2026年5月份全球AI Agent产品与工程实践的最新行业方向与技术路线研究
本研究来自ChatGPT的DeepResearch,目标是洞察最新的AI Agent产品落地相关的工程技术。
执行摘要
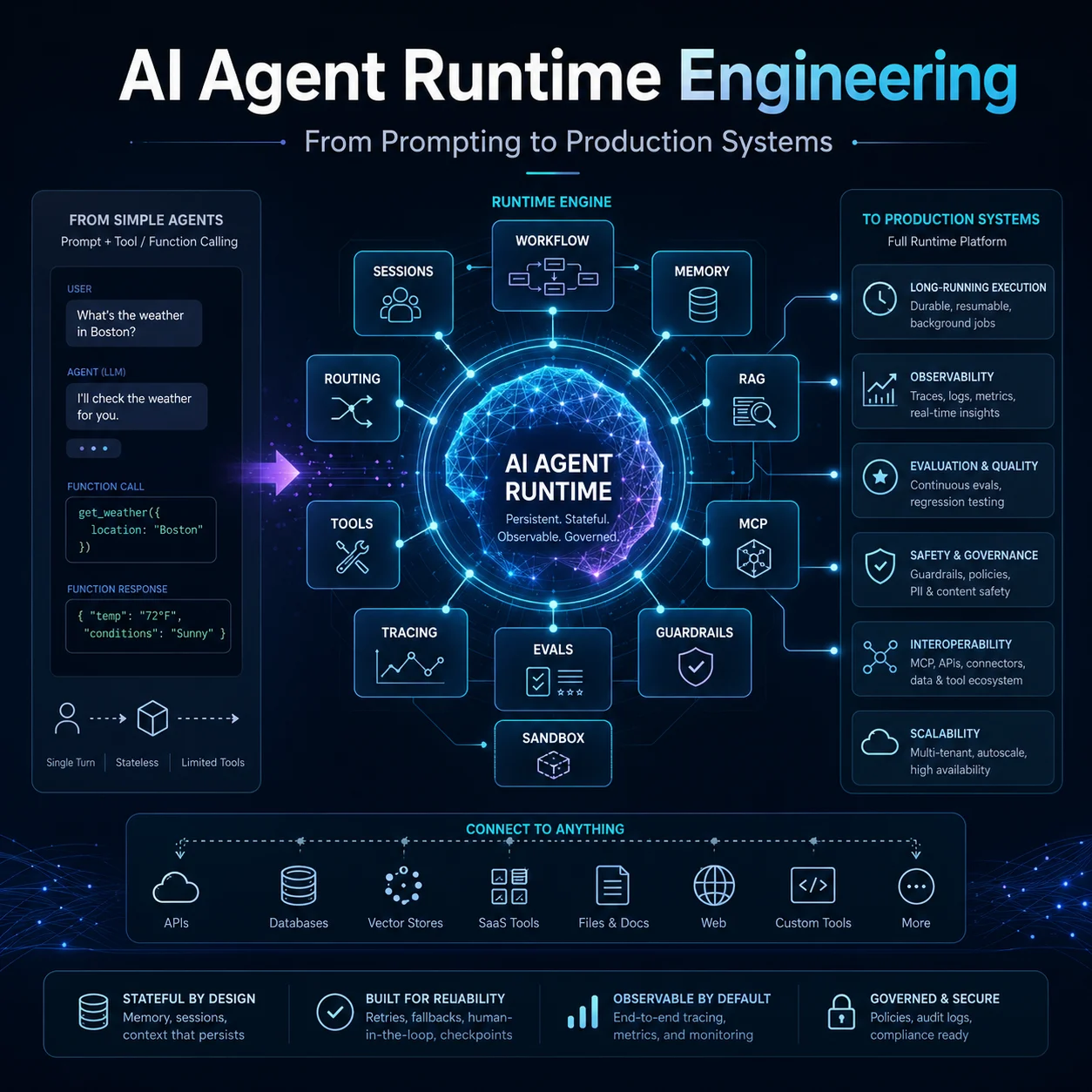
过去两年,AI Agent 的重心已经明显从“把更强模型接上几个函数”转向“把模型放进一个可恢复、可观测、可治理、可扩展的运行时系统”。最强的行业信号并不只是模型能力升级,而是 OpenAI 把 Background mode、Sessions、Agents SDK、Tracing、Evals 做成一等开发面;Anthropic 把 Skills、MCP、Memory、Compaction、Context Editing、Advisor、Managed Agents 逐步补齐;Google 把 ADK、A2A、Agent Runtime、Sessions、Memory Bank、Agent Gateway、Observability 组织成完整平台;Microsoft、LangGraph、Qwen-Agent、阿里云百炼、扣子等则分别在多智能体、可恢复执行、开源本地化、工作流平台化上补完同一条演进曲线。换句话说,行业正在把 Agent 从“提示词技巧”重新定义为“运行时工程”。
本报告给出的总体判断是:对大多数产品团队,最优先的不是上来就做任意自治的多智能体,而是先把七件事做扎实:长时运行与上下文工程、Grounding 与 Agentic RAG、工具与协议互操作、安全与执行隔离、评测与可观测、编排与模型路由、开发者体验与部署基础设施。Anthropic 明确建议先找“最简单可行方案”,并区分 workflow 与 agent;OpenAI 则把多智能体拆成 handoffs 与 agents-as-tools 两种清晰模式;阿里云百炼也将 Agent、Workflow、高代码应用并列为三类模式。一个跨平台的共识已经形成:先 workflow,后 agent;先 eval,后自治;先治理边界,后放权。
在优先级上,本报告将“长时运行与上下文工程”“Grounding 与 Agentic RAG”“评测与可观测闭环”“安全/权限/执行隔离”放在第一层,因为这些能力直接决定产品是否能从 demo 进入生产。缺少持久会话、检查点、上下文压缩与状态恢复,Agent 会在多轮和长任务中失忆、漂移或重做;缺少 grounding,Agent 无法可靠处理新信息与私有知识;缺少 eval 与 tracing,团队无法知道该优化模型、工具、检索还是提示;缺少 sandbox、approval、policy gateway,任何带副作用的 Agent 都很难通过企业风险审查。OpenAI、Anthropic、Google 三家官方文档都把这些能力前置成平台级特性,而不是“附加组件”。
成本优化的主流方向也已发生变化。行业不再主要依赖“换更小模型”这一单一策略,而是组合使用提示缓存、上下文编辑、工具动态加载、模型路由、级联、以及 advisor-executor 双模型模式。Anthropic 的 Tool Search 文档显示,多服务工具定义可轻易吞掉约 55k tokens,而动态按需加载通常可减少 85% 以上工具上下文;OpenAI 的 Prompt Caching 文档称可将输入成本最多降低 90%、延迟最多降低 80%;Anthropic 的 Advisor tool 则把“高智模型只做中途策略指导、低成本模型生成主体输出”做成内建模式。成本/时延优化已经从“模型选择”扩展成“运行时与上下文优化”。
如果只给产品团队一句总建议,那就是:把 Agent 视为“带外部动作能力的可恢复工作流系统”,而不是“会自己想办法的聊天模型”。真正构成护城河的,往往不是框架名,而是你对任务成功标准、工具接口、状态层、审批边界、评测闭环和部署运行时的工程化程度。Anthropic 明确提醒框架容易制造不必要抽象;LangGraph、OpenAI Agents SDK、Google Agent Platform 的方向也都在证明:业务成败最终取决于 runtime、traces、evals、state 和 policy,而不是“用了多少 agent”。
