2026年5月份 AI Agent 产品中的记忆设计与工程实践
本报告来自ChatGPT的DeepResearch总结,主要关注AI Agent系统的记忆的设计。
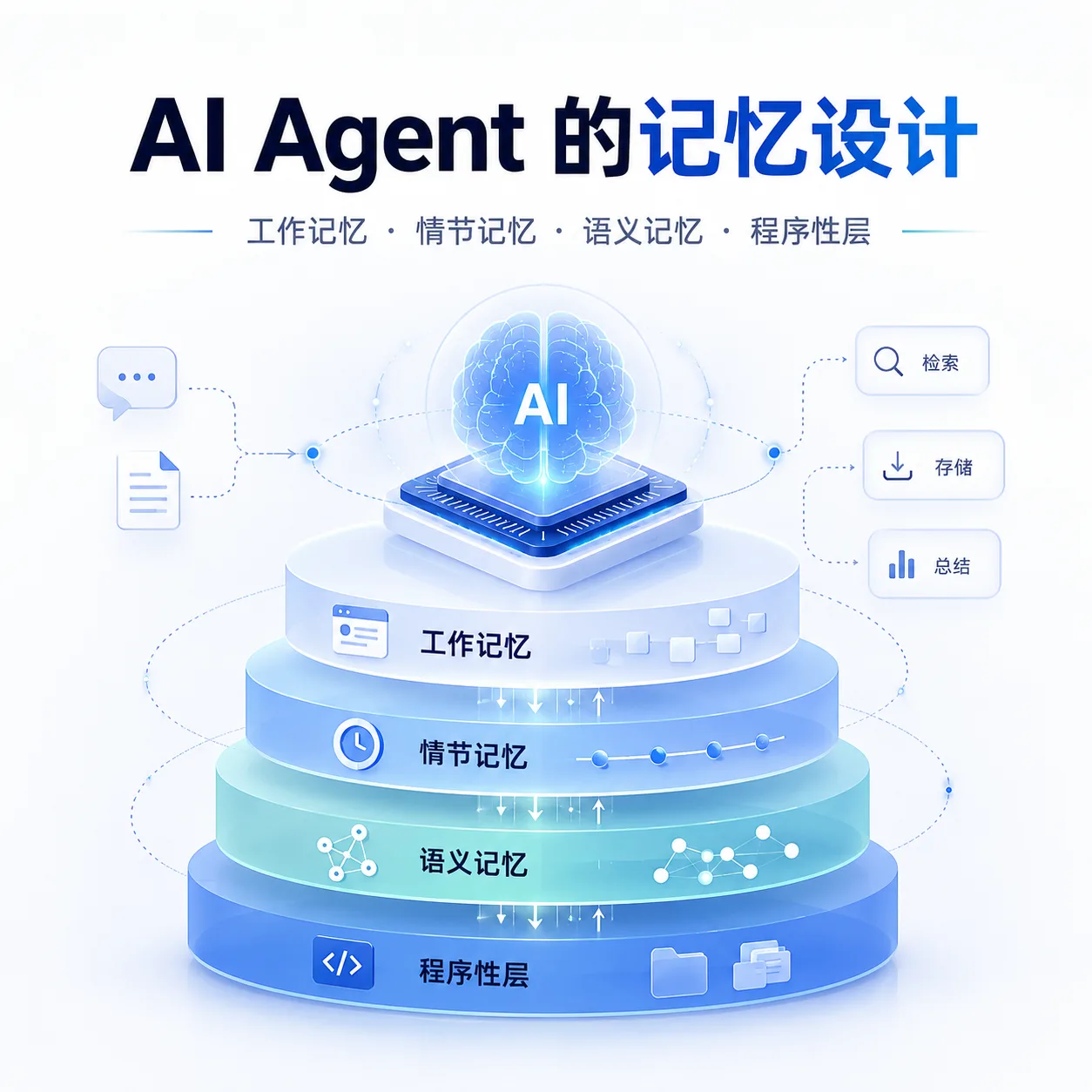
执行摘要
过去一年里,AI Agent 的“记忆”设计明显从“把更多历史塞进上下文窗口”转向了更工程化的多层体系:把当前上下文当作工作记忆,把会话记录、屏幕轨迹、日志等当作情节记忆,把稳定偏好、约定、知识摘要当作语义记忆,再把规则、技能、流程模板当作一种接近平行“程序性记忆”的外化层。Anthropic、OpenAI、OpenClaw、Hermes、Cursor 等产品虽然界面不同,但其核心都在解决同一个问题:如何在有限上下文、可接受延迟、可控成本下,为 agent 提供持续、一致、可审计的长期状态。
如果把近年的产品实践按架构分型,可以大致分成四类。第一类是文件型记忆,典型如 Claude Code、Hermes、OpenClaw:把长期记忆落到 Markdown/目录中,优点是可审计、可编辑、迁移简单,缺点是结构弱、检索精细度受限。第二类是会话库 + 检索型记忆,典型如 Hermes 的 SQLite+FTS5、OpenClaw 的 SQLite/QMD/LanceDB、Cursor 的代码索引;优势在于可扩展、可按需召回,代价是要处理索引新鲜度、并发、一致性和成本。第三类是后台凝练型记忆,典型如 Codex Memories、OpenClaw Dreaming、Hermes 外部 provider 同步:它们都把“什么时候写、写什么、何时合并”从主对话中拆出来。第四类是预检索子代理型记忆,比如 OpenClaw Active Memory、Hermes provider prefetch,把“先回忆、再回答”做成前置步骤,以降低遗漏关键上下文的概率。
从产品成熟度与工程可复用性看,当前最稳妥的落法不是“统一的万能 memory DB”,而是双层或三层记忆:一层小而稳定、永远注入提示词;一层大而便宜、按需检索;必要时再加一层后台反思/编译层,负责从原始情节中提炼出可长期复用的事实、偏好和关系。这一点与学术脉络是同频的:Generative Agents 以“相关性+时间新近性+重要性”定义回忆,MemoryBank 引入遗忘曲线,LongMem 与 MemGPT 将长程记忆抽象成层级内存/外部 memory bank,Mem0 则进一步把“提取—合并—检索”做成可部署的生产系统,并在 LOCOMO 上报告相对更低的 p95 延迟和 token 成本。
对实际做产品或平台的人来说,最重要的结论有三点。其一,不要把“记忆”只理解为向量库;在 coding agent 中,Rules、AGENTS.md、Skills、Plans、Session Search、Worktree、Hook 日志往往共同构成长期状态。其二,记忆更新必须是有生命周期的工程问题,包括写入门槛、冲突合并、压缩、遗忘、回放、备份与审计。其三,安全与可追溯性必须内建:越自动的记忆层,越需要来源标注、注入扫描、作用域隔离、用户可见的 review 面和一键忘记能力。
分析框架
本文把 agent 记忆拆成四个主维度。工作记忆指当前上下文窗口中的活跃 token;情节记忆指按时间组织的会话、操作、屏幕、日志和日记;语义记忆指跨会话稳定有效的偏好、规则、知识摘要、实体关系;长期记忆则是所有能够在未来会话中复用的外部状态总和。需要特别说明的是,在当下产品实践里,程序性记忆虽然不在你要求的主分类中,但非常关键,它通常被实现为 Rules、Skills、Hooks、Commands、Plan 文件或 Wiki 编译物,而不是传统数据库记录。
