Google开源多模态大模型Gemma3n的正式版:重新定义端侧AI的多模态能力,10B(100亿)参数以下最强多模态大模型,一个月前的预览版正式转正
Gemma系列大模型是Google在2024年开源的系列模型,和Google的Gemini系列模型的技术同源,但是规模尺寸较小,开源了出来可以免费使用。
2025年3月份,Google开源了第三代Gemma系列(但是Gemini还是2.5版本,很奇怪),并在6月初开源了全新的多模态版本,即Gemma3n的预览版。今天Google正式将预览版的Gemma3n转正。

Gemma3n是一个转为移动端设计的端侧多模态大模型
继Gemma系列模型发布并迅速形成超过1.6亿次下载的繁荣生态后,Google再次推出了其在端侧AI领域的重磅力作——Gemma 3n。这款模型并非一次简单的迭代,而是基于全新的移动优先(mobile-first)架构,旨在为开发者提供前所未有的设备端多模态处理能力。Gemma 3n的定位是成为一款高效、强大且灵活的开源模型,直接与设备端AI领域的其他先进模型(如Phi-4、Llama系列的小参数版本)竞争,其核心特性在于原生支持图像、音频、视频和文本输入。
2025年5月21日,Google发布了gemma3n的预览版,一个月后的今天,Google发布了一个更新版本,即Gemma3n正式版。
Gemma-3n包含2个不同参数规模(20亿和40亿版本),每一个参数规模模型包含基座版本和指令调优版本。也就是4个版本的模型。
对于广大开发者而言,端侧模型的性能与资源消耗之间的平衡一直是核心痛点。选择一款既能满足复杂应用场景(如实时视频分析、离线语音翻译),又能在内存和算力受限的设备上流畅运行的模型至关重要。
而Gemma3n最大的创新是采用了不同模态分层的概念。即Gemma-3n可以处理文本、图片、视频和音频,生成文本,在140多种语言语料上训练得到。
核心架构创新:MatFormer、PLE与KV缓存
Gemma 3n的卓越性能源于其底层架构的颠覆性设计,其中三大创新尤为引人注目,这也是社区讨论中热度最高的技术要点。
MatFormer:一个模型,多种尺寸
Gemma 3n的核心是其新颖的 MatFormer(🪆Matryoshka Transformer)架构,它将“套娃”(Matryoshka)的概念从嵌入层扩展到了整个Transformer模型。简单来说,一个更大的模型(E4B)内部完整地包含了一个更小的、功能齐全的子模型(E2B)。
这种设计为开发者带来了前所未有的灵活性:
- 预提取模型:开发者可以直接下载使用性能最高的E4B(8B原始参数,4B有效参数)模型,或选择官方已提取好的E2B(5B原始参数,2B有效参数)子模型,后者可提供高达2倍的推理速度提升。