研究方法与证据基础
本报告以 官方文档、官方工程博客、技术报告与近两年的 benchmark/paper 为主证据,优先使用 Anthropic、OpenAI、Google Cloud、Microsoft AutoGen、Model Context Protocol 官方规范,以及最近两年的公开 benchmark(OSWorld、τ-bench、BFCL、SWE-bench Verified、TheAgentCompany)。同时补入中文官方来源,包括阿里云百炼、扣子、Qwen-Agent 与 Qwen Code,用于观察中国市场在工作流平台化、MCP 接入、技能体系和本地/开源化方面的工程实践。
相较于用户列出的关注点,本报告额外强化了三个“经常被低估、但已经成为主流平台内建能力”的方向。其一是上下文工程与状态耐久化:Anthropic 在 2025 年明确将“context engineering”从 prompt engineering 区分出来;LangGraph、OpenAI、Google 也都把 durable execution、sessions、resume、background mode 前置到 runtime 层。其二是协议互操作:MCP 正在成为工具/数据接入标准,而 Google 推出的 A2A 则试图把 agent-to-agent 通信标准化。其三是执行隔离与治理:从 Claude Code、Codex 到 Google Agent Gateway,行业都在把 sandbox、审批、审计和 IAM 视为生产级 Agent 的硬条件。
上面的时间线并非指单一厂商节奏,而是综合多个官方平台后形成的行业共振:Anthropic 在 2024 年末公开“building effective agents”,2025 年陆续发布多智能体研究系统、context engineering、long-running harnesses、writing tools for agents,并在 2026 年文档中把 Advisor、Memory、Skills、Compaction、Context Editing 纳入标准栈;OpenAI 在 2025 年把 Responses API、built-in tools、Agents SDK、Tracing、Evals 作为基础设施推出,并在 2026 年文档中强化 Background mode、Sandbox Agents、Guardrails 与会话状态策略;Google 则在 2025-2026 年把 ADK、A2A、Agent Runtime、Sessions、Memory Bank、Agent Gateway、Topology 与 Observability 组织为完整的 Agent 平台。
行业演进与优先级判断
对大多数预算、行业、技术栈都未预设的产品团队,我建议把资源投入按下表排序。排序依据不是“学术上最酷”,而是对真实产品成功率、可控性、单位经济和交付风险的边际影响。特别需要强调的是:多智能体和复杂编排并不排在最前面。Anthropic 的多智能体系统实践指出,早期版本经常为简单查询创建过多 subagent、无休止搜索、彼此干扰;这意味着如果没有前面的状态、工具、评测与安全层,多智能体只会放大复杂性。
这个参考架构几乎就是今天主流 Agent 平台的“公约数”:OpenAI 把 handoffs、guardrails、sessions、sandboxes、traces 分层暴露;Anthropic 把 Skills、MCP、Memory、Compaction、Advisor、Managed Agents 组织成工具与上下文工程栈;Google 把 Sessions、Memory Bank、Agent Gateway、Topology、Trace 与 Agent Runtime 统一到平台;LangGraph 与 AutoGen 则分别从 durable runtime 和 actor-style event-driven system 两个方向加强底座。
重点方向与方法比较
长时运行、状态耐久化与上下文工程