以这个框架看,当前最常见的表示形式有三种。第一种是纯文本文件,例如 Claude Code 的 CLAUDE.md 与 auto memory、Hermes 的 MEMORY.md/USER.md、OpenClaw 的 MEMORY.md 和 memory/YYYY-MM-DD.md。第二种是嵌入与索引块,例如 Cursor 的代码块 embeddings、OpenClaw 的 hybrid search、Hermes/各 provider 的语义检索。第三种是结构化对象或派生层,例如 OpenClaw memory-wiki 的 claim/evidence/provenance、Hermes Honcho 的 user model 与 dialectic conclusions、Codex memories 中把 summary、durable entries、recent inputs 和 supporting evidence 分层管理。
下面这张图概括了目前最常见、也最稳健的一种多层 agent 记忆架构。它不是某一家产品的精确实现,而是对 Claude Code、Codex、Cursor、OpenClaw、Hermes 等公开资料的抽象归纳。
一个成熟系统往往不只做“检索”,而是做“装配”。Anthropic 明确把记忆、压缩、tool clearing 都视为 context engineering 的不同杠杆;Hermes 刻意把缓存稳定的系统提示层与 API 调用时的瞬时叠加层分开;OpenClaw 则在 compaction 之前先做 silent memory flush;Cursor 强调让 agent 自己用 grep 与 semantic search 找上下文,而不是让用户手工打包文件。也就是说,真正的难点不是“有没有记忆”,而是什么记忆要常驻、什么要按需拉取、什么要在后台合并、什么必须及时丢弃。
产品对比
下面的表格把五类代表性产品放在同一框架里比较。需要强调两点:一是你给出的例子只是代表样本,不是全部市场;二是对于没有公开实现细节的部分,我统一标为**“未公开明确说明”**,这表示公开资料不足,并不代表产品内部一定不存在该能力。
从这张表可以看出,Claude Code 与 Codex 更接近“轻量可见的本地记忆”。它们都强调用户能看见文件、能打开、能编辑、能清除,这对信任建立非常重要;但两者都没有公开很多底层检索细节,说明其产品重点放在“可用性与安全边界”而不是把 memory 作为平台级数据库公开出来。Claude Code 更像“永远加载一个精简索引,再按需读 topic files”;Codex 则更像“线程结束后台抽取,再以 durable/recent/evidence 的多层文件回注到后续线程”。
Cursor 则是另一条路线。它公开得最充分的不是“用户偏好记忆”,而是代码理解索引和上下文发现。其文档与工程博客反复强调,Agent 通过 grep、semantic search、Explore subagent 拉取上下文,而后台用 Merkle tree 检测增量变化、把文件切成 syntactic chunks 生成 embeddings,并通过 simhash + content proofs 在团队内安全复用索引。这让 Cursor 在 coding 场景里非常强,但也意味着如果你问的是“像个人助理那样的跨会话自动记忆”,截至公开资料它并没有像 Codex Memories 或 Claude Code auto memory 那样给出一套独立、可审阅、带生命周期说明的产品级定义。
OpenClaw 与 Hermes 代表了更“系统化”的 agent memory 平台化路线。两者都把内建文件记忆保留为第一层,因为它便于人审阅、迁移和修复;又同时引入更强的检索层和 provider/plugin 机制。OpenClaw 走得更“分层化”:原始日记、长期记忆、active memory 子代理、dreaming consolidation、wiki 编译层、QMD/LanceDB/Honcho backend 各司其职。Hermes 则更强调“有界稳定前缀 + 会话库 + provider 增强”的组合,并把 prompt cache 稳定性、WAL 并发、FTS5、context engine 插件化写进了开发者架构文档。就工程复用性而言,这两者公开得最像“可搭建平台”的 memory substrate。
记忆生命周期与上下文工程
一个可落地的 memory 系统,不应只看“存在哪里”,而要看“整个生命周期怎么跑”:采集、筛选、提炼、索引、召回、注入、压缩、淘汰、审计。这个流程在成熟产品里几乎都已经显式化了,只是名字不同。Claude/Anthropic 把它叫 context engineering;Codex 把抽取与 consolidation 放到后台;OpenClaw 把 promotion 交给 Dreaming;Hermes 则把 provider prefetch、prompt assembly、compression、persistence 写成独立子系统。
在采集与写入门槛上,Claude Code 与 Codex 都避免“每轮都写”。Claude 由模型自己判断什么值得记住;Codex 会跳过 active 或 short-lived thread,并在 thread 空闲一段时间后才进行后台记忆生成,还会在 rate limit 剩余过低时放弃这一轮抽取。这个设计的本质是:记忆写入是有成本的,而且过快写入会把尚未稳定的中间结论固化下来。
在短期层到长期层的凝练上,OpenClaw 是最有代表性的案例。它明确区分 memory/YYYY-MM-DD.md 这样的工作层与 MEMORY.md 这样的长期层,前者用于原始上下文和 daily notes,后者只保留耐久事实、偏好和决策;随后 Dreaming 再用 light/deep/REM 三相把近期迹象去重、打分、提升到长期记忆,且只允许 grounded snippets 被提升。Hermes 也有类似取向,只是做法更保守:它直接把长期记忆限制在约 1300 token 规模,超限时必须 consolidate 或 replace,而不是无限增长。
在召回策略上,今天的最佳实践并不是“所有长期记忆都提前注入”。Anthropic 明确提出 compaction、tool clearing 与 memory 的组合;它在 Claude Code 的长期任务里会压缩上下文、丢弃冗余工具输出,并让结构化笔记承担跨窗口桥接。OpenClaw 的 Active Memory 更进一步,把召回做成一个主回复前的阻塞型 memory sub-agent;Hermes 的外部 provider 则在每轮前做 prefetch,但 built-in memory 保持稳定快照;Codex Chronicle 也呈现出同样的精神:不是什么都直接塞进 prompt,而是用屏幕上下文帮助 agent 找到真正应该直接读取的源文档。
在上下文窗口管理上,各家已经开始把“保 cache、保速度、保一致”当成一等公民。Hermes 明确将 cached system prompt 与 API-call-time overlays 分离,并自动使用 1 小时 prompt caching;同时其 built-in memory 是 session start 的 frozen snapshot,运行中写盘但不改当前 prompt,以保护前缀缓存。Claude 的 context engineering cookbook 同样强调 compaction 与 tool clearing 的组合,避免上下文 rot。OpenClaw 则通过 pruning 去掉旧 tool results、仅在内存中瘦身而不改写磁盘 transcript,从而兼顾回放与成本。
可复用设计模式
下面这张表不是产品列表,而是从这些产品中抽出来、可直接复用于新 agent 的工程模式。对多数团队来说,这些模式比“选哪家向量库”更重要。
如果只能给出一个实践建议,那就是:先做双层记忆,再做反思层,最后才做复杂图谱层。先把“永远加载的小索引”和“按需搜索的大语料”分开,已经能够解决大部分真实问题;只有当你遇到跨实体关系、多代理身份隔离、强 provenance 需求时,再引入 Honcho、Wiki、Graph memory 或 graph-backed providers。学术上,Generative Agents 的 relevance/recency/importance、MemoryBank 的忘却曲线、MemGPT/LongMem 的层级记忆、Mem0 的生产化提炼/合并/检索路线,基本都支持这个从简到繁的工程演化顺序。
评估、安全与工程约束
在评估上,很多团队仍然把“能不能搜到片段”当成 memory 的全部,但这远远不够。更合理的指标至少应该包含五类:第一类是召回质量,比如 hit@k、evidence precision、grounding consistency;第二类是行为收益,比如任务完成率、跨会话一致性、是否减少重复提问;第三类是效率,比如 p50/p95 延迟、token 占用、重建索引时间;第四类是生命周期质量,比如 false remember rate、staleness、conflict resolution 成功率、删除传播延迟;第五类是可运营性,比如恢复能力、备份恢复时间、观测覆盖率。Mem0 在 LOCOMO 上强调的,就是“内存架构”不仅影响回答正确率,也会强烈影响 p95 延迟与 token 成本;而 LifeBench、AgentLongBench 一类新 benchmark 又提醒我们,传统静态 recall 题并不能充分衡量 agent 在长时程、多源、交互式环境中的记忆能力。
从安全与隐私视角看,当前产品分成两派。文件型记忆让用户更容易理解和删除,但也更容易产生“本地未加密明文”问题,Codex Chronicle 就明确提醒记忆文件未加密、会增加 prompt injection 风险;Claude Code auto memory 也是 machine-local,本意是减少共享泄漏;OpenClaw 和 Hermes 则更强调扫描与隔离:OpenClaw 明说 per-user session/memory isolation 不等于 host authorization,Hermes 会对 memory entries 与 context files 做注入/外泄扫描。对企业产品而言,这里的核心不是“有没有加密”这么单一,而是作用域、证明、审计、最小权限、删除能力、外部上下文进入 memory 的阈值。
在可扩展性、并发和版本化方面,Hermes 与 Cursor 提供了最具代表性的公开工程细节。Hermes 用 SQLite WAL 来支撑多平台 gateway 的多读单写、FTS5 查询、session lineage 和压缩后父子会话关系;Cursor 则在索引层使用 Merkle tree、simhash、content proofs 和 chunk embedding cache,把团队内相似代码库的 time-to-first-query 从小时级降到了秒级;Codex 的 changelog 还提到 memory summaries 的版本化与陈旧格式重建。这类细节说明,memory 系统必须被当成数据库与分布式索引系统来运营,而不是只靠 prompt 技巧。
在开发者 API 与集成面上,五家产品的成熟度差异很大。Anthropic 公开了 client-side memory tool,把内存目录作为 API 工具原语;OpenAI 则给出 Codex 的 SDK、App Server、MCP Server 与本地 memory 控制;Cursor 公开的集成面更偏规则/Skills/Hooks/MCP/Cloud Agents webhooks;OpenClaw 与 Hermes 则都把 memory 做成可替换 slot/provider/plugin,并给出更完整的 CLI 与状态界面。对于需要可组合能力的平台团队,这意味着一个很现实的选择:若你要的是“做产品”,挑有清晰 memory primitive 与 API surface 的系统;若你要的是“直接提效”,文件型加规则型也可能已经足够。
