Claude Code 的独特体验:Claude Code 为什么这么好用?从设计细节看下一代 LLM Agent 的范式
近年来,AI 编码助手与 Agent 框架层出不穷,从 Github Copilot 到 Cursor,再到各种基于 LangChain 的多代理方案。然而,真正让开发者普遍感受到“顺手”与“愉快”的,却是 Claude Code(简称 CC)。它的特别之处,并不在于引入了复杂的新架构,而恰恰在于其极简而精心打磨的设计选择。
Claude模型本身的强大毋庸置疑,但是即使是相同的模型,Claude Code体验也比其它的Agent似乎体验更好。本文基于2025年8月21日vivek公开发布的一篇英文博客,结合原文分析与重组,站在第三方角度完整梳理 Claude Code 的设计要点与经验总结。

对 Claude Code 的设计方法论进行拆解后发现,CC的核心设计主要涵盖 控制循环、提示词体系、工具抽象、任务管理与交互可控性 等多个方面。
一、控制循环:极简的主线与有限的分支
Claude Code 的核心逻辑建立在一个单一的主循环之上。所有历史消息都被维护在一个扁平的消息列表中,而不是层层嵌套的多代理对话树。
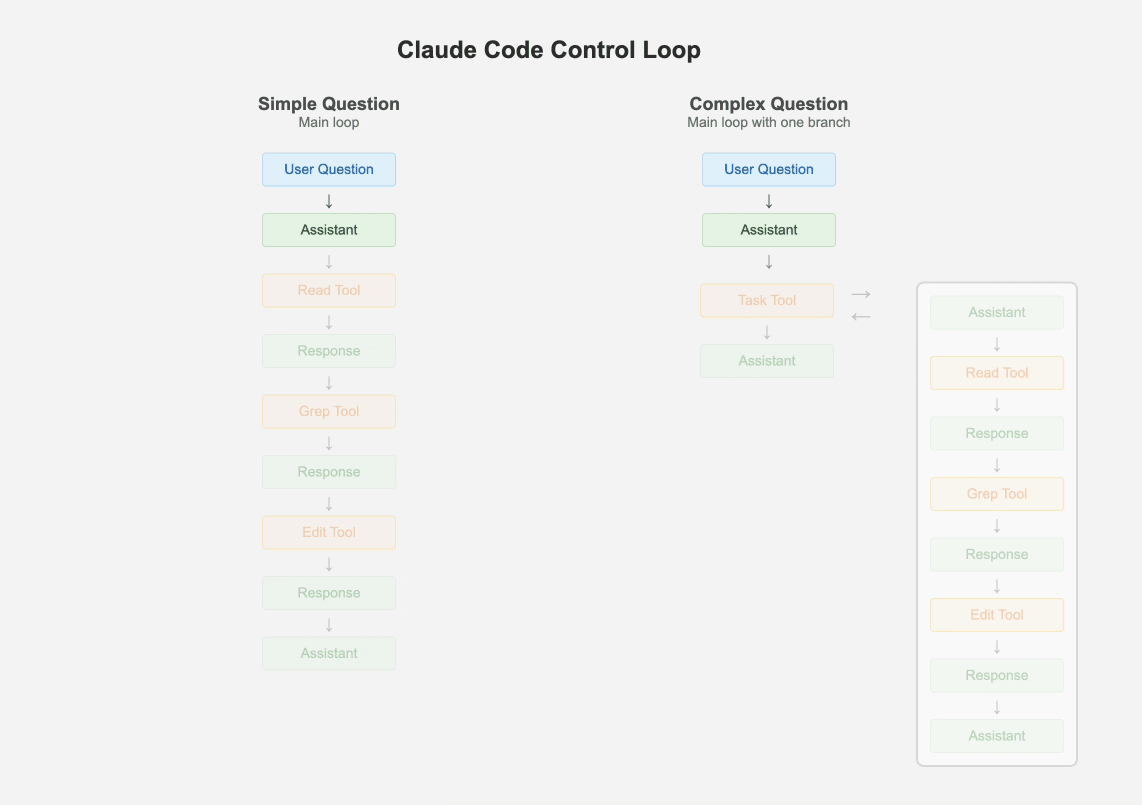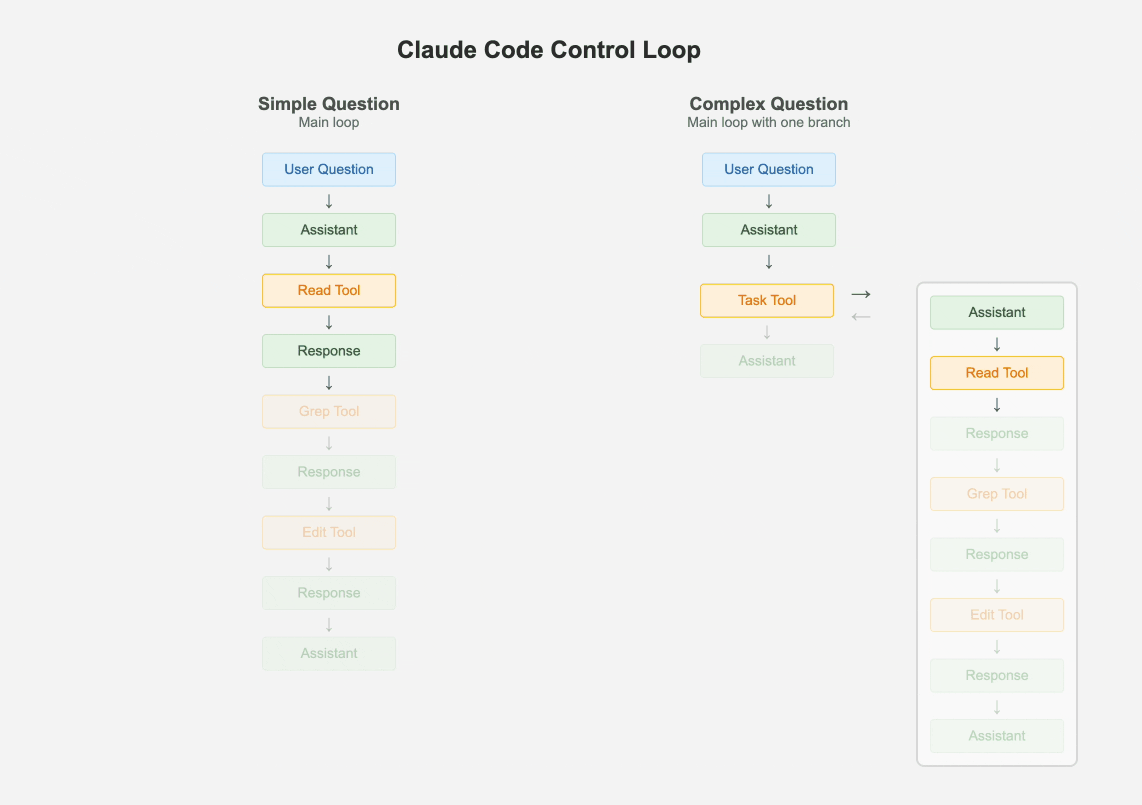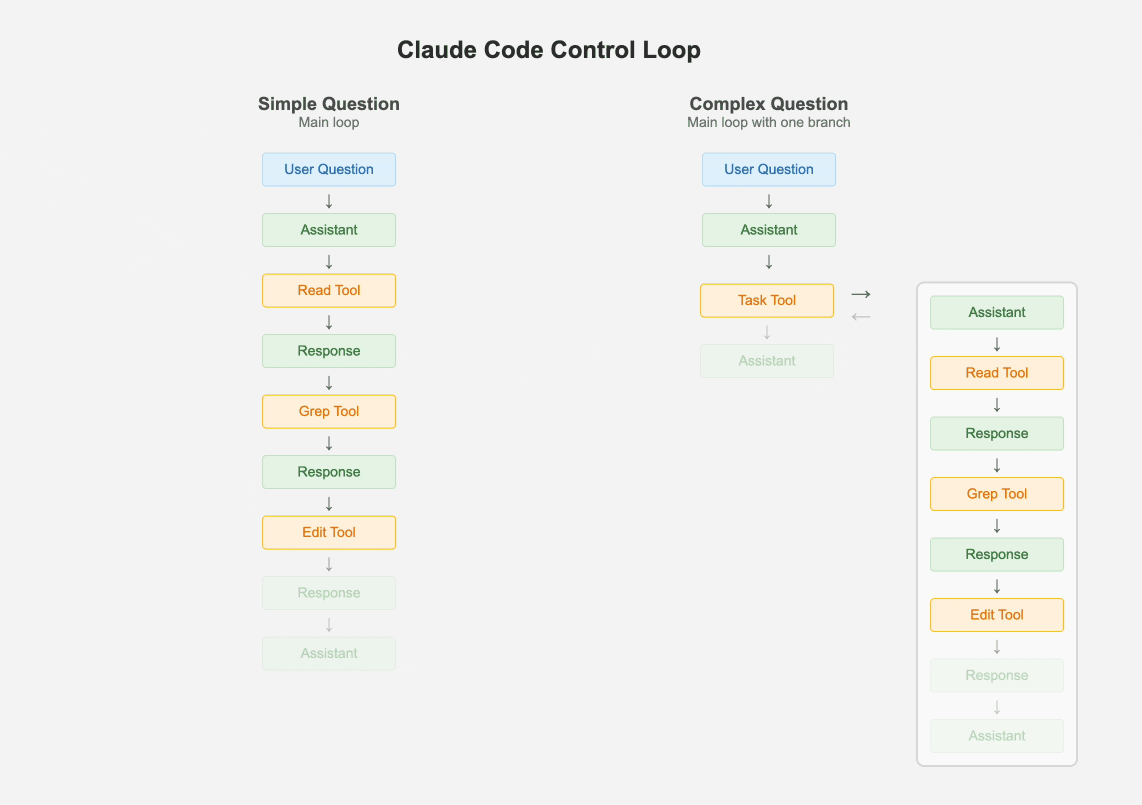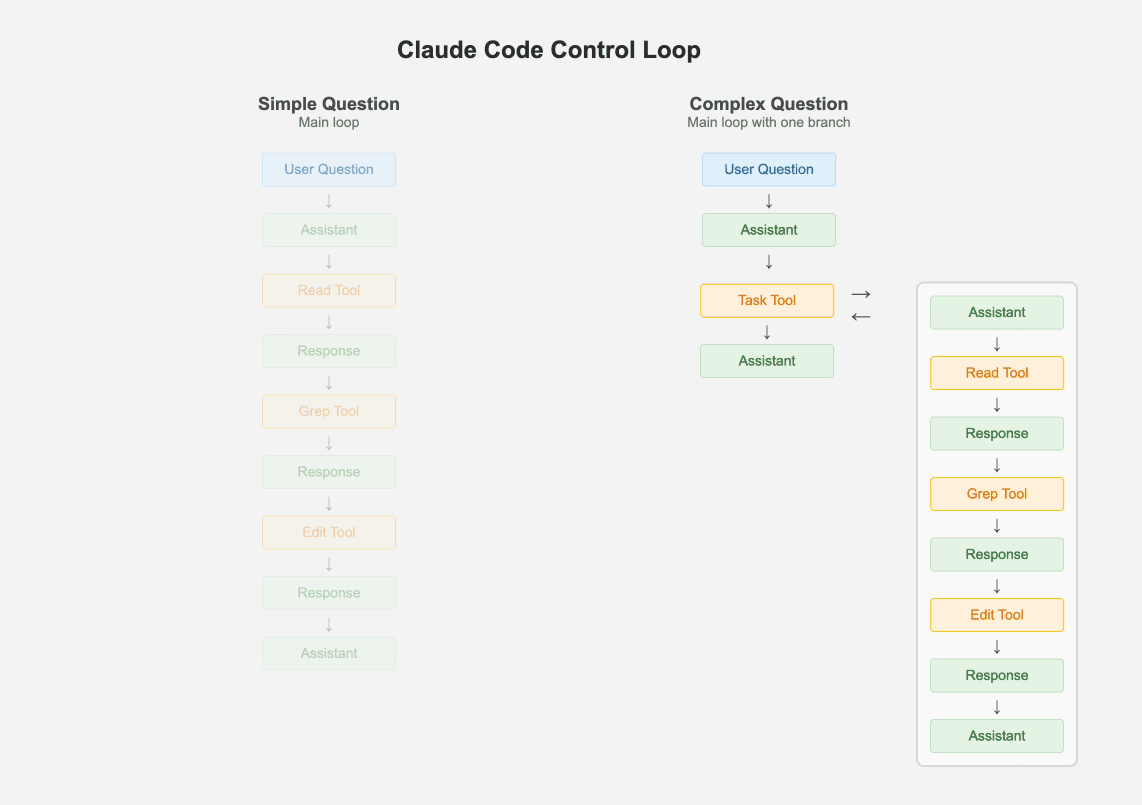
当遇到复杂问题时,CC 的策略也很克制:它可以派生出一个临时的子代理,但子代理不能再继续派生新的代理。换句话说,最多允许一层分支。子代理的结果会以“工具响应”的形式回写到主消息历史,从而保证了整个系统逻辑的可追溯性和可调试性。
