微软发布第四代Phi系列大模型,140亿参数的Phi-4 14B模型数学推理方面评测结果超过GPT 4o,复杂推理能力大幅增强
Phi大语言模型是微软发布的一系列小规模大语言模型,其主要的目标是用较小规模参数的大语言模型达成较大参数规模的大语言模型的能力。就在今天,微软发布了Phi4-14B模型,参数规模仅140亿,但是数学推理能力大幅增强,在多个评测基准上甚至接近GPT-4o的能力。
Phi-4-14B模型简介
微软将大语言模型分为两类,参数较小的规模被称为小语言模型(Small Language Models, SLMs)。微软认为,使用高质量的数据集训练小规模参数语言模型,以达成更高的推理能力是很重要的一个方向。为此,微软发布了Phi系列的大语言模型。
在2023年6月份,微软开源了第一代Phi模型,这个模型参数规模仅有13亿,这是一个纯粹的编程大模型,但是效果不错,三个月后,微软发布Phi-1.5模型,在Phi-1代码补全的基础上增加了模型推理能力和语言理解的能力,参数量不变。随后,2023年年底微软开源了Phi-2模型,这个模型的参数增长到27亿,但是MMLU评测结果超过了LLaMA2 13B,让大家十分惊叹。2024年4月份,微软发布了Phi-3系列SLM,最高参数达到140亿,性能接近Mixtral-8×22B-MoE这样更大规模参数的模型。2024年8月份,微软发布了Phi-3.5系列模型,增加了多模态和混合专家架构,模型能力更强。而4个月后的今天,微软发布了全新的Phi 4 - 14B模型,大幅增强了数学推理能力。
Phi-4-14B模型的参数规模140亿,上下文长度(context length)在预训练阶段是4096。在预训练之后的中期训练(midtraining)阶段,上下文长度被扩展到了16384(即16K)。
Phi-4 是一款在数学推理方面表现出色的先进模型,超越了同类和更大规模的模型。其成功归功于几个关键创新:
-
合成数据用于预训练和中期训练(Synthetic Data for Pretraining and Midtraining):
- phi-4的训练过程中大量使用了合成数据,这些数据通过多种技术生成,包括多代理提示(multi-agent prompting)、自我修订工作流程(self-revision workflows)和指令反转(instruction reversal)。这些方法能够构建出能够激发模型更强推理和问题解决能力的数据库,解决了传统无监督数据集中的一些弱点。
- 合成数据在phi-4的预训练和中期训练中占据了主导地位,并且经过精心设计以确保多样性和相关性,以提高模型在推理和问题解决方面的性能。
-
精选和过滤高质量有机数据(Curation and Filtering of High-Quality Organic Data):
- 研究团队精心挑选和过滤有机数据源(就是实际自然存在的数据),包括网络内容、授权书籍和代码库,以提取用于合成数据管道的种子,这些种子鼓励深度推理并优先考虑教育价值。
- 除了直接用于预训练的高质量数据外,还过滤网络以寻找高质量数据(以知识和推理为依据),直接用于预训练。
-
后训练(Post-Training):
- phi-4的后训练阶段通过创建新的SFT(Supervised Fine-Tuning)数据集和开发基于关键令牌搜索的DPO(Direct Preference Optimization)对技术,进一步提升了模型性能。
- 后训练的目标是将预训练的语言模型转变为用户可以安全交互的AI助手,通过对齐一轮SFT和DPO来实现,其中包括基于关键令牌搜索方法生成的DPO对。
这三个关键技术共同支撑了phi-4在保持参数数量相对较少的同时,实现了与更大模型相媲美的性能,尤其是在STEM(科学、技术、工程和数学)领域的问答能力上。通过这些方法,phi-4在数据质量、模型架构和后训练技术方面取得了显著进步,从而在各种基准测试中表现出色。
Phi-4-14B模型的评测效果
在多个评测基准中展现了显著优势,特别是在数学推理、生成问答、以及代码生成任务中,超越了许多同类和更大规模的模型。它的优势在于其在数学和推理任务上的高效性,同时通过对高质量数据的精心策划,推动了模型在各类任务上的综合表现。尽管在某些任务(如SimpleQA)上的表现较弱,但总体来说,Phi-4是一款高性能、均衡的模型,适用于多种应用场景,尤其是在需要精确推理和生成能力的领域。
下图展示了Phi-4-14B模型的能力提升情况:
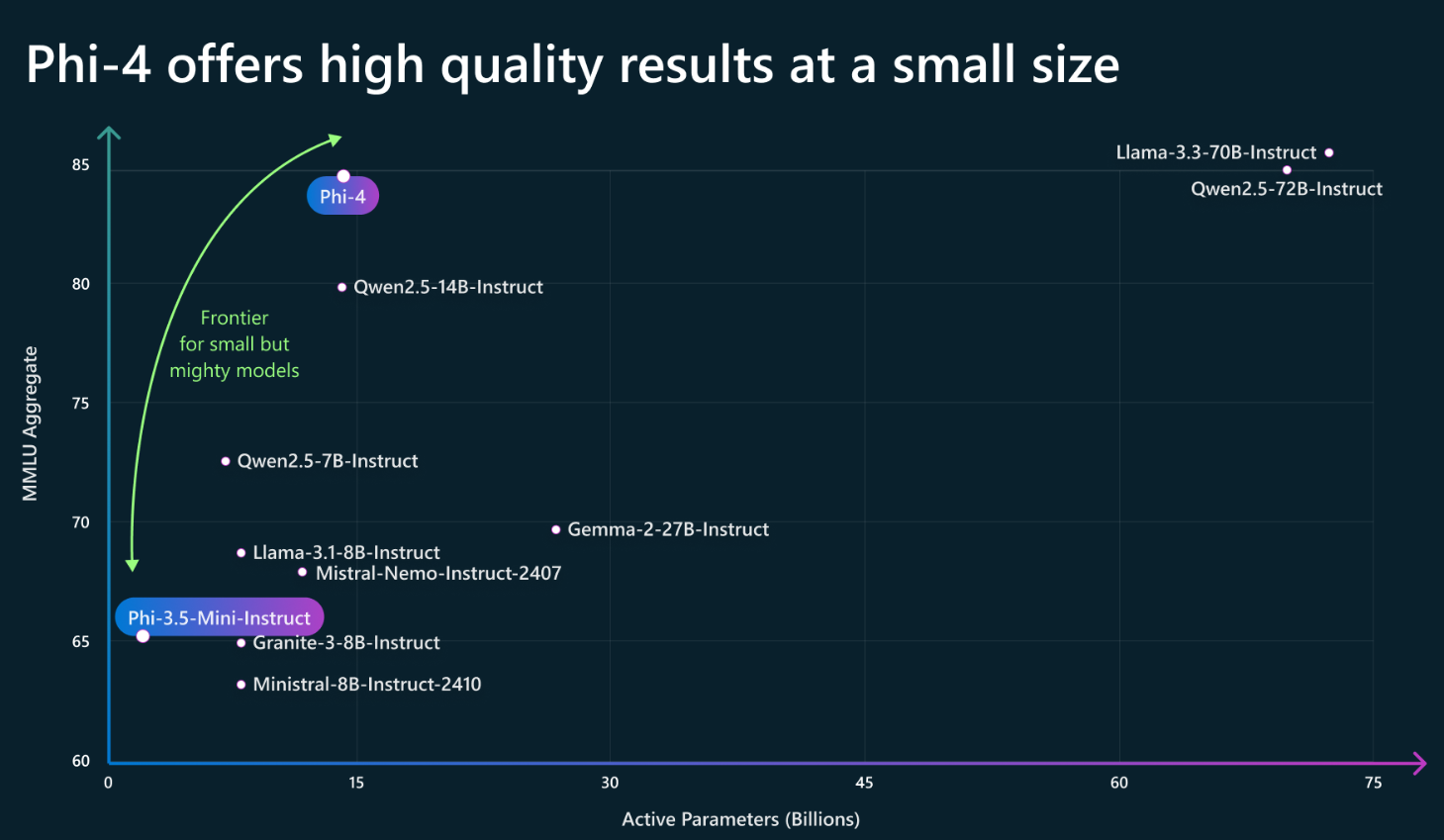
可以看到,在150亿左右参数规模的模型上,Phi-4-14B的性能一骑绝尘。Phi-4-14B的详细评测结果如下表所示:
根据DataLearnerAI收集的全球大模型评测结果排行榜,在MATH数学评测上,Phi-4-14B模型全球排名第四,而前面三个模型,分别是推理大模型DeepSeek-R1-Lite-Preview、Google最新发布的Gemini 2.0 Flash Experimental模型以及阿里发布的数学专有模型Qwen2.5-Math-72B。可以看到,Phi-4-14B在数学推理上非常强悍!
