国产开源中文大语言模型再添重磅玩家:清华大学NLP实验室发布开源可商用大语言模型CPM-Bee
3,257 views
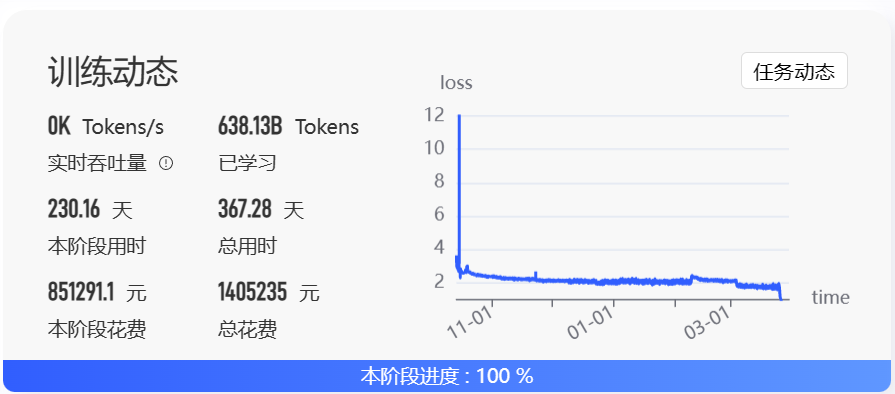
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。
此前,国产开源大语言模型最强的应该是ChatGLM-6B(https://www.datalearner.com/ai-models/pretrained-models/ChatGLM-6B ),这也是清华大学研究成果,是清华大学KEG小组发布的,在国内外都有很好的反响,截止5月26日,ChatGLM-6B 全球下载达到200万。相比较ChatGLM-6B,CPM-Bee的主要特点如下: