Anthropic发布Claude4,全球最强编程大模型,大幅提升AI Agent系统所需的各项能力,最长可以7小时连续工作,持续工作、工具使用、记忆使用方面大幅提升
2025年5月23日,Anthropic发布了新一代大语言模型Claude 4系列,包括Claude Opus 4和Claude Sonnet 4两个版本。Anthropic的官方博客强调Claude Opus 4是当前全球最强的编程大模型,与传统聚焦于文本生成和知识问答的模型不同,Claude 4明确定位为任务执行引擎和AI Agent系统的核心组件。这次发布不仅仅是性能参数的提升,更代表了Anthropic认为AI模型从"对话助手"向"自主工作伙伴"的根本性转变。
本文将首先简单介绍一下Claude 4两个模型的基本信息,后面将着重介绍它们在AI Agent方面的能力提升。
Claude 4模型的核心特点
本次发布的2个Claude模型,分别是参数规模最大的Claude Opus 4和参数规模中等的Claude Sonnet 4,按照惯例,应该还有一个参数规模最小,速度最快的Claude Haiku 4,不在本次发布范围。
Claude 4采用了“混合推理模型”设计,提供两种运行模式:
- 即时响应模式:适用于常规交互场景
- 扩展思考模式:支持深度推理,思考过程可达64K tokens
虽然OpenAI最早推出了独立的推理大模型o系列,但是最新的Qwen、Claude、谷歌的Geimini等都是推理和非推理一个模型,通过特定的prompt或者接口参数来控制是否输出推理过程,避免了在一个系统中需要部署多个不同类型的模型。
根据官网的消息,Claude Opus 4和Claude Sonnet 4都支持多模态输入,即可以接受图片和文本的输入,训练数据的截止日期是2025年3月份,最高都支持200K的上下文输入。不过Claude Opus 4最高支持32K的输出,而Claude Sonnet 4却可以支持64K的输出。其中思考过程的最高长度和这些模型的最高输出长度是一样的,不过官方说正常情况不会产生如此长的思考过程,且开发者可以通过budget_tokens参数控制。
需要注意的是,此前Claude模型的思考过程都是完全输出,对开发者开放。但是,Claude 4模型的思考过程并不是这个策略。Anthropic介绍说,它们内部有一个小的模型会将过长的Claude 4的思考过程压缩变成思考摘要输出。但是这个比例不太高,根据官方的测试,大约只有5%的规模会触发这个压缩。此外,思考摘要的前面部分都是原始的思考过程。如果开发者想要完全的原始思考过程也可以联系Anthopic的官方销售,这意味着这部分可能是额外付费的。
关于Claude 4两个模型更多的技术信息、评测结果和官方的介绍参考DataLearnerAI的模型信息卡: Claude Opus 4模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/claude-opus-4 Claude Sonnet 4模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/claude-sonnet-4
Claude 4模型的评测结果:编程第一,其它方面略低于最强o3和Gemini 2.5 Pro