这种设计既能满足任务分解的需求,又避免了多代理系统带来的不透明和调试难度。相较之下,那些依赖多层代理接力与交接验证的框架,虽然看上去复杂精巧,但往往在实际使用中容易失控。
另一个关键点是 小模型的系统性使用。在 CC 中,超过 50% 的核心调用都由 Claude-3.5-Haiku 这样的“小模型”完成。这些调用包括读取大文件、解析网页、总结 Git 历史、处理长对话,甚至是为每一次按键生成单词级状态标签。这种选择的意义在于:小模型不仅便宜(成本比 Sonnet 4 或 GPT-4.1 低 70–80%),而且在大量“低层劳动”场景下足够高效,让昂贵模型专注于决策和生成。
二、提示词体系:厚重、结构化、工程化
Claude Code 的体验优势,很大程度上来自其提示词体系的厚度与精细设计。
-
体量配置 系统提示大约 2,800 tokens;工具说明更是高达 9,400 tokens;而用户侧每次请求还会附带一个
claude.md文件,通常 1,000–2,000 tokens。整体而言,每次交互动辄上万 tokens 的提示,是支撑 CC 表现一致性的重要原因。 -
上下文文件(claude.md)
claude.md是 Claude Code 的“秘密武器”。它充当一个团队/项目规则手册,存储用户和团队的偏好:哪些文件夹应跳过、哪些库必须使用、代码风格如何统一等等。每次请求都带上完整的claude.md,让模型始终具备额外的“记忆层”。在实际测试中,有无这个文件的表现差异堪称“天壤之别”。 -
结构化标记 Claude Code 在提示词中大量使用 XML 与 Markdown:
<system-reminder>用来提醒模型任务状态,例如 TodoList 是否为空,但要求模型绝不向用户显式提及;<good-example>与<bad-example>用来固化启发式,确保在岔路口明确优劣选择,例如维持工作目录的正确方式;- Markdown 划分清晰章节,如 Tone and Style、Proactiveness、Task Management、Tool Use Policy、Doing Tasks 等,帮助模型在“人格”层面保持一致性。
-
大量示例与规则 Claude Code 的提示词中包含丰富的案例、对比、约束和提醒。例如语气要求中明确写道:不要添加不必要的解释或总结,除非用户主动要求;不要使用 emoji,除非用户提出请求;不要在拒绝时显得说教。
可以说,Claude Code 的提示词是“厚提示词工程化”的一个典型样本。
三、工具体系:从 RAG 转向 LLM 搜索
在工具设计上,Claude Code 与其他 Agent 最大的不同,是它对 RAG(检索增强生成)机制的摒弃。
Claude Code 并不依赖向量检索与重排器来提供上下文,而是通过 LLM 自己执行复杂的搜索命令(如 ripgrep、jq、find)直接在代码库中查找相关内容。
这种选择的理由包括:
- RAG 引入了大量隐性失败模式:相似度函数如何定义?如何分块?如何处理大 JSON 或日志文件?这些问题往往比 LLM 本身更脆弱。
- LLM 搜索像人类一样:先看 10 行,再看 10 行;如果需要更多,就继续读。结合小模型,既便宜又灵活。
- LLM 搜索具备可学习性:它的表现可以通过强化学习持续优化,而不会被检索模块“卡死”。
作者甚至把这种分歧类比为“相机 vs 激光雷达”之争:RAG 看似科学,但过于复杂,而 LLM 搜索则更自然、更可进化。
在工具的抽象层级上,Claude Code 采取 分层设计:
- 低层工具:Bash、Read、Write;
- 中层工具:Grep、Glob、Edit;(因为使用频率高,单独抽象比单靠 Bash 更稳定)
- 高层工具:WebFetch、
mcp__ide__getDiagnostics、mcp__ide__executeCode、ExitPlanMode 等。这类工具高度确定性,避免模型浪费在低层点击与输入上。
此外,Claude Code 的工具文档异常详尽,明确写出“何时使用哪个工具”、“当两个工具功能重叠时如何选择”,并附带正反示例。
四、任务管理:TodoList 作为“锚点”
长期运行的 LLM Agent 常见问题是“上下文腐烂”:一开始很有条理,逐渐就跑偏。Claude Code 的解决方案是 让模型自己维护 TodoList。
这份 TodoList 并不是由另一个代理生成的,而是同一个模型显式管理。在系统提示中,它被反复强调必须频繁检查与更新。这样一来,模型既能保持任务目标,又能在过程中灵活纠偏,甚至能在实现过程中动态插入或拒绝新任务。
数据也显示:Claude Code 最常用的工具是 Edit,其次是 Read 和 TodoWrite,这正体现了编辑、读取和任务管理是它的核心工作流。
五、交互可控性:语气、约束与算法化流程
Claude Code 给人“优雅”的感觉,并不是自然产物,而是系统提示中大量约束的结果。
在 CC 的提示里,可以看到数不清的 IMPORTANT / VERY IMPORTANT / NEVER / ALWAYS:
- “IMPORTANT:不要添加任何注释,除非用户要求。”
