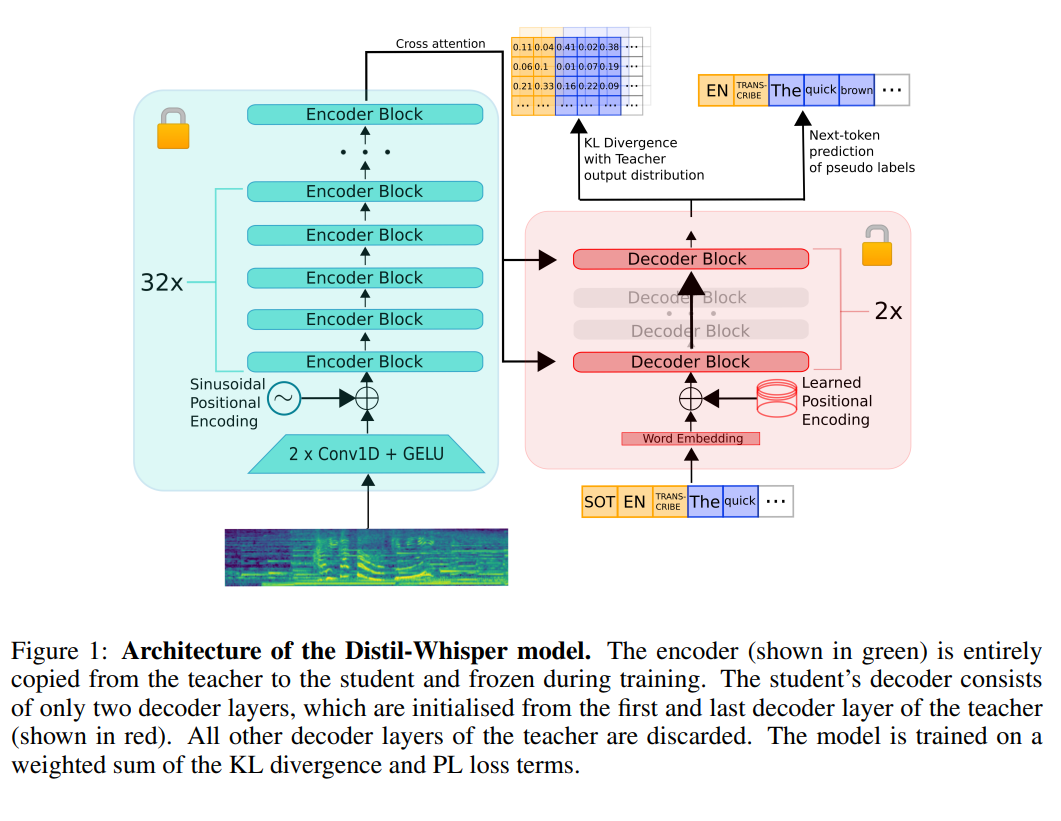
三年后OpenAI再次发布自动语音识别和语音合成大模型(替换Whisper系列):不开源,仅提供API,英文错字率已经下降到2.46%
2025年3月20日,OpenAI 推出了三款新模型——gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-mini-tts——标志着自动语音识别 (ASR) 和文本转语音 (TTS) 领域的重要进步。这些模型基于 GPT-4o 架构,旨在为开发人员和用户提高准确性、自定义能力和可访问性,与 OpenAI 对于代理式 AI 系统的更广泛愿景一致。本文提供了对每个模型、其能力、定价、可用性和竞争环境的详细审查,确保技术和非技术受众都能全面理解。