强化学习基础之马尔可夫决策过程(Markov Decision Processes)和马尔可夫奖励过程(Markov Reward Processes)
强化学习(Reinforcement Learning)发展密切相关的一个方法就是马尔可夫决策过程(Markov Decision Processes,MDPs),这是一种离散随机过程(discrete-time stochastic control processes),它提供了一个数学框架,用于在结果部分是随机的、还有部分受决策者控制的情况下对决策进行建模。说白了,就是一种问题建模方法。它不是一种解决方法,而是针对某些问题进行建模,一旦建模完成,就可以使用例如动态规划的方法来解决这些问题。
马尔可夫决策过程可以用来描述强化学习的“环境”,且这个环境是完全可观测的(fully observable)。几乎所有的强化学习问题都可以用MDPs来形式化:
- 最优控制可以使用连续MDPs来处理
- 部分可观察问题可以转换成MDPs
- 赌博机(Bandits)问题是有一个状态的MDPs
因此,马尔可夫决策过程对于学习强化学习来说是必不可少的基础部分。本文将简要介绍这个模型及其变种马尔可夫奖励过程(Markov Reward Processes)。为了帮助理解马尔科夫决策过程,我们将从问题例子入手,讲述如何使用这个方法对问题进行建模。
一、马尔可夫性质、马尔科夫链、马尔可夫过程和马尔科夫决策过程的区别
这些名词都涉及到马尔可夫,很多时候对于刚接触的人来说容易混淆,我们先开始说一下它们的区别。
马尔可夫性质(The Markov Property)是概率论里面一种非常著名的概念,本科的概率论与数理统计以及研究生的随机过程都有涉及。马尔可夫性质指出,未来只取决于现在,而不取决于过去。
基于马尔可夫性质可以推导出很多模型,其中,马尔可夫链(Markov Chain)就是基于马尔可夫性质所得到的最著名的概率模型之一。
马尔可夫链是一个概率模型,它完全取决于当前状态,而不是以前的状态,也就是说,未来有条件地独立于过去。从一种状态移动到另一种状态称为转移,其概率称为状态转移概率。马尔科夫链通常可以用来刻画一种状态转换成另一种状态的过程,是一种经典的随机过程。
马尔可夫链是一个离散时间过程,考虑到过去和现在,未来的行为只取决于现在,而不取决于过去。马尔可夫过程是马尔可夫链的连续时间版本。许多排队模型实际上是马尔可夫过程。
而马尔可夫决策过程则是马尔科夫链的一个推广形式。它为建模决策情况提供了一个数学框架。与马尔科夫链里面只涉及状态转移概率不同,马尔科夫决策过程引入了行为或者叫动作(action)的概念。例如我们有一个离散的马尔科夫链,在链上的每一个步骤,我们都可以根据状态转移概率矩阵来决定下一次的行动。现在,在状态转移之前,我们引入一组操作,并且每个操作也都有一个概率。这就像我们找了一个代理人,这个代理人会帮助我们在转移状态之前选择执行一个操作,而不是像之前一样直接根据状态转移概率进行状态转换。执行完这个操作之后,我们可以给代理人一个奖励(reward),并且代理人转到下一个状态中。也就是说,与马尔科夫链的状态转移完全依赖于状态转移概率矩阵不同,马尔科夫决策里面引入了行动和奖励的概念,将状态的转移变成了一个部分可控的过程。
可以看到,马尔可夫决策过程比马尔科夫链多了一个action的选择,并且多了一个奖励(reward)概念,而这个reward的设置与计算就可以促使代理人选择合适的动作,以最终影响到reward,进而最大化我们的目的,这也就是强化学习的思想了。
二、实际案例
2.1、马尔科夫链的实例——学生马尔科夫链
David Silver是Deep Mind的研究科学家,也是University College London的教授。他在自己Reinforcement Learning课上举了一个例子。
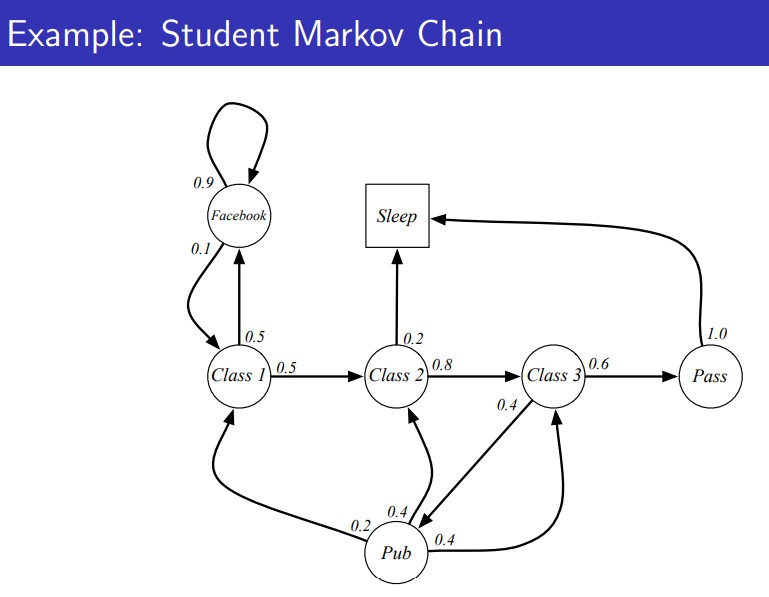
如上图所示,是使用图的形式表示学生的状态和状态转移的情况,这就是马尔科夫链,是一个学生所有可能的状态以及状态之间的转移概率。可能的状态如下:
- Facebook:浏览Facebook
- Class 1:学生学习课程1
- Class 2:学生学习课程2
- Class 3:学生学习课程3
- Pub:学生在酒吧
- Pass:学生通过课程
- Sleep:学生在睡觉
上述7中状态是学生可能的状态,其中Sleep是最终状态,也就是说到了这个状态,学生的行为停止。剩下的6中状态,学生处在任意状态,那么下一个时刻,他都可能沿着箭头方向转变成另个一状态。例如学生在学习课程1(Class 1),那么他又0.5的概率接下来去浏览Facebook,也有0.5的概率继续学习课程2(Class 2)。
像上面这种学生行为的转换,或者说是状态的转换就是一种连续决策的状态。这种马尔科夫链刻画的学生行为决策,不管学生处在哪一个状态,我们都能知道他转换到下一个状态(或者说采取的下一个行动)都是一个概率分布,且仅与当前的状态有关。而这种状态转移的概率可以很容易用一个矩阵表示,也就是状态转移概率矩阵。如下图所示:

