智谱AI开源多模态推理大模型GLM-4.1V-Thinking:90亿参数,基于强化学习技术,带推理能力,多模态理解能力接近720亿的Qwen2.5-VL-72B,免费商用授权
GLM-4.1V-Thinking是智谱AI(Zhipu AI)与清华大学KEG实验室联合推出的多模态推理大模型。这款模型并非简单的版本迭代,而是通过一个以“推理为中心”的全新训练框架,旨在将多模态模型的能力从基础的视觉感知,推向更复杂的逻辑推理和问题解决层面。多模态理解能力接近720亿的Qwen2.5-VL-72B。

本次发布的模型有2个版本,分别是基础版本的GLM-4.1V-Base和带推理能力的GLM-4.1V-Thinking。
GLM-4.1V-Thinking的核心亮点:推理为核,全面进化
GLM-4.1V-Thinking 的发布并非孤立事件,它伴随着一个基础模型 GLM-4.1V-9B-Base 共同开源。也是智谱训练模型的一个顺序。首先,智谱构建一个潜力巨大的视觉语言基础模型GLM-4.1V-9B-Base,再通过精细化的对齐和强化学习,充分释放其在复杂任务上的推理潜能。
该模型的核心亮点可以概括为以下几个方面:
- 卓越的通用推理能力:模型在多个需要深度推理的领域表现突出,可以解决科学、技术、工程和数学(STEM)问题,在长文档理解、图形用户界面(GUI)智能体交互以及多模态代码生成等复杂场景也有很好的效果。
- 越级挑战的性能表现:作为一款9B参数规模的模型,GLM-4.1V-Thinking 在多达28个公开基准测试中,不仅全面优于同量级的开源模型,更在18个基准上取得了超越或持平于体量远大于自身的 Qwen2.5-VL-72B 的成绩。在部分高难度任务上,其表现甚至可以媲美甚至超越闭源标杆 GPT-4o。
- 创新的“三段式”训练框架:模型并非依赖单一技术,而是构建了一套“大规模预训练 → 指令精调对齐 → 强化学习激发”的完整流程。这个框架系统性地解决了如何将模型的潜力转化为实际能力的行业难题。
- 双模型开源的社区贡献:智谱AI不仅开源了最终性能强大的 GLM-4.1V-9B-Thinking,还提供了坚实的 GLM-4.1V-9B-Base 模型。这为研究者和开发者提供了绝佳的平台,既可以直接使用性能顶尖的模型,也可以在高质量的基座上进行二次开发和创新。
GLM-4.1V-Thinking的实测结果接近Qwen2.5-VL-72B,部分指标超GPT-4o
GLM-4.1V-Thinking 在横跨8大类、28个主流多模态基准测试中的表现非常惊喜。

从这个评测结果数据中,我们可以看到下面几个关键情况:
- 对标同级开源模型:与相同参数规模的模型对比,GLM-4.1V-9B-Thinking 几乎在各个领域都实现了性能的全面引领。
- 实现越级性能:与参数量是其8倍的Qwen2.5-VL-72B相比,GLM-4.1V-Thinking在MMMU-Pro、ChartMuseum和MMLongBench-Doc等多个挑战性极高的基准上均大幅领先,充分展示了其卓越的效率和架构优势。
- 媲美闭源顶级模型:最令人瞩目的是,在MMStar、MUIRBENCH、MathVista等多个高难度学术和推理基准上,GLM-4.1V-Thinking的表现甚至超越了GPT-4o。这表明在特定复杂推理任务上,这意味着继续迭代升级,我们可能很快就有开源的媲美GPT-4o多模态理解能力的模型可用了,非常令人期待。
技术突破:可扩展强化学习框架(RLCS)详解
智谱开源的这个多模态推理大模型一个很重要的创新是引入了**可扩展强化学习与课程采样(Reinforcement Learning with Curriculum Sampling, RLCS)**机制,我们简单介绍一下。
为什么需要强化学习?
传统的多模态模型在经过监督微调(SFT)后,虽然能理解指令并生成内容,但在处理需要多步骤、长链条思考的复杂问题时,往往力不从心。智谱AI认为SFT阶段的核心作用并非注入新知识,而是将模型的输出格式与人类期望的“思考过程(<think>)+最终答案(<answer>)”对齐。这一步仅仅是“扶上马”。
要让模型学会如何“跑得好、跑得远”,就需要强化学习(RL)阶段。RL通过一个精密的奖励系统,对模型的每一步思考和最终答案进行评估和反馈,引导模型自主探索更优的解题路径,从而真正提升逻辑推理的质量和准确性。
核心机制:课程学习与课程采样(RLCS)
强化学习的挑战在于效率和稳定性。如果训练样本过于简单,模型学不到新东西;如果过于困难,模型又会因频繁受挫而难以收敛。RLCS 正是为此而设计。
该机制巧妙地融合了“课程学习”(Curriculum Learning)的思想,即由易到难地安排学习内容。它在训练过程中实时评估每个样本对于当前模型的难度,并动态调整采样策略:
- 降低简单样本权重:对于模型已经能轻松解决的“送分题”,降低其出现的概率,避免计算资源浪费。
- 提升中等难度样本权重:重点关注那些处于模型能力“甜点区”的题目,即模型需要努力思考才能解决的问题,这是学习效率最高的区域。
- 暂时搁置过难样本:对于远超模型当前能力的“登天题”,也暂时降低其权重,待模型能力提升后再进行挑战。
通过这种动态的“因材施教”,RLCS 显著提升了训练效率和模型的性能上限。技术报告中的数据显示,在引入RL后,模型在多个任务上的准确率获得了高达 +7.3% 的巨幅提升,直观地证明了该框架的有效性。
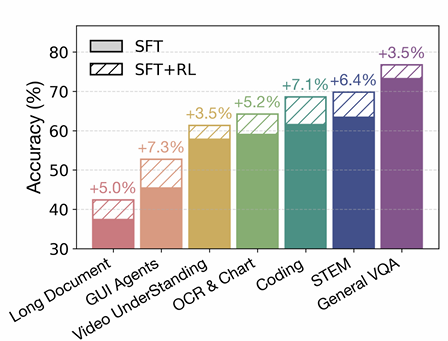
上图清晰展示了,相较于仅经过SFT的模型,增加了RL训练后,模型在各个维度的能力均得到了实质性增强。
GLM-4.1V开源情况和总结
GLM-4.1V-Thinking 的发布,为多模态领域的研究和应用注入了新的活力。最关键的是,这两个模型都是MIT开源协议开源的,意味着可以完全免费商用!且消费级显卡也能部署!(18GB显存以上,量化后可以期待更低显存资源)
关于GLM-4.1V-9B模型的开源地址和在线演示地址可以参考DataLearnerAI的大模型信息卡:
GLM-4.1V-9B-Thinking:https://www.datalearner.com/ai-models/pretrained-models/GLM-4_1V-9B-Thinking GLM-4.1V-9B-Base:https://www.datalearner.com/ai-models/pretrained-models/GLM-4_1V-9B-Base
