
如何评估向量大模型在多种任务上的表现?Massive Text Embedding Benchmark(MTEB)评测介绍
MTEB是一个用于评估向量大模型向量化准确性的评测排行榜。它全称为Massive Text Embedding Benchmark,是一个旨在衡量文本嵌入模型在多种任务上表现的基准测试。
汇总「RAG」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
MTEB是一个用于评估向量大模型向量化准确性的评测排行榜。它全称为Massive Text Embedding Benchmark,是一个旨在衡量文本嵌入模型在多种任务上表现的基准测试。
大语言模型是通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型。但是,当前大家讨论较多的都是语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。

开源大语言模型经过一年多的发展,终于有一个模型可以在权威榜单上击败GPT-4的较早的版本,这就是CohereAI企业开源的Command R+。这是一个开源但是不允许商用的模型,参数规模达到1040亿,也是目前为止开源参数规模最大的一个模型。
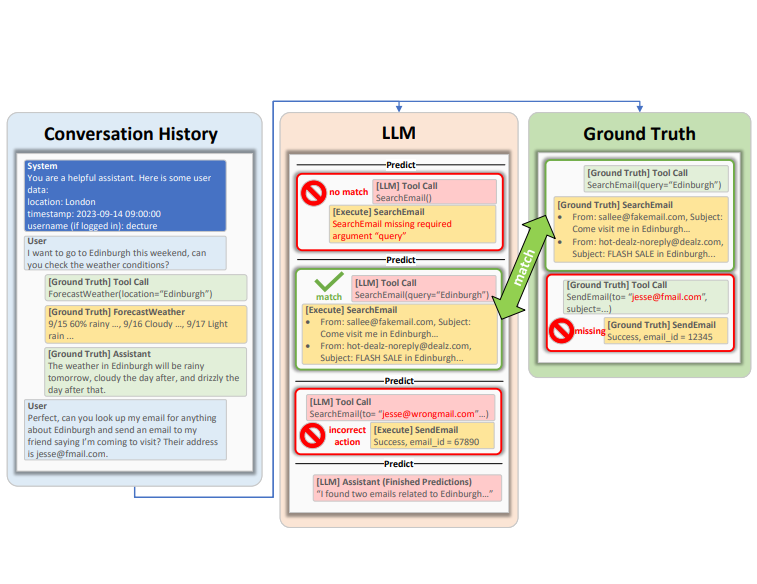
为了更好地评估大语言模型的工具使用能力,微软的研究人员提出了ToolTalk Benchmark基准测试工具,可以帮助我们更加简单地理解大语言模型在工具使用方面的水准。ToolTalk旨在评估大型语言模型(LLMs)在对话环境中使用工具的能力。这些工具可以是搜索引擎、计算器或Web API等,它们能够帮助LLMs访问私有或最新的信息,并代表用户执行操作。
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。

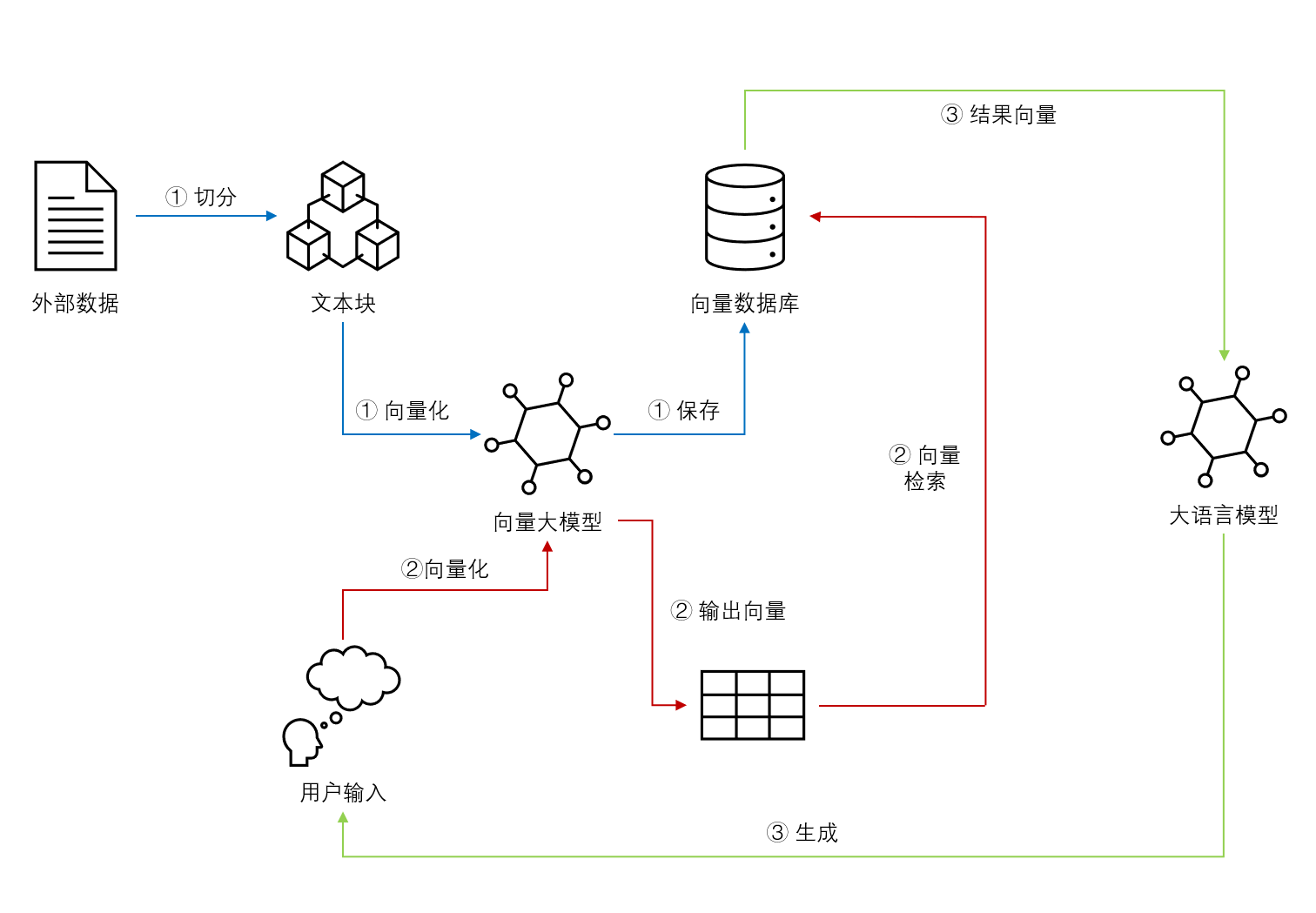
检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。

检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。
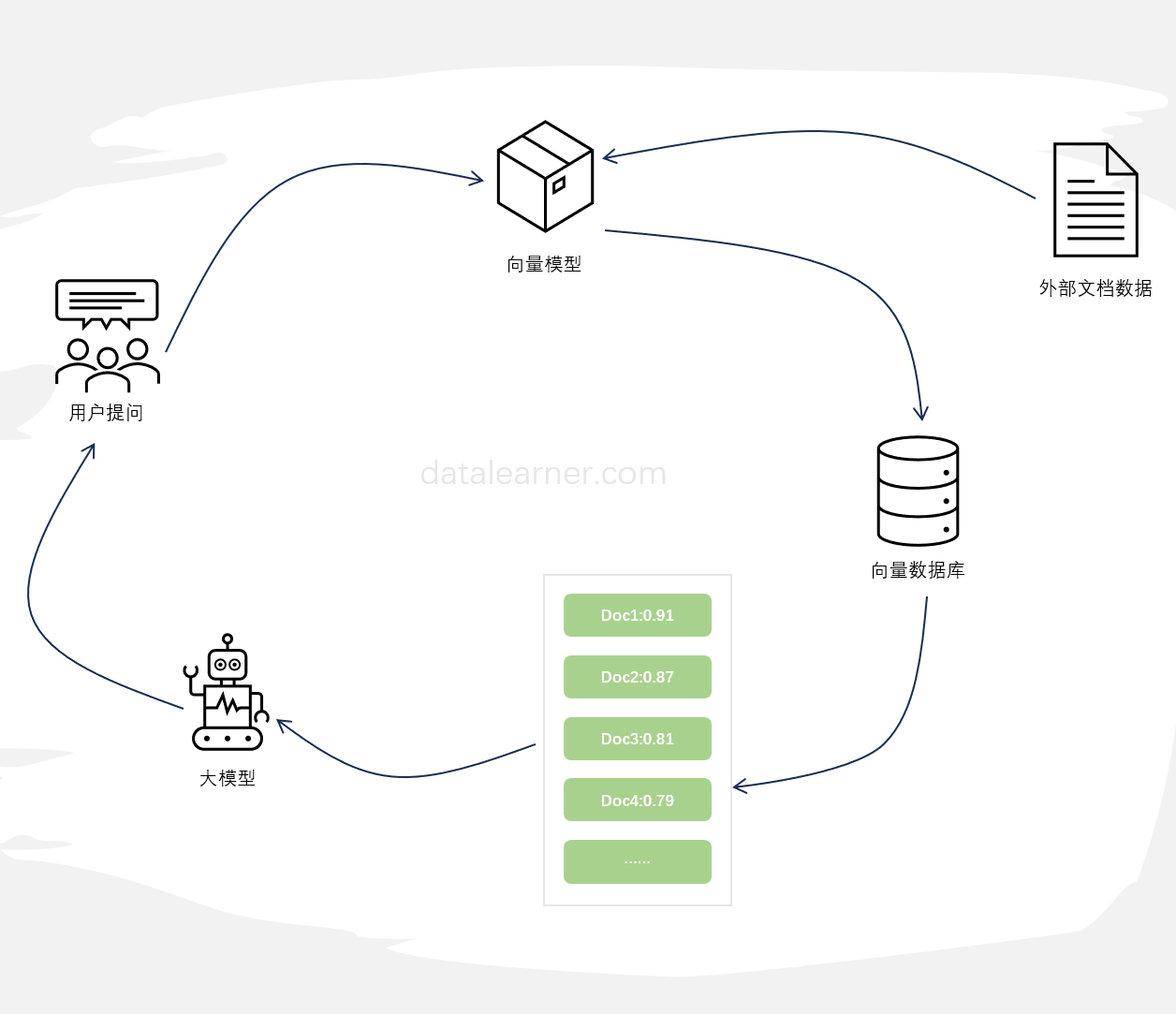
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。