- 自定义尺寸 (Mix-n-Match):通过调整前馈网络隐藏层维度、选择性跳过某些层等方式,开发者可以在E2B和E4B之间精确“切片”,创造出满足特定硬件限制的自定义大小模型。Google为此发布了MatFormer Lab工具,帮助开发者找到最佳配置。
未来,MatFormer架构还将支持弹性执行(elastic execution),允许单个部署模型根据任务负载动态切换推理路径,实现性能与功耗的实时平衡。
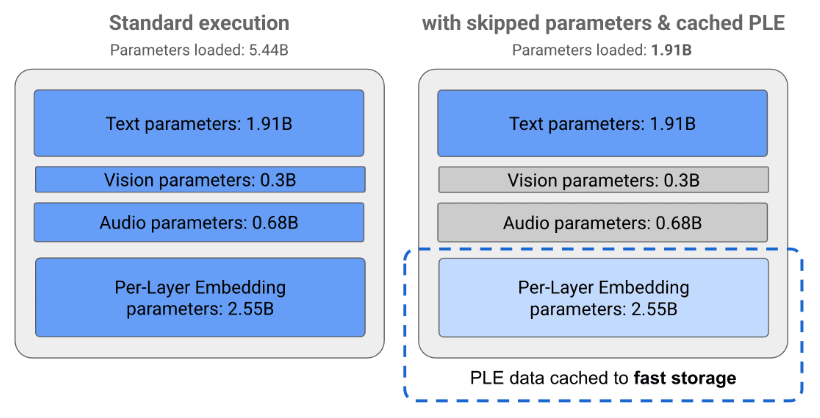
Per-Layer Embeddings (PLE):极致的内存效率
为了进一步优化内存占用,Gemma 3n引入了Per-Layer Embeddings (PLE) 技术。这项创新允许模型将大量的参数(每层的嵌入)存储在CPU内存中,并在需要时高效加载计算,而只有核心的Transformer权重(E2B约2B,E4B约4B)需要常驻在GPU/TPU等高速缓存(VRAM)中。
这意味着,Gemma 3n的E2B模型虽然总参数量为5B,但在实际运行时,对设备加速器内存的占用仅与传统的2B模型相当(约2GB),这对于内存极其有限的移动设备而言是一项决定性的优势。
KV Cache Sharing:加速长上下文处理
对于音频、视频流等长序列输入,Gemma 3n通过KV Cache Sharing技术显著提升了处理速度。该技术在预填充(prefill)阶段,将中间层的键值(KV)缓存直接共享给所有顶层,与前代模型相比,首个Token生成(time-to-first-token)的性能提升了2倍。这使得模型能更快地理解长篇指令或连续的音视频流,为实时交互应用奠定了基础。
Gemma-3n系列模型的核心能力:多模态十分出色
Gemma 3n最大的亮点之一是其原生、高效的多模态处理能力,尤其是在音频和视觉方面取得了重大突破。
音频理解:内置语音识别与翻译
Gemma 3n集成了基于Universal Speech Model (USM) 的高级音频编码器,能够将音频以每秒约6个Token的粒度进行编码。这使其具备了强大的设备端音频处理能力:
- 自动语音识别 (ASR):直接在设备上实现高质量的语音转文本。
- 自动语音翻译 (AST):将一种语言的口语直接翻译成另一种语言的文本,尤其在英语与西班牙语、法语等语言互译时表现出色。
尽管当前版本实现限制处理30秒内的音频片段,但其底层流式编码器为未来支持任意长度的低延迟音频流处理留下了空间。
视觉编码器:MobileNet-V5的新高度