长时运行已经从“特殊需求”变成 Agent 产品的中心需求。OpenAI 的 Background mode 专门为数分钟级复杂任务而设,并明确指出其异步轮询机制会暂存响应、因此不兼容 ZDR;OpenAI Agents SDK 又把 sessions、conversationId、previousResponseId 作为不同持续化策略;LangGraph 则把 thread、checkpoint、super-step、pending writes、time-travel 调试下沉到底层;Anthropic 进一步把 compaction、context editing、memory tool 以及面向多上下文窗口的 initializer/coding-agent harness 做成系统化方案。行业已经不再假设“一个上下文窗口完成一件事”,而是假设任务会跨窗口、跨轮次、跨进程持续存在。
这类系统设计的关键,不只是“把历史拼回 prompt”,而是把工作记忆、可恢复状态、产物状态、长期记忆分开管理。Anthropic 的 long-running harness 案例说明,仅靠 compaction 仍然不够,必须让初始化 agent 建立 init.sh、进度日志、feature checklist 和 git 提交基线,让后续 agent 能快速接棒;Anthropic 的 memory tool 则让模型自动检查 /memories 目录并读写记忆;Google Agent Platform 将 long-running agents、Sessions、Memory Bank 分开建模;Mem0 代表的研究方向则尝试用选择性提取、整合与检索来替代全量 transcript 重放。真正成熟的系统会把“上下文”当成一种稀缺资源,而不是无限堆叠的聊天记录。
这一路线的核心指标,建议至少跟踪:任务跨恢复成功率、平均恢复时间、上下文压缩后回归错误率、cache 命中率、每成功任务 token 成本、以及人工接棒率。开放问题主要是摘要漂移、状态复演的一致性、记忆污染、隐私保留周期,以及不同层状态之间的冲突消解。Anthropic 也明确指出,compaction 当前仍使用同一个请求模型做摘要,不能单独换更便宜的 summarizer;context editing 在清理 tool results 时还会影响 prompt caching。
Grounding 与 Agentic RAG
主流平台的实际方向并不是“长上下文取代检索”,而是长上下文、检索和外部工具联合工作。Anthropic 把 citations、search results、web fetch、web search 做成 grounding 面;Google 明确将 Grounding with Google Search 和企业数据连接视为降低幻觉、引入最新信息的关键;阿里云百炼将知识库(RAG)定义为补充私有数据和最新信息的核心能力;Qwen-Agent 则强调 hybrid RAG 与 agent-based decomposition,可以处理 1M+ token 文档并在某些 benchmark 中超过原生长上下文模型。说明行业已经从“单一 top-k 检索”进入代理式检索、动态检索、层次化检索、图谱检索和反思式检索阶段。
从方法论上看,近两年的 RAG 路线可以概括为五类。第一类是混合检索 + 重排 + 引文,仍然是大多数产品的基础形态;第二类是 RAPTOR 这类层次化摘要树,把长文档的不同抽象层级都纳入检索空间;第三类是 GraphRAG,通过知识图谱把“局部命中”扩展成“全局发现”;第四类是 CRAG,用轻量 evaluator 判断检索是否失败,并在必要时触发 web 搜索和文档修正;第五类是 Adaptive-RAG / selective retrieval,先判断问题复杂度,再决定是否检索及采用何种检索强度。它们的共同点是:检索不再固定发生,而是被当成一个需要路由和校验的决策过程。
这一路线的关键指标,应从“回答对不对”扩展到“证据是否对、证据是否新、证据利用是否充分”。建议至少跟踪:检索命中率、Evidence precision/recall、groundedness、citation precision、freshness miss rate、以及 cost per grounded answer。开放问题则集中在查询改写、跨文档多跳、私有数据权限边界、低质量证据注入、引文与最终答案错配,以及评测数据与真实企业语料的分布偏差。
工具使用、技能/插件与协议互操作
工具层的演进,正在从“私有插件生态”走向“协议化互操作”。MCP 官方将其定义为一种让 AI 应用连接数据源、工具与工作流的开放标准,Anthropic 直接把 MCP 描述成“AI 的 USB-C”;OpenAI Agents SDK 也把 MCP 作为工具接入面;Google 在 2025 年推出 A2A,希望让不同框架和厂商的 agents 可以发现彼此、协作与任务委派;与此同时,Anthropic 的 Skills、Qwen-Agent、百炼 Agent 2.0、扣子技能,都在证明“可打包的能力单元”正在替代早期松散插件。工具层已经不是附庸,而是 Agent 产品的主要扩展接口。
这一方向里,最重要的工程认知是:工具接口本身就是 prompt 工程,而且通常比主 prompt 更重要。 Anthropic 的“writing effective tools for agents”与多智能体研究系统都强调,工具描述质量决定工具选择质量,他们甚至构建了专门的 tool-testing agent;一次工具描述重写可使后续 agent 的任务完成时间下降 40%。Anthropic 的 Tool Search 文档还给出非常具体的量化证据:典型多服务工具集合可提前吃掉约 55k tokens,上下文里超过 30–50 个可见工具后,正确选工具的能力会明显退化,而动态按需加载能把定义上下文削掉 85% 以上。换言之,工具太多并不会自然带来更强能力,反而会伤害模型判断。
同时,行业在“工具颗粒度”上也越来越清晰。Anthropic Skills 使用 filesystem-based progressive disclosure,先只加载约 100 tokens 的 metadata,Skill 触发后再加载 SKILL.md 指令,资源文件则按需访问;扣子技能则把“特定领域知识库 + 工具包”打包,并允许系统根据相关性自动安装与触发;Qwen-Agent 则把 Function Calling、MCP、Code Interpreter、RAG 等能力统一到一个 agent 框架中。方向已经非常明确:能力单元要可声明、可发现、可按需加载、可版本化。
安全、权限、执行隔离与治理
Agent 一旦能读文件、调系统、点网页、执行命令,安全问题就不再是“输出是否不当”,而是“是否触发了真实副作用”。因此,安全主线正在从内容安全扩展到执行边界安全。OpenAI 明确要求不要把不可信变量放进 developer messages,因为它们拥有更高优先级;OpenAI 的 Guardrails and human review 文档把 input/output/tool guardrails 与 human approvals 分开治理;Codex 文档则把 sandbox mode 与 approval policy 视作两层互补控制,且默认网络访问关闭;Anthropic 的 Claude Code 默认严格只读,并要求对 bash 命令等额外动作逐项批准;Google 侧则增强了 Tool Governance、Agent Gateway、IAM policy、SPIFFE-based Agent Identity。说明生产级 Agent 的默认态度已从“权限开放,再补防护”转向“默认最小权限,再按需升级”。
这里最重要的工程原则有三条。第一,不可信文本不能直接驱动高权限行为;第二,任何带副作用的动作,在生产里都应有结构化校验或人工审批;第三,执行必须被隔离到 sandbox / container / VM / gateway 后面。Anthropic 的 code execution tool 运行在沙箱容器中,并特别提醒当你同时提供多个执行环境时,模型可能混淆环境状态;OpenAI 的 SandboxAgent 也把“agent harness 与 sandbox compute”明确分离;Magentic-One 文档则公开提醒其可能遭受网页 prompt injection。最可靠的系统,不是“模型永不被绕过”,而是即使被绕过也无法越权。