就观测性与调试而言,公开资料里也已经形成一个明确趋势:memory 不能再是黑箱。Claude Code 提供 /memory 浏览;Codex 提供 /memories 与可检查的本地目录;OpenClaw 有 memory status、memory index --verbose、wiki status/doctor,以及 session cleanup/inspection;Hermes 有 session DB、Web Dashboard、FTS5 搜索、tool call 展示和 plugin/provider 状态;Cursor 则至少把 MCP logs、hooks、Cloud Agent webhooks 公开出来。一个团队如果无法回答“这条记忆从哪里来的、为什么被召回、删掉后多久生效、索引多久新鲜一次”,那它的 memory 层大概率还没有进入生产成熟期。
局限与优先来源
这份报告的一个重要局限是:不是所有产品都公开了底层 memory 数据结构、数据库选型、ANN 算法、metadata schema、冲突合并策略与删除传播机制。尤其是 Cursor、Claude Code、Codex,这三者对“用户看得到的 memory 体验”公开得比较多,但对底层检索引擎与排序/合并细节公开得相对有限;因此,凡是官方没有明确写出的地方,本文都标成了“未公开明确说明”,而没有根据二手推断去补齐。另一个局限是,学术 benchmark 目前仍然没有统一标准:LOCOMO 偏长会话问答,LifeBench/AgentLongBench 更偏长时程多源与交互闭环,彼此覆盖面不同。
如果你要为自己的 agent 体系做选型,我会给出一个简化判断。以 coding agent 为主时,最值得借鉴的是 Claude Code 的“常驻小索引 + topic files”、Cursor 的“动态上下文发现 + 安全索引复用”、Codex 的“后台记忆抽取 + thread 级控制”。以长期个人助理/非编程代理为主时,OpenClaw 与 Hermes 的体系更完整,因为它们已经显式处理了 daily notes、跨 session 搜索、主动召回、后台 consolidation、provider 插件化、以及 provenance/security。以平台/API 为主时,Anthropic memory tool、Codex app-server/SDK、Hermes/OpenClaw provider 与 plugin 面,是更接近“基础设施”的起点。
优先来源方面,第一优先级应看官方产品文档与工程博客:Anthropic 的 Claude Code memory 与 context engineering 文档、OpenAI Codex memories/Chronicle/SDK/App Server/MCP 文档、Cursor 的 rules/search/indexing/hooks/cloud agent 官方文档与工程博客、OpenClaw 官方文档与仓库中的 memory concepts、Hermes Agent 官方文档的 memory/providers/session storage/architecture 页面。第二优先级是原始论文:Generative Agents、MemoryBank、LongMem、MemGPT、Mem0、MemOS,以及新一代 benchmark 如 LifeBench、AgentLongBench。它们不直接告诉你产品怎么做,但非常适合拿来校验记忆分层、检索特征、遗忘策略与评估框架。