在视觉方面,Gemma 3n搭载了全新的MobileNet-V5-300M视觉编码器,实现了端侧视觉理解的SOTA性能。其优势极其显著:
- 极致效率:与Gemma 3中的基线SoViT相比,在Google Pixel Edge TPU上,量化后速度提升13倍,参数量减少46%,内存占用缩小4倍。
- 高吞吐量:在Pixel手机上可实现高达每秒60帧的处理速度,足以支持实时视频分析。
- 灵活性:原生支持256x256、512x512和768x768等多种分辨率输入,允许开发者在细节和性能之间权衡。
Gemma-3n实测性能分析:100亿参数规模以下最强多模态大模型
官方公布的基准测试结果显示,Gemma 3n在多个维度上都表现出色。特别是E4B版本,在LMArena上的得分超过1300,成为首个达到该基准的10B以下参数模型。
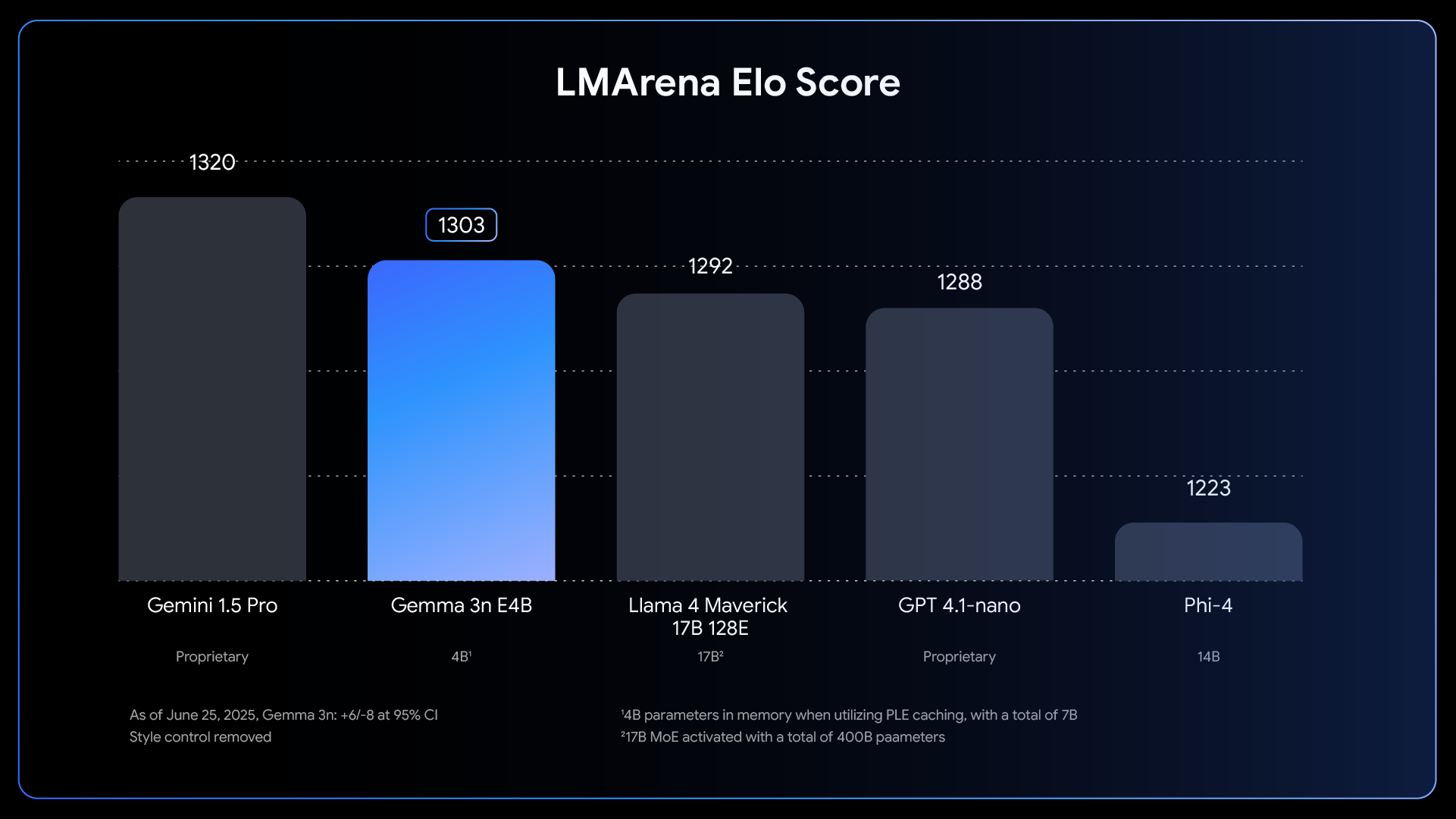
Gemma-3n两个版本模型在不同评测数据集上的表现如下:
推理与事实性
多语言能力
STEM与代码能力
综合来看,Gemma-3n的评测数据有力地支撑了其作为新一代强大开源模型的定位。E4B版本相较于E2B,在几乎所有测试中都实现了显著且一致的性能提升,特别是在知识问答(TriviaQA)、复杂推理(BBH)、代码生成(HumanEval)和多语言数学(MGSM)方面提升幅度最大。
这些数据表明,Gemma 3n不仅在通用推理任务上表现稳健,还在多语言、数学和代码等专业领域取得了显著进步。
Gemma3n总结与未来展望
Gemma 3n的发布,无疑是端侧AI发展的一个重要里程碑。通过MatFormer、PLE和MobileNet-V5等一系列架构层面的创新,它成功地将强大的多模态能力和极致的运行效率结合在一起,解决了开发者在设备端部署AI时面临的核心挑战。
对于开发者社区而言,Gemma 3n不仅是一个性能更强的工具,更是一个充满想象空间的平台。其开源、灵活和高效的特性,将催生更多富有创意的离线AI应用,从实时的个人助理到无障碍辅助工具,再到交互式教育应用。随着未来“弹性执行”等功能的实装,我们有理由相信,Gemma 3n将继续引领端侧智能的发展潮流。
Gemma-3n的开源地址、官方介绍和其它信息参考DataLearnerAI模型信息卡地址
- Gemma-3n-E2B在DataLearnerAI模型页面: Gemma 3n E4B
- Gemma-3n-E4B在DataLearnerAI模型页面: Gemma 3n E4B
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