建议产品团队至少追踪五类安全指标:敏感工具调用审批率、审批拒绝率、越权尝试阻断率、注入测试成功率、以及带副作用动作的人工介入比例。开放问题主要是间接提示注入、跨工具数据外泄、MCP 认证链条、工具说明与实际权限不一致,以及安全控制与用户体验之间的摩擦。Google Agent Gateway 的 audit-only 到 enforce 的渐进式上线方式,正好说明这类系统的最佳实践不是“一步到位”,而是先看日志、再强制执行。
评测、可观测与持续优化闭环
Agent 工程正在全面进入 eval-driven development 阶段。OpenAI 的官方评测指南把“定义任务、跑 eval、分析结果、迭代改进”写成标准流程,并明确说这和行为驱动开发相似;OpenAI Agents SDK 默认开启 tracing,跟踪 LLM generation、tool call、handoff、guardrail 等 span;Google Agent Platform 的 observability 面板则直接把 average response quality、safety metric、hallucination rate、tool use quality、p50/p95/p99 latency、error rate 做成在线监控;Anthropic 则用 tool-testing agent 与 prompt/tool 迭代把工具人体工学持续优化。由此可见,评测已从模型选型附属品,升级为运行时的一部分。
与此同时,benchmark 的形态也显著扩展。BFCL 评估函数/工具调用能力;τ-bench 聚焦带 API、规则和用户交互的真实多轮场景;OSWorld 把评测拉进真实桌面与 Web 环境;SWE-bench Verified 使用人工验证的 500 个软件问题来评估编码代理;TheAgentCompany 则模拟“数字员工”在公司环境中的浏览、写代码、运行程序和与同事交互的任务。这些 benchmark 的共同趋势,是从“单轮回答质量”走向“带工具、带状态、带环境反馈、带政策约束的任务完成能力”。
真正实用的评测体系一般分三层。第一层是离线可执行 eval,用于回归与对比;第二层是trace 级诊断,定位失败发生在检索、工具、编排还是模型推理;第三层是在线监控与 badcase 归因,将真实流量持续沉淀为新测试集。阿里云百炼的自动评测/评估器页面,会直接给出总正确率、BadCase 分析、Prompt/RAG/知识库切片调优建议;Google 侧显式展示安全、幻觉、工具质量等在线指标;Anthropic 的工具说明重写实践则表明,优化工具 UX 本身也应被纳入持续评测闭环。
编排、模型路由、Advisor 与多智能体
跨平台最值得注意的共识是:多智能体不是默认答案,workflow 才是默认答案。 Anthropic 在“building effective agents”中把 prompt chaining、routing、parallelization、orchestrator-workers、evaluator-optimizer 与 autonomous agents 逐层区分,并明确建议先找最简单方案;OpenAI 则把多智能体进一步拆成 handoffs 和 agents-as-tools 两种 ownership 模式;阿里云百炼也把“Agent / Workflow / 高代码应用”三种模式并列。这说明工程上最成熟的范式不是“任意 swarm”,而是边界明确、所有权清晰、必要时才上自治。
当任务的子任务边界不固定、需要并行搜集线索、或需要不同能力明确分工时,多智能体才开始显示价值。Anthropic 的研究系统让 lead agent 先判断问题复杂度,再决定 subagent 数量、工具预算和任务边界,并且发现如果没有明确规则,系统会为简单问题创建过多 subagent、做重复搜索、互相广播无效进展。微软 Magentic-One 的 Orchestrator + WebSurfer/FileSurfer/Coder/Terminal 也是一个类似设计;AutoGen 0.4 进一步转向 actor model,以支持事件驱动、可观察、可伸缩的多智能体系统。换句话说,真正有效的多智能体通常是“有编排纪律的专家系统”,不是自由聊天的 agent 社交网络。
