重磅好消息!推特开源自家的推荐系统算法!
2,248 views
虽然最近一段时间大模型十分火爆,但是传统的推荐依然是当前很多业务的核心能力,就在几个小时前,Twitter官方开源了自己的推荐系统,并详细介绍了它们的推荐算法。本文将简单介绍一下推特的推荐算法和架构!
先总结一下,Twitter总的推荐流程就是包括筛选候选集-排序-过滤-混合其他内容推送这几个步骤。涉及的主要算法就是逻辑回归、神经网络以及图相关的3类。
本文将描述推特推荐系统的整个流程以及每个流程里面具体做了什么!
加载中...
虽然最近一段时间大模型十分火爆,但是传统的推荐依然是当前很多业务的核心能力,就在几个小时前,Twitter官方开源了自己的推荐系统,并详细介绍了它们的推荐算法。本文将简单介绍一下推特的推荐算法和架构!
先总结一下,Twitter总的推荐流程就是包括筛选候选集-排序-过滤-混合其他内容推送这几个步骤。涉及的主要算法就是逻辑回归、神经网络以及图相关的3类。
本文将描述推特推荐系统的整个流程以及每个流程里面具体做了什么!
Follow DataLearner WeChat for the latest AI updates

Twitter推荐算法是一组服务和任务,负责构建和提供主页时间线。它将每天发布的大约5亿条推文精简到一小部分顶尖推文,最终显示在For You时间线上。
Twitter推荐系统的基础是一组核心模型和功能,这些模型和功能从推文、用户和互动数据中提取潜在信息。这些模型旨在回答有关Twitter网络的重要问题,例如“你未来与另一个用户互动的概率是多少?”或者“Twitter上有哪些社区,这些社区内有哪些流行的推文?”准确回答这些问题可以使Twitter提供更相关的推荐内容。
推荐流水线由三个主要阶段组成,这些阶段使用这些功能: 这三个主要阶段包括:
下面的图表说明了主要服务和任务之间的相互连接。
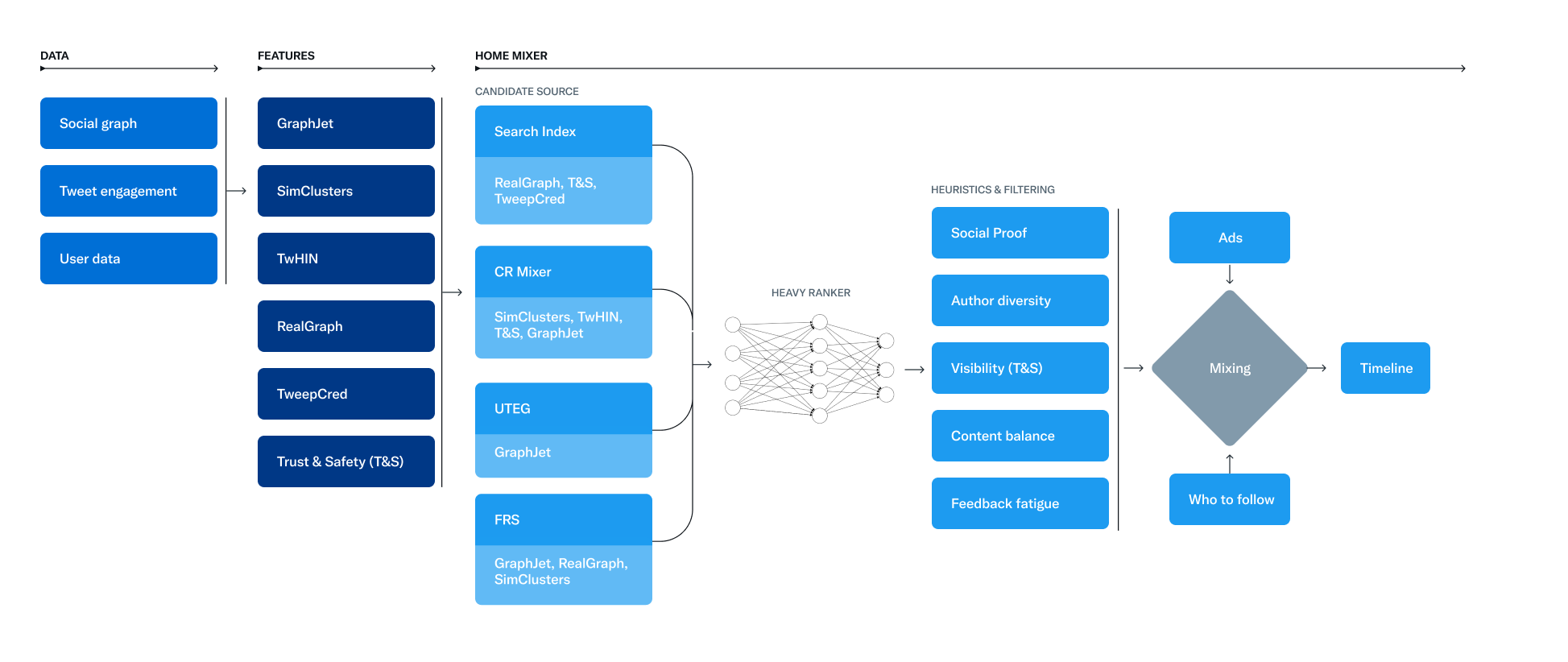
Twitter有几个候选源,用来为用户检索最近和相关的推文。对于每个请求,都是通过这些来源尝试从数亿条推文中提取最佳的1500条推文。主要包括您关注的人(网络内)和您没有关注的人(网络外)中找到候选者。
今天,For You时间线平均包含50%的网络内推文和50%的网络外推文,不过这可能因用户而异。
网络内源是最大的候选源,旨在为您提供最相关、最新的来自您关注的用户的推文。它使用逻辑回归模型基于其相关性关注的人的推文进行排名。然后,排名靠前的推文被发送到下一个阶段。
在对网络内推文进行排名时,最重要的组成部分是Real Graph。Real Graph是一个模型,预测两个用户之间的互动可能性。您和推文作者之间的Real Graph得分越高,就会包括更多他们的推文。
网络内源最近在Twitter上进行了研究。最近他们停止使用Fanout Service,这是一个12年前的服务,以前用于从每个用户的推文缓存中提供网络内推文。最近Twitter还在重新设计逻辑回归排名模型,该模型最后一次更新和训练是几年前。
在用户的网络之外查找相关的推文是一个更加棘手的问题:如果您不关注作者,那么该如何确定某个推文对您来说是否相关?Twitter采取了两种方法来解决这个问题。
第一种方法是通过分析您关注的人或具有类似兴趣的人的互动情况来估计您可能感兴趣的内容。
通常通过遍历互动和关注的图来回答以下问题:
Twitter根据这些问题的答案生成候选推文,并使用逻辑回归模型对结果进行排名。这种类型的图遍历对于网络外推荐至关重要。Twitter开发了GraphJet,一个图处理引擎,用于执行用户和推文之间的实时互动图遍历。
虽然在Twitter的互动和关注网络中搜索的这种启发式算法已经被证明非常有用(目前它们大约占主页时间线推文的15%),但嵌入空间方法已成为网络外推文的更大来源。
嵌入空间方法旨在回答一个更一般的有关内容相似性的问题:哪些推文和用户与我的兴趣相似?
嵌入工作是通过生成用户兴趣和推文内容的数值表示来实现的。然后,我们可以在这个嵌入空间中计算任意两个用户、推文或用户-推文对之间的相似度。只要我们生成准确的嵌入,我们就可以将这种相似度用作相关性的替代指标。
Twitter最有用的嵌入空间之一是SimClusters。SimClusters使用自定义的矩阵分解算法发现由一组有影响力的用户锚定的社区。每三周更新一次,共有145,000个社区。用户和推文在社区空间中表示,并可以属于多个社区。社区的规模从个人朋友圈的几千个用户到新闻或流行文化的数亿个用户不等。
以下是一些最大的社区:

For You时间线的目标是为您提供相关的推文。正常情况,Twitter有大约1500个可能相关的候选推文。得分直接预测每个候选推文的相关性,是推文在您的时间线上排名的主要信号。在此阶段,所有的候选推文都被平等对待,不考虑其来源。
排序是通过一个约48M参数的神经网络实现的,该网络不断地根据推文交互进行训练,以优化积极的互动(如点赞、转发和回复)。这个排序机制考虑了数千个特征,并输出十个标签,以给每个推文打分,其中每个标签代表一种互动的概率。最终根据这些分数对推文进行排名。
在排序阶段之后,Twitter应用各种启发式和过滤器来实现各种产品特性。这些特性共同作用,创建一个平衡和多样化的Feed。
一些例子包括:
以上是 Twitter 推荐算法的流程。在此之后,Home Mixer 会将一系列推文混合在一起,与其他非推文内容,如广告、关注推荐和入门提示等,一起返回到用户设备上显示。
