截止目前可能是全球最快的大语言模型推理服务:实机演示Groq公司每秒500个tokens输出的450亿参数的Mixtral 8×7B模型
大模型的推理速度是当前制约大模型应用的一个非常重要的问题。在很多的应用场景中(如复杂的接口调用、很多信息处理)的场景,更快的大模型响应速度通常意味着更好的体验。但是,在实际中我们可用的场景下,大多数大语言模型的推理速度都非常有限。慢的有每秒30个tokens,快的一般也不会超过每秒100个tokens。而最近,美国加州一家企业Groq推出了他们的大模型服务,可以达到每秒接近500个tokens的响应速度,非常震撼。
Groq大模型服务简介
首先,Groq并不是一家专门做大模型服务的初创企业,而是一家芯片公司。此前,他们的产品只在小部分人中得知。为了让更多的人了解他们的芯片的强大,他们发布了大语言模型服务,目前托管了三个开源模型,分别是Mixtral 8×7B - 32K、Llama2-70B-4K和Mistral 7B - 8K。这三个模型也是当前最强的开源模型之一。
而Groq的这三个模型最大的特点是速度非常快,其中Mixtral 8×7B - 32K作为一个有450多亿参数(推理时有120亿参数被使用)的模型,其生成tokens的速度最高达到每秒500个tokens左右,正常也有400多个tokens,这意味着它每秒可以生成400个单词左右,可以说是飞速生成。
下图是我们测试的一个逻辑推理问题:

可以看到,它不仅回答了问题,也给出了生成的速度,每秒488.64个tokens!接下来我们测试了一个更长的输出结果:

用中文讲一个1000字左右的故事,故事大概是一个中国的古代的龙,生活在一个美丽的地方,它喜欢到处游玩,有一次遇到了一个村庄,遭受恶魔侵害,它与恶魔战斗,非常惨烈,但是 最终赢得了战斗。故事情节需要跌宕起伏,且幽默
正常情况下,模型输出越长,可能速度也越慢,但是从上面结果看,尽管这个输出已经很长了,但是它生成速度依然达到了每秒452.59个tokens!非常迅速。
至于生成内容的准确性,那是由模型决定,但是从这里也可以看到Groq芯片的强大。使用Llama2-70B速度则满了许多,每秒283个tokens左右,但是也是业界目前最快的速度了。
Groq大模型推理速度以及接口价格与其它厂商的对比
Groq大模型推理速度与其它厂商对比
虽然Groq大模型的服务推出时间非常短,但是已经引起了广泛的关注和讨论。其中ArtificialAnalysis.ai则是公布了他们监控的主流厂商大模型推理速度对比结果,如下图所示:

这是从去年12月中旬依赖各大不同厂商的大模型推理速度对比监测结果。包括MistralAI、PerplexityAI、Fireworks等。但是,大多数厂商的模型推理速度都在每秒50个tokens附近,Fireworks在最近速度提升后达到了每秒150个tokens左右。但是与Groq对比差距非常明显。右上角那个超过所有厂商的速度就是Groq。注意,这里都是Mixtral 8×7B模型的对比。只能说,遥遥领先!
Groq大模型推理价格与其它厂商对比
除了Groq的推理速度快意外,他们也提供了API供大家使用。而且定价也非常划算。如下图所示:
|模型名称|当前推理速度|每100万tokens价格 (输入/输出)| 每100万tokens总价 | |:----|:----|:----| |Llama 2 70B (4096 Context Length)|~300 tokens/s|$0.70/$0.80| 1.5美元| |Llama 2 7B (2048 Context Length)|~750 tokens/s|$0.10/$0.10|0.2美元| |Mixtral 8x7B SMoE (32K Context Length)|~480 tokens/s|$0.27/$0.27|0.54美元|
可以看到,对于使用Mixtral 8x7B SMoE-32K来说,100万个tokens才0.54美元非常划算。与其它厂商价格对比如下:
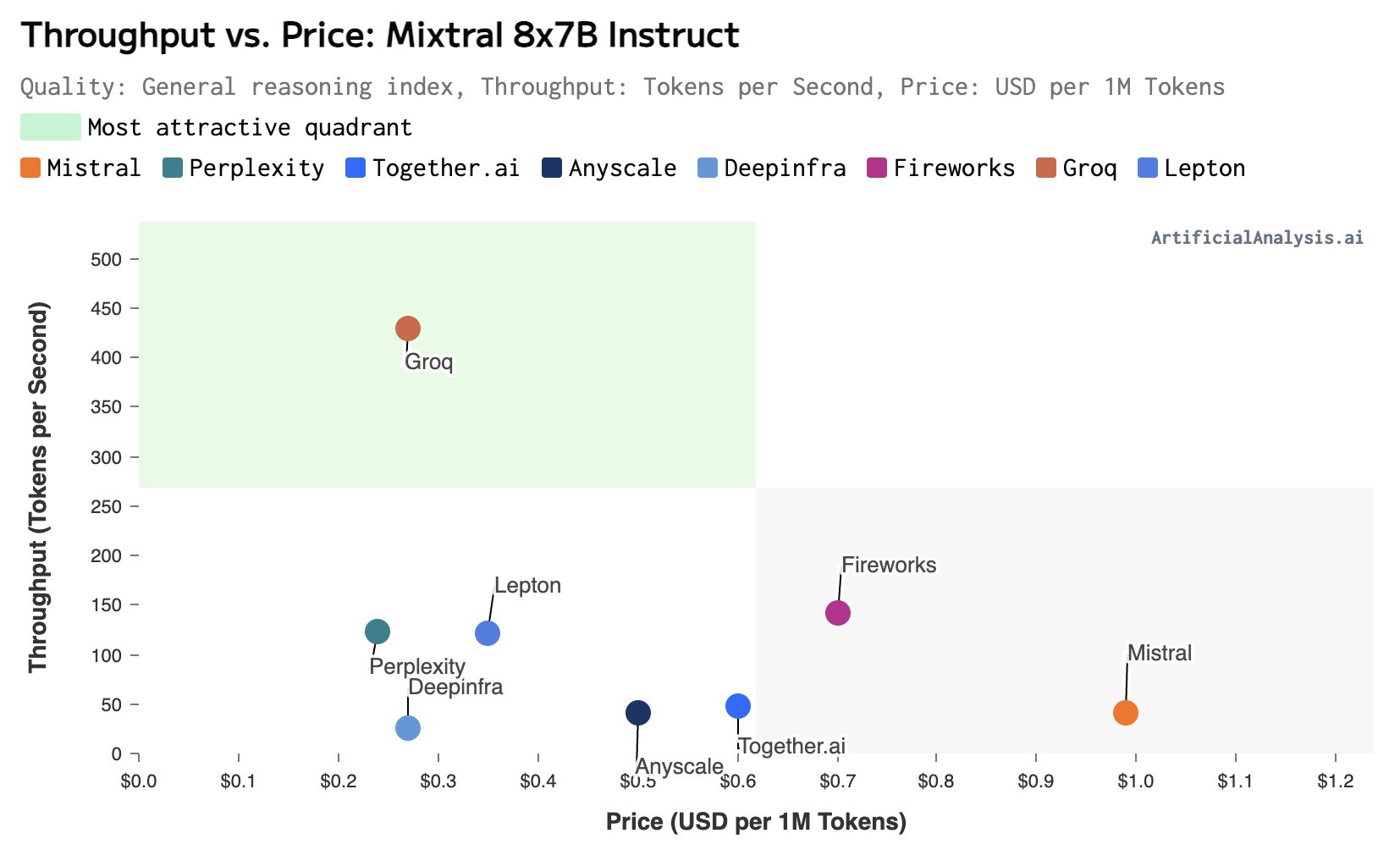
这里纵轴是速度,一骑绝尘,横坐标是价格,几乎是最低,只比Perplexity贵一点点!
Groq公司简介以及为什么Groq公司的大模型推理速度这么快?
Groq公司是由谷歌前雇员Jonathan Ross创建的企业,在加州成立于2016年。最近的融资时在C轮融资,有27为投资人(机构)。
Jonathan Ross也是谷歌TPU最早的团队成员。TPU在谷歌内部取得了巨大成功,最终支撑了谷歌50%以上的计算能力。当其他超规模生产商得知这一成功后,他们也试图雇佣Jonathan为他们制造定制芯片。
在这个过程中,Jonathan越来越清楚,有权使用下一代计算的公司和没有的公司之间会出现差距。因此,他创立了Groq,并着手制造一种人人都能使用的芯片。
Groq公司首创了业界所谓的Language Processing Unit(LPU),目的时用来加速大语言模型的推理。从前面的测试看,Groq的LPU的确是目前最快的大语言模型推理处理器了。
Groq大模型推理服务体验地址:https://groq.com/
目前,他们托管的服务不需要登录就可以体验。