在成本与时延方面,行业正在形成三种主流优化路线。第一种是workflow-level routing:简单任务走小模型、复杂任务走大模型;Anthropic 与 RouteLLM、Hybrid LLM、cascade routing 的思路都支持这种质量/成本平衡。第二种是advisor-executor 模式:Anthropic 的 Advisor tool 让低成本 executor 在需要时中途咨询高智 advisor,单次 advice 一般只有 400–700 个文本 token,总代价远低于让高智模型全程生成。第三种是bounded specialists,即 manager 保持回复所有权,只把特定子任务包成 tool 调用,而不是整个对话 handoff 出去。对产品团队而言,这意味着:先收集 eval 数据,再做路由;先明确 ownership,再做多 agent。
开发者体验、部署与基础设施
Agent 工程的另一个新共识是:框架、运行时、harness、observability、deployment 必须解耦。 LangGraph 文档把 Deep Agents 定义为 harness、LangChain 定义为 framework、LangGraph 定义为 orchestration runtime、LangSmith 定义为 tracing/eval/deployment 平台;Anthropic 在 Managed Agents 中进一步提出“decoupling the brain from the hands”,把 reasoning 与 execution boundary 分开;OpenAI 的 SandboxAgent 则保留 agent 的常规表面,但把执行放入带 manifest、capabilities、provider-specific sandbox 的 live session;Google Agent Platform 也在 runtime 层统一 long-running、sessions、memory、gateway、trace、topology。说明成熟系统不再把“推理逻辑”和“执行环境”绑死在一起。
从部署形态看,行业正在形成三条平行路线。第一条是托管运行时平台,适合需要快速上线、统一治理与企业接入的团队;第二条是开源 runtime + 自建 infra,适合对可控性与可移植性要求高的团队;第三条是低代码 Agent/Workflow 平台,适合业务团队快速集成。中国市场的演化尤为典型:阿里云把 Agent、Workflow、高代码应用并列选型,并推荐多数场景迁移到将知识库和 MCP 统一为工具的 Agent 2.0;扣子把 workflow versioning、多人协作、资源管理、异步执行做成平台标准能力;Qwen-Agent / Qwen Code 则提供一个更接近开源本地运行时的方向。西方平台与中国平台的差异主要在产品包装,不在核心结构。
这一方向的关键指标,不应只看吞吐与可用性,还应看“团队是否能更快构建和定位错误”。建议至少跟踪:time-to-first-agent、部署回滚时间、单个 badcase 的平均定位时间、sandbox/worker 冷启动、日志与 trace 可关联率、版本回溯成功率、以及跨环境状态一致性。Google 的 Agent Platform 已直接提供 topology、p95 latency、error rate、logs、traces;LangGraph 提供 threads/checkpoints/time-travel;Coze 和百炼则在低代码侧提供版本与异步策略。这说明 Developer UX 本身,已经成为平台竞争维度。
产品团队的研究与工程建议
对产品团队而言,最有效的研究优先级不是去追逐“下一个更酷的 Agent 框架”,而是围绕 任务定义、工具质量、状态层、评测闭环和执行边界 五个主题建立系统能力。Anthropic 的经验是先用最简单的方式实现,再在 eval 证据支持下增加复杂度;OpenAI 把 eval 和 guardrails 写进基础文档;Google 则直接把 online evaluation、topology 和 runtime observability 做成平台页签。这些都说明:先建立反馈闭环,再尝试更高自治。