上述流程每天运行约 50 亿次,平均完成时间不到 1.5 秒。单次执行需要 220 秒的 CPU 时间,几乎是你在应用上感知到的延迟的 150 倍。
前面已经介绍了Twitter总体的算法服务和组件,下面是每个组件的介绍:
以上就是Twitter开源的推荐流程算法。不过,这些只是官方博客透露的内容,更重要的是他们将算法代码也开源了!
Twitter推荐服务开源项目地址:https://github.com/twitter/the-algorithm/
Twitter推荐服务中算法模型开源地址: https://github.com/twitter/the-algorithm-ml
Twitter推荐算法官方博客介绍: https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
| Page-Rank algorithm for calculating Twitter User reputation. |
| recos-injector | Streaming event processor for building input streams for GraphJet based services. |
| graph-feature-service | Serves graph features for a directed pair of Users (e.g. how many of User A's following liked Tweets from User B). |
| Candidate Source | search-index | Find and rank In-Network Tweets. ~50% of Tweets come from this candidate source. |
| cr-mixer | Coordination layer for fetching Out-of-Network tweet candidates from underlying compute services. |
| user-tweet-entity-graph (UTEG) | Maintains an in memory User to Tweet interaction graph, and finds candidates based on traversals of this graph. This is built on the GraphJet framework. Several other GraphJet based features and candidate sources are located here |
| follow-recommendation-service (FRS) | Provides Users with recommendations for accounts to follow, and Tweets from those accounts. |
| Ranking | light-ranker | Light ranker model used by search index (Earlybird) to rank Tweets. |
| heavy-ranker | Neural network for ranking candidate tweets. One of the main signals used to select timeline Tweets post candidate sourcing. |
| Tweet mixing & filtering | home-mixer | Main service used to construct and serve the Home Timeline. Built on product-mixer |
| visibility-filters | Responsible for filtering Twitter content to support legal compliance, improve product quality, increase user trust, protect revenue through the use of hard-filtering, visible product treatments, and coarse-grained downranking. |
| timelineranker | Legacy service which provides relevance-scored tweets from the Earlybird Search Index and UTEG service. |
| Software framework | navi | High performance, machine learning model serving written in Rust. |
| product-mixer | Software framework for building feeds of content. |
| twml | Legacy machine learning framework built on TensorFlow v1. |