Google反击OpenAI的大杀器!下一代语言模型PaLM 2:增加模型参数并不是提高大模型唯一的路径!
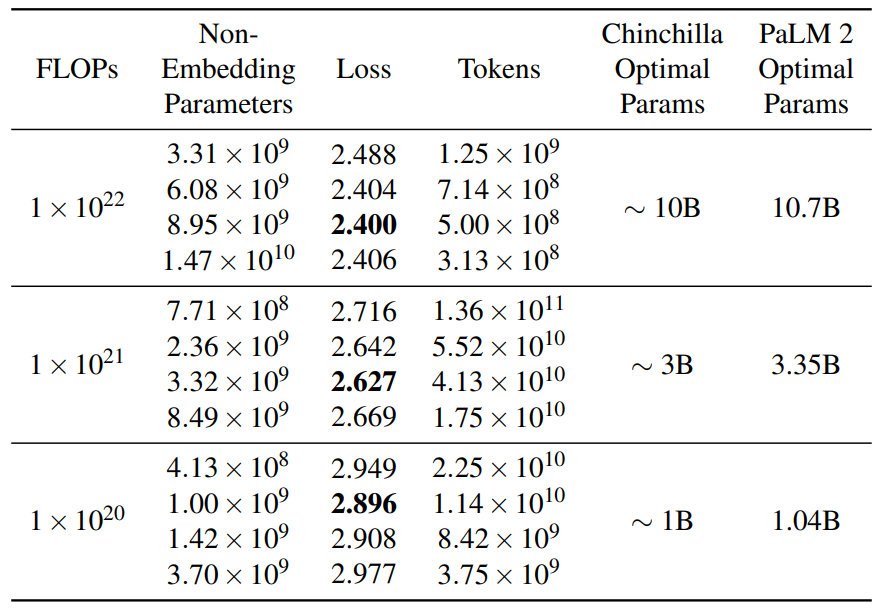
作为PaLM的继任者,PaLM2的发布被谷歌寄予厚望。与OpenAI类似,谷歌官方没有透露很多关于模型的技术细节,虽然发布了一个92页的技术报告,但是,正文内容仅仅27页,引用和作者14页,剩余51页都是展示大量的测试结果。而前面的27页内容中也没有过多的细节描述。尽管如此,这里面依然有几个十分重要的结论供大家参考。
汇总「PaLM」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
作为PaLM的继任者,PaLM2的发布被谷歌寄予厚望。与OpenAI类似,谷歌官方没有透露很多关于模型的技术细节,虽然发布了一个92页的技术报告,但是,正文内容仅仅27页,引用和作者14页,剩余51页都是展示大量的测试结果。而前面的27页内容中也没有过多的细节描述。尽管如此,这里面依然有几个十分重要的结论供大家参考。