最实用的落地路径通常分为三个阶段。第一阶段,用单 agent + 明确 workflow + grounding + traces + approvals 解决一个高价值、能自动验收的任务;这时不要急于上多智能体,而要先把工具 schema、检索质量和 badcase 体系打牢。第二阶段,引入sessions/checkpoints/compaction/memory,让任务可以跨轮和跨天持续;同时用 prompt caching、tool search、context editing 先做“低风险成本优化”。第三阶段,只有当你已经有稳定 eval 与足够流量数据时,才上 router/cascade/advisor 与更复杂的 specialist 编排;多智能体应被证明能在你的任务上带来显著胜率提升,而不是因为它“看起来更像 agent”。这一顺序,与 Anthropic 的 workflow-first、OpenAI 的 handoff/tool ownership 划分,以及阿里云的 Agent/Workflow/高代码选型逻辑是一致的。
在研究投入上,我建议优先做五类内部实验。第一类是工具界面实验,包括参数命名、描述、错误信息与 destructive annotation;Anthropic 的案例已经证明这是高收益区域。第二类是检索决策实验,比较 no-RAG、fixed-RAG、adaptive-RAG、graph/hierarchical RAG 在你的语料上的差异。第三类是状态层实验,比较 full replay、summary replay、session store、memory bank 的稳定性与成本。第四类是路由实验,用固定 benchmark 和真实工单比较单模型、router、cascade、advisor 的单位经济。第五类是安全实验,把 prompt injection、越权操作、工具滥用、审批绕过做成持续攻防套件。只有这些实验稳定后,多智能体研究才值得大规模投入。
下面这张表,把“建议优先做什么”和“先不要做什么”落到工程动作上。
最后给一个更具体的“工程口令”:先评测,后放权;先工具,后多 agent;先状态,后记忆;先缓存与检索优化,后模型路由;先 sandbox,后真实副作用。 这不是保守,而是过去两年主流平台实践反复验证后的最短路径。Anthropic 的建议是让系统保持简单并把工具文档当成 ACI;OpenAI 的建议是用 eval、guardrails、human review 和 sessions 组织 runtime;Google 的方向则是把 observability、topology、gateway 和 runtime 统一起来。最强的 Agent 产品,很少是“模型自己会了”,而通常是“工程团队终于知道它为什么成功、为什么失败、失败时不会造成损失”。
结论
如果用一句话概括 2024-2026 年 AI Agent 的行业走向,那就是:Agent 正从“模型能力问题”演化为“运行时系统设计问题”。模型仍然关键,但其真正价值越来越取决于是否处在一个有状态、有证据、有边界、有评测、有可观测性、能低成本恢复和扩展的运行时之中。Anthropic 把这种变化总结为 context engineering 和 managed harness;OpenAI 把它落实为 Agents SDK、Background mode、Sessions、Guardrails、Tracing、Evals、Sandboxes;Google 把它产品化为 ADK、A2A、Agent Platform、Memory Bank、Agent Gateway、Topology;中国平台则在 Agent/Workflow/高代码、技能、知识库与低代码异步编排上给出了相同的答案。
因此,未来一到两年里,最有可能赢得市场的团队,不一定是最早做出“完全自治多智能体”的团队,而更可能是那些把 workflow 与 agent 的边界、工具与协议的边界、上下文与记忆的边界、模型与运行时的边界、自由与治理的边界 设计得最清楚的团队。AI Agent 的真正竞争,已经从“谁更会写 prompt”进入“谁更会做系统工程”的阶段。
