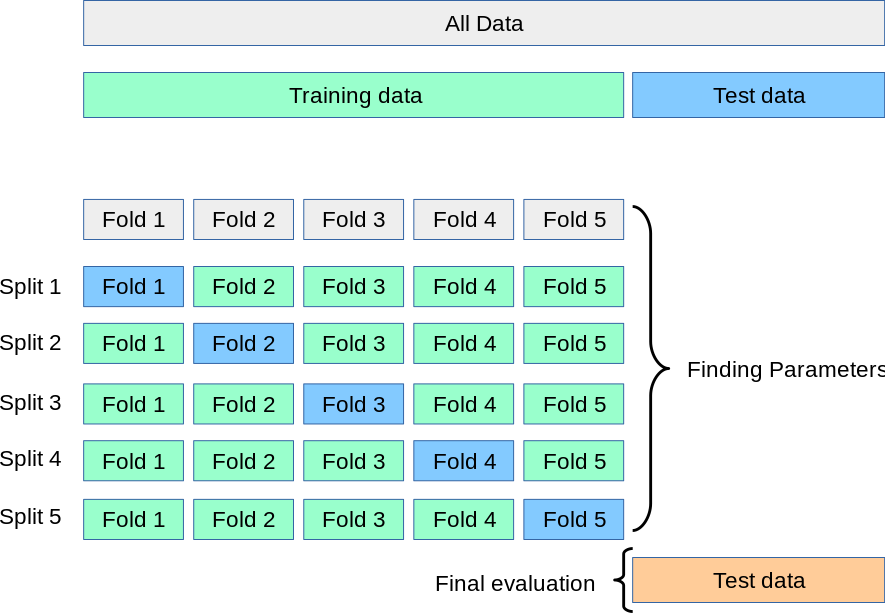
三、K次交叉验证(K-Fold Cross-Validation)
K-Fold交叉验证技术中,整个数据集被划分为K个大小相同的部分。每个分区被称为 一个"Fold"。所以我们有K个部分,我们称之为K-Fold。一个Fold被用作验证集,其余的K-1个Fold被用作训练集。
该技术重复K次,直到每个Fold都被用作验证集,其余的作为训练集。
模型的最终准确度是通过取k个模型验证数据的平均准确度来计算的。
优点:整个数据集的所有部分都会被当作训练集和测试集
缺点1:不能用于不平衡的数据集。正如在HoldOut交叉验证的情况下所讨论的那样,在K-Fold验证的情况下,也可能发生训练集的所有样本都没有 "1 "类的样本,只有 "0 "类的样本,而验证集将有 "1 "类的样本。
缺点2:不适合于时间序列数据。对于时间序列数据,样本的顺序很重要。但在K-Fold交叉验证法中,样本是按随机顺序选择的。
代码示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,KFold
iris=load_iris()
X=iris.data
Y=iris.target
kf=KFold(n_splits=5)
# 注意,这里的logreg是验证的模型对象
score=cross_val_score(logreg,X,Y,cv=kf)
四、分层K次交叉验证(Stratified K-Fold Cross-Validation)
分层K-Fold是K-Fold交叉验证法的一个增强版,主要用于不平衡数据集。就像K-fold一样,整个数据集被分为大小相同的K-fold。
但在这种技术中,每个Fold中的目标变量实例的比例与整个数据集的比例相同。
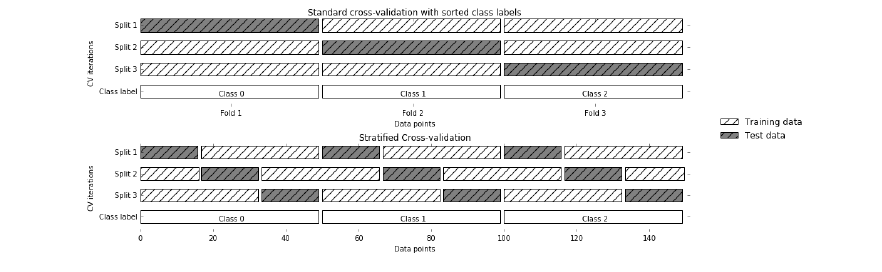
优点:对不平衡的数据有很好的作用。分层交叉验证中的每一个Fold都会有一个所有类别的数据代表,其比例与整个数据集相同。
缺点:不适用于时间序列数据。对于时间序列数据,样本的顺序很重要。但在分层交叉验证中,样本是按随机顺序选择的。
代码示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,StratifiedKFold
iris=load_iris()
X=iris.data
Y=iris.target
stratifiedkf=StratifiedKFold(n_splits=5)
# 注意,这里的logreg是验证的模型对象
score=cross_val_score(logreg,X,Y,cv=stratifiedkf)
五、Leave P Out cross-validation
Leave P Out交叉验证是一种exhaustive的交叉验证技术,其中p个样本被用作验证集,其余n个样本被用作训练集。
假设我们在数据集中有100个样本。如果我们使用p=10,那么在每次迭代中,10个样本将被用作验证集,其余90个样本作为训练集。
这个过程重复进行,直到整个数据集被划分为p-样本的验证集和n-p训练样本。
优点:所有的数据样本都被用作训练和验证样本。
缺点1:速度慢。由于上述技术将不断重复,直到所有的样本都被用作验证集,所以它的计算时间会比较长。
缺点2:不适合不平衡的数据集。和K-Fold交叉验证法一样,如果在训练集中我们只有一个类别的样本,那么我们的模型将无法对验证集进行归纳。
from sklearn.model_selection import LeavePOut,cross_val_score
from sklearn.datasets import load_iris
iris=load_iris()
X=iris.data
Y=iris.target
lpo=LeavePOut(p=2)
lpo.get_n_splits(X)
# 注意,这里的tree是验证的模型对象
score=cross_val_score(tree,X,Y,cv=lpo)
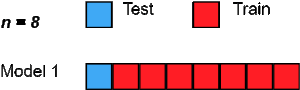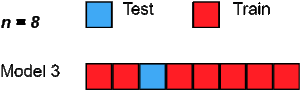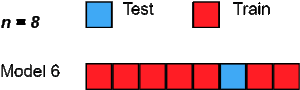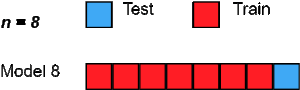
六、Leave One Out cross-validation
Leave One Out交叉验证是另一种exhaustive交叉验证技术,其中1个样本点被用作验证集,其余n-1个样本被用作训练集。
假设我们在数据集中有100个样本。那么在每个迭代中,1个样本将被用作验证集,其余99个样本作为训练集。因此,这个过程不断重复,直到数据集中的每个样本都被用作验证点。
这与P=1的LeavePOut交叉验证相同。但是相比较Leave P Out的方法来说,它需要的计算时间更少。因此,其优缺点与前面类似,就不重复了。
from sklearn.datasets import load_iris
from sklearn.model_selection import LeaveOneOut,cross_val_score
iris=load_iris()
X=iris.data
Y=iris.target
loo=LeaveOneOut()
score=cross_val_score(tree,X,Y,cv=loo)
七、蒙特卡罗交叉验证(Monte Carlo Cross-Validation)
蒙特卡洛交叉验证法,也被称为Shuffle交叉验证法,是一种非常灵活的交叉验证策略。在这种技术中,数据集被随机地划分为训练集和验证集。
我们已经决定了我们希望用作训练集的数据集的百分比和用作验证集的百分比。如果训练集和验证集的百分比之和不超过100,那么剩下的数据集就不会用于训练集或验证集。
假设我们有100个样本,60%的样本被用作训练集,20%的样本被用作验证集,那么剩下的20%(100-(60+20))将不被使用。
这种分割将被重复'n'次,这个值是我们手动指定的。
优点1:我们可以自由地使用训练集和验证集的大小。 优点2:我们可以选择repetitions的数量,而不依赖于重复的fold数量。
缺点1:少数样本可能不会被选入训练集或验证集。 缺点2:不适合不平衡的数据集。在我们定义了训练集和验证集的大小之后,所有的样本都是随机选择的,所以可能会发生训练集没有测试集中的那一类数据的情况,而模型将无法对未见过的数据进行归纳。
from sklearn.model_selection import ShuffleSplit,cross_val_score
from sklearn.datasets import load_iris
logreg=LogisticRegression()
shuffle_split=ShuffleSplit(test_size=0.3,train_size=0.5,n_splits=10)
# 注意,这里的logreg是验证的模型对象
scores=cross_val_score(logreg,iris.data,iris.target,cv=shuffle_split)
八、时间序列交叉验证(Time Series Cross-Validation)
时间序列数据是在不同时间点上收集的数据。由于数据点是在相邻的时间段收集的,因此观察结果之间有可能存在关联性。这是区分时间序列数据和截面数据的特征之一。
在时间序列数据的情况下,如何进行交叉验证?
在时间序列数据的情况下,我们不能选择随机样本并将其分配到训练集或验证集,因为使用未来数据的值来预测过去数据的值是没有意义的。
由于数据的顺序对于时间序列相关的问题非常重要,所以我们根据时间将数据分成训练集和验证集,也被称为 "前向链 "方法或滚动交叉验证。
我们从一个小的数据子集开始,作为训练集。基于这个数据集,我们预测以后的数据点,然后检查准确性。
然后,预测的样本被作为下一个训练数据集的一部分,并对后续的样本进行预测。
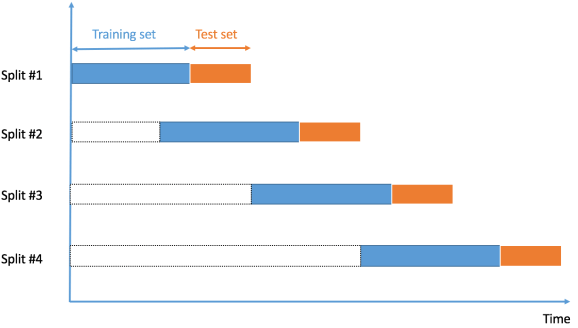
优点:适合时间序列数据集。
缺点:不适合于其他数据类型的验证。在其他技术中,我们选择随机样本作为训练或验证集,但在这种技术中,数据的顺序是非常重要的。
代码如下:
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
time_series = TimeSeriesSplit()
print(time_series)
for train_index, test_index in time_series.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
其实,这个也有其它一些手动方法,比如可以参考kaggle time series比赛第一名的解决方案中有代码也是自己写的抽样。大致思想是每一个时间序列随机选择起始数据点,然后把序列长度跟在后面取到这些数据点就可以,非常灵活(kaggle-web-traffic/input_pipe.py)。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
