国产大模型进展神速!清华大学NLP小组发布顶尖多模态大模型:VisCPM,支持文本生成图片与多模态对话,图片理解能力优秀!
大模型的发展正在从单纯的语言模型向多模态大模型快速发展。尽管GPT-4号称也是一个多模态大模型,但是受限于GPU资源,GPT-4没有开放任何多模态的能力(参考:https://www.datalearner.com/blog/1051685866651273 )。目前大家所能接触到的多模态大模型很少。今天,清华大学NLP小组带来了新的选择,发布了VisCPM系列多模态大模型。VisCPM系列包含2类多模态大模型,分别针对多模态对话和文本生成图片进行优化。
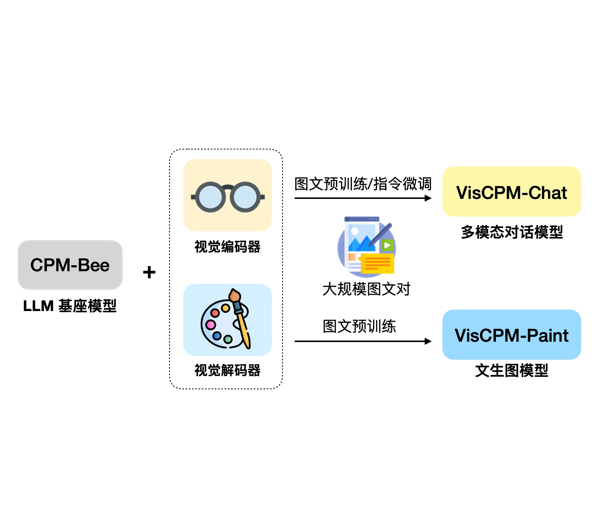
VisCPM多模态大模型简介
VisCPM由清华大学NLP小组基于CPM-Bee-10B进行多模态扩展得到。CPM-Bee-10B是参数规模为100亿的大语言模型,也是由该小组开源,该模型的评测结果英文水平与LLaMA-13B相当,中文水平在ZeroCLUE评测排行榜上仅次于人类排名第二。是一个非常优秀的大语言模型,最重要的是免费商用授权(详情参考CPM-Bee-10B模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/CPM-Bee )。因此,也获得了很多人的关注。
VisCPM是以CPM-Bee 10B为基础模型,增加视觉编码器(Q-Former)和视觉解码器(Diffusion-UNet)后得到。VisCPM模型在超过1亿的图文对数据上进行训练得到,对图片的理解能力非常好。VisCPM系列包含4个模型,分别针对多模态对话(VisCPM-Chat系列)和文本生成图片(VisCPM-Paint系列)两类认为调优得到:
从上面的VisCPM模型分类可以看到,官方应该是针对多模态对话和文本生成图片两类任务对VisCPM分别做了针对性调优,使其分别可以更好地适应不同的任务。同时,区分了语言版本。从介绍来看,由于CPM-Bee-10B语言模型本身中英文能力都很好,因此官方最早应该是基于英文图文数据集做了模型的训练。然后收集了更多高质量的中文图文数据集继续训练模型得到新的对中文理解力更好的模型。
关于VisCPM多模态大模型的训练细节和使用的训练数据这部分内容大家就参考模型信息卡的信息吧。 VisCPM-Chat模型信息卡:https://datalearner.com/ai/pretrained-models/VisCPM-Chat VisCPM-Paint模型信息卡:https://datalearner.com/ai/pretrained-models/VisCPM-Paint
VisCPM多模态大模型效果
目前,官方没有搭建HuggingFace的space,也没有提供官网的演示地址,只发布了一些样例结果和评测结果。从发布的数据看,VisCPM模型对图片的理解真的很好。
VisCPM-Chat的多模态对话效果
首先,VisCPM-Chat模型可以很好地理解图片内容而不受到一些背景的干扰,效果十分惊艳:
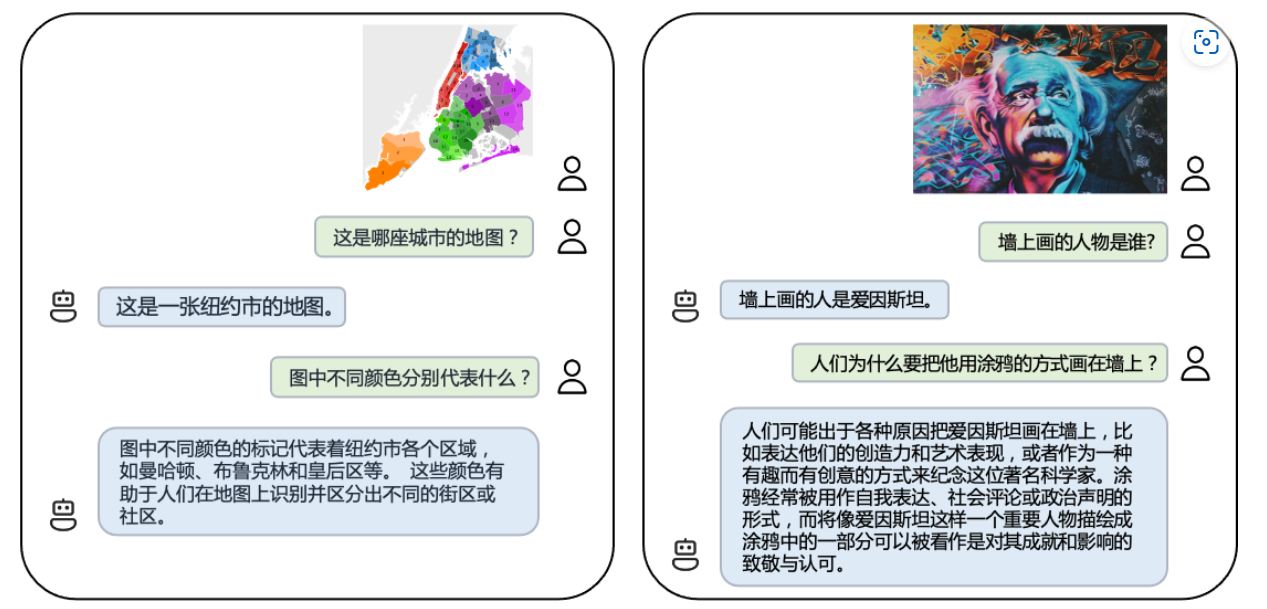
上面的例子可以看到,染色的地图与涂鸦的爱因斯坦都可以被VisCPM准确理解,这一点十分难得。官方在LLaVA的英文评测上对VisCPM和V其它模型做了评测对比,可以很清楚看到VisCPM-Chat表现十分稳定,在中英文评测结果上都是非常优秀。
在中文评测结果种,VisCPM-Chat效果遥遥领先,应该是VisCPM-Chat加了很多中文数据集的原因。
VisCPM-Paint图片生成评测效果
话不多说,直接上图:

效果是不是非常好?非常清晰,而且从图中也可以看到不同的风格下生成质量都很高。官方做了评测以及和各大模型的对比,使用的是Zero-shot FID指标。
Zero-shot FID指标是针对图片生成结果与原图之间对比的计算值。这个值越小,代表生成模型的效果越好(官方文档就这么个图片我一眼还以为模型一般,结果指标是反的,哭死)。FID各个分值段大致含义如下:
- FID 小于10: 代表生成效果非常好,可以视为告一段落。
- FID在10-20之间: 代表生成效果还可以,但仍存在明显差异。
- FID在20-50之间: 生成效果比较一般,可以继续改进。
- FID大于50: 生成效果相差很大,模型需要进一步优化。
- FID值越高,代表生成图片集和真实图片集特征分布间的差异越大,模型生成效果越差。
可以看到,VisCPM-Paint基本都是10以内,代表模型的效果是非常可以的。
VisCPM的开源、使用和其它资源
首先要强调的是,VisCPM不是一个免费商用开源协议。对于个人用户和科研来说,这个系列的模型完全免费开放。但是官方的内容显示如果要商用是需要申请授权的,而且应该是收费授权协议,但是具体协议内容并没有透露,需要大家自己邮件申请。
但是,VisCPM的预训练结果是公开可下载的:
VisCPM对资源要求较高,不加限制使用需要40G的显存,采用CUDA压缩显存(export CUDA_MEM_SAVE=True)之后需要22G,但是推理时间会比较长。所以这个我也没办法测试了。大家看官网内容使用吧。
关于VisCPM多模态大模型的训练细节和使用大家也是依然参考模型信息卡的信息吧。 VisCPM-Chat模型信息卡:https://datalearner.com/ai/pretrained-models/VisCPM-Chat VisCPM-Paint模型信息卡:https://datalearner.com/ai/pretrained-models/VisCPM-Paint
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