Claude 4相比较Claude 3.5系列各方面都有明显的提升,最主要的表现在复杂任务的解决和编程方面。但是其它方面与主流最强模型如OpenAI o3和Gemini 2.5 Pro等相比,没有明显优势或者略低。
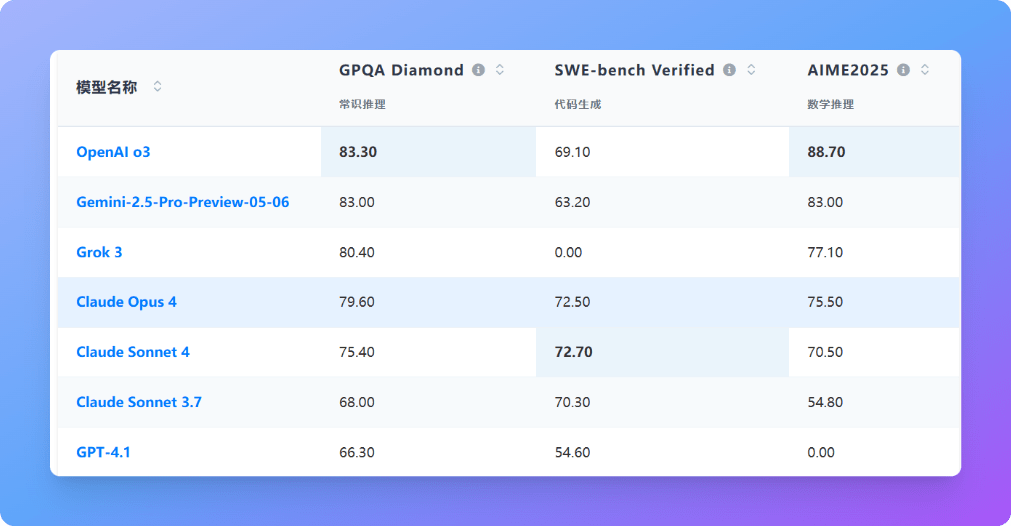
当然,这里的数据是不含额外推理过程的结果,根据官方的数据,如果Claude 4使用额外的推理,并通过抽样选择结果也可以获得比其它模型更高的得分。当然,这种能力的对比其实已经没有多大意义。
下图是官方的对比数据:
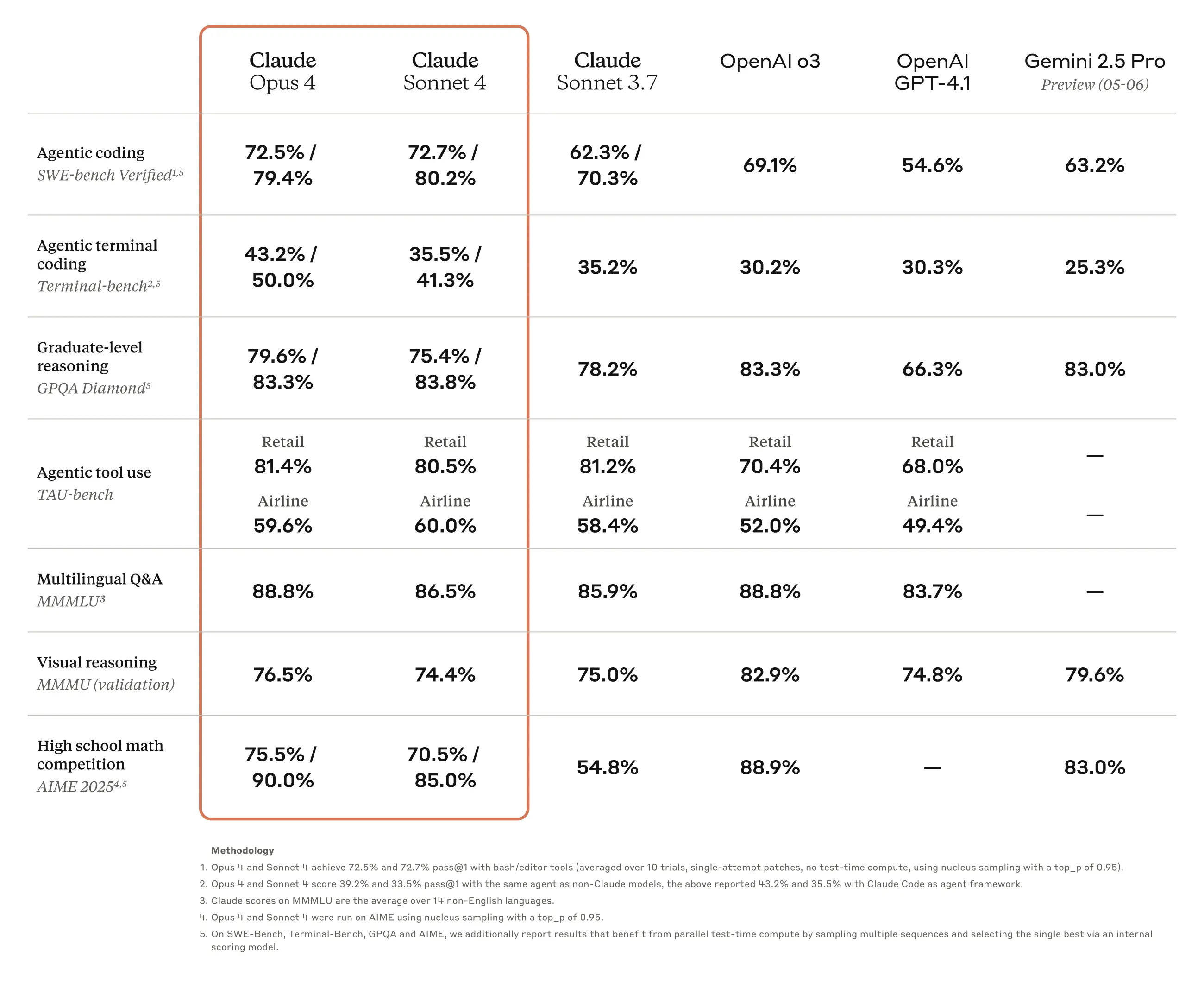
官方的说法是,它们更高的得分是让模型同时输出多个结果,并使用内部评分工具选择一个作为答案然后回答得到的。此外,这个表格我们也可以看到一些奇怪的现象,相比较Claude Sonnet 3.7,Claude Sonnet 4不加并行思考抽样结果的情况下,只有SWE-Bench Verified和AIME 2025这两个评测结果有大幅提升,但是其它方面几乎持平甚至有下降。从这些信息看,我们可以有2个方面的思考,一种情况可能是当前的评测基准已经很难全面评估模型的实际提升,特别是在指令遵从、长时间复杂任务的能力等方面。而另一个可能是也许当前大模型本身的水平已经接近当前技术能力的瓶颈,想大幅提升可能很困难。具体是哪种情况,可能需要等等看。
不过,即使不使用这种方式,在编程水平上(SWE-bench Verified详情和全部排行参考:https://www.datalearner.com/ai-models/llm-benchmark-tests/35 )得分也是远高于其它模型!这才是官方说Claude 4是最好的编程大模型原因。
Claude 4不再为Chatbot打造,专注于解决AI Agent问题
Anthropic的首席科学家Jared Kaplan表示,Anthropic从2024年底就停止投资chatbot相关技术的开发,而是专注于让模型解决复杂的任务,如检索和编程,甚至是编写整个代码仓这种复杂任务。
从Anthropic发布的Claude 4技术文档可以看出,这一代模型的设计理念和技术改进明确指向了构建更强大的AI Agent系统。无论是架构设计、能力提升还是配套工具的发布,都体现出Anthropic在AI Agent领域的战略布局和技术野心。
Claude 4最核心的Agent能力技术突破主要表现在下面几个方面:
Claude 4可以持续工作几个小时专注于解决特定的复杂任务
Claude Opus 4最突出的Agent特性体现在其持续工作能力上。根据官方数据,该模型能够:
- 连续工作数小时:具备在长时间运行任务中保持专注和性能稳定的能力
- 处理数千步骤的复杂任务:能够执行需要大量步骤的复杂工作流程
- 在长期任务中保持性能一致性:不会因为任务时长而出现性能衰减
这一能力的技术验证来自Rakuten的实际测试(日本的电商巨头乐天,以前进军过中国失败了),其开源重构项目独立运行7小时并保持稳定性能,这为Agent系统在实际生产环境中的应用提供了可靠保障。
Claude 4推理过程支持工具使用以及并行工具调用
工具使用是大模型作为AI Agent系统核心控制器最重要的能力,最早实现方式类似OpenAI的function calling。但本次Claude 4发布上在工具使用方面有了较大的提升。
首先是Claude 4引入了扩展思考期间的工具使用能力,这是Agent系统的重要突破:
- 推理与工具使用的无缝切换:模型可在深度思考过程中调用外部工具(如网络搜索)
- 工具辅助的推理优化:通过工具获取的信息能够直接参与到推理过程中,提升响应质量
这意味着Claude 4模型可以在思考过程中穿插使用工具,形成"思考→使用工具→继续思考→再使用工具"的循环模式。但是,当前主流大模型都是思考与工具使用分离,一般是思考之后选择工具,无法实现思考过程中的实时信息补充和验证。
此外,Claude Opus 4和Claude Sonnet 4两个模型都新增了并行工具使用能力,而不是以前的串行工具使用方式,这意味着Claude 4可以显著减少多工具协作场景下的等待时间。
Claude 4在记忆和上下文管理上有了很大的优化
对于真正有用的AI Agent而言,记忆能力是核心需求。Agent需要能够从过往经验中学习,建立对环境的理解,并在长期交互中保持连贯性。
当开发者为Claude提供本地文件访问权限时,Claude Opus 4展现出了创建和维护"记忆文件"的能力:
- 主动信息提取和存储:能够识别并保存关键信息
- 长期任务连续性:通过记忆文件维持跨会话的任务状态
- Agent任务性能提升:记忆系统直接改善了Agent的长期表现
注意,官方强调了Claude Opus 4在这方面表现突出,而Claude Sonnet 4没有提,可能还是稍差一点。官方提供了一个具体的应用场景:Claude Opus 4在玩Pokemon游戏时主动创建"导航指南",这个指南记录了此前失败的一些场景和经验来持续优化长期任务表现。
Claude 4指令遵循更强且减少了投机取巧的行为
在实际应用中,AI Agent有时会采用"投机取巧"的方式完成任务,比如利用系统漏洞、绕过安全检查、或者以不符合预期的方式达成目标。
官方数据显示,Claude 4模型在避免投机取巧行为方面取得重要进展,例如,相比Sonnet 3.7,在容易出现捷径和漏洞利用的Agent任务中,不当行为减少了65%。Claude 4更倾向于按照正确方式完成任务,而非寻找系统漏洞。这些提升都意味着Claude 4在构建AI Agent系统中可能更为可靠。
Claude 4的发布意味着AI Agent将是当前大模型企业的重点
Claude 4的技术设计和能力提升清晰地展现了Anthropic在AI Agent领域的战略野心。通过深入分析每项技术改进所解决的实际问题和应用场景,我们可以看到Claude 4不仅仅是性能的提升,更是对AI Agent系统实用化部署中核心挑战的系统性解答。
从持续任务执行能力解决长期Agent任务的可靠性问题,到记忆系统构建解决Agent的经验积累需求;从工具集成优化提升Agent的环境交互能力,到行为控制改进确保Agent的可靠部署——每一项技术改进都直接回应了实际Agent应用中的关键痛点。
特别值得关注的是,Claude 4不仅在单一技术维度上取得突破,更是在Agent系统所需的多个关键能力维度上实现了协调发展。这种全方位的能力提升,结合完善的开发工具链和API支持,为AI Agent技术的产业化应用奠定了坚实基础。
从技术发展趋势来看,Claude 4代表了AI模型从单纯的对话工具向智能协作Agent转变的重要里程碑,其技术架构和能力设计为未来更加复杂和自主的AI Agent系统指明了发展方向。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