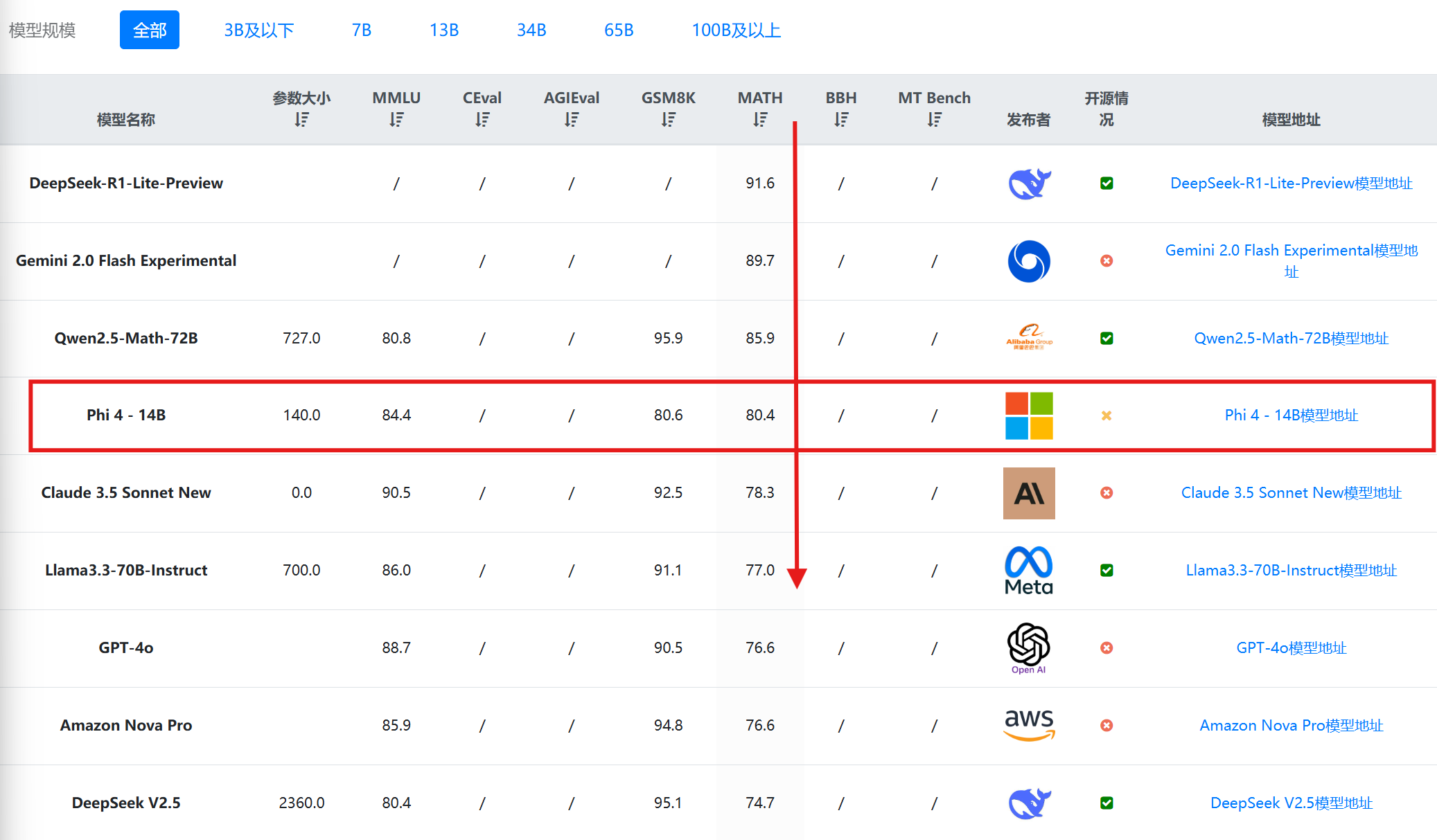
然而,Phi-4-14B在简单问答和某些极端推理任务中表现不如预期,可能过度依赖高质量的数据。此外,后训练优化的策略也可能限制其在一些快速变化的应用场景中的适用性。例如,SimpleQA得分仅为3.0,远低于其他模型(例如Qwen 2.5的9.9),这表明Phi-4在面对较为简单和直接的问答任务时可能存在不足。虽然模型在复杂任务中表现突出,但在处理简单问题时可能没有达到预期的效率或准确性。
Phi-4-14B的实际样例
官网给出了Phi4-14B模型在实际做数学题的案例:

Phi-4-14B模型的开源情况
目前Phi-4-14B的模型已经可以在微软官网使用。下周微软将会开源Phi-4-14B这个模型,但是开源协议是微软的开源研究协议,这个协议是不允许商用的,十分可惜。
关于Phi-4-14B模型参考DataLearnerAI模型的信息卡:https://www.datalearner.com/ai-models/pretrained-models/phi-4-14b