- “VERY IMPORTANT:禁止使用
find/grep,必须用内置 Grep/Glob;禁止用cat/ls读取文件,必须用 Read/LS。” - “NEVER:不要臆造 URL,除非确定对用户有帮助。”
这些粗暴的强调语,反而是目前 LLM 可控性的最佳实践。未来模型可能会更易引导,但在当下,这种“喊话式”约束依旧最高效。
此外,Claude Code 还会为关键任务写出 完整的算法与启发式示例,而不是单纯的“注意事项列表”。例如,它会像写流程图一样,把决策点、条件、分支明确列出,甚至配上“好示例/坏示例”,让模型在执行时有一套可循的逻辑框架。
这样做的意义在于:避免提示词变成数千 Token 的“Do & Don’t 大杂烩”,因为一旦规则相互冲突,模型就会变得极端脆弱,几乎无法引入新的用例。
六、从 Claude Code 看 Agent 设计的启示
总结 Claude Code 的设计,可以提炼出几个重要启示:
- 保持简单:单主循环、最少分支,避免复杂的多代理。
- 小模型优先:大量基础任务交给小模型,既省成本又快。
- 厚提示词工程:系统提示、工具文档、上下文文件,全部做厚做全,保证一致性。
- 工具分层:高频操作抽象为单独工具,复杂任务用高层工具直达结果。
- 显式 TodoList:避免长对话跑偏,增强鲁棒性。
- 硬性约束:大量使用“IMPORTANT/NEVER/ALWAYS”,在现阶段依旧是最有效的防线。
- 算法化流程:关键任务写出决策算法与示例,而不是零散守则。
Claude Code 的价值不在“复杂炫技”,而在于极简架构 + 厚工程化提示词 + 稳定工具抽象的组合拳。它证明了:Agent 不需要花哨的多层拼装,也能在实际使用中既强大又可控。
