谷歌发布Genie 3:一个可以生成720P开启实时交互式虚拟世界生成新纪元
谷歌DeepMind发布了一个全新的大模型——Genie 3,这是一个能够根据文本描述生成多样化、可实时交互虚拟世界的通用世界模型。目前,Genie3可以生成几分钟的720P的视频,且每秒24帧左右。用户也可以在生成的视频中实时交互控制。从谷歌官方的视频看,这个Genie 3模型生成的视频和游戏世界的质量很高,非常令人心动!

什么是世界模型?
在深入了解Genie 3之前,我们首先需要理解“世界模型”(World Model)的概念。世界模型是一种特殊的人工智能系统,它能利用其对世界的理解来模拟世界的方方面面。 这意味着模型不仅可以预测环境将如何演变,还能预见个体的行为将对环境产生何种影响。
简单来说,世界模型是一种能够理解和模拟现实世界动态的生成式人工智能模型,不单单是生成一个视频,但是会理解物理世界的客观规律,例如重力的影响、吃饭的动作等。
世界模型被视为通向通用人工智能(AGI)的关键基石之一,因为它使得在一个无限丰富的模拟环境中训练AI代理(agent)成为可能。
谷歌DeepMind十多年来一直在该领域进行前沿研究,从训练AI掌握即时战略游戏,到为机器人开发开放式学习的模拟环境。
Genie 3正是在此前的Genie 1、Genie 2以及视频生成模型Veo的基础上,首次实现了实时互动,并在环境一致性和真实感方面取得了显著提升。
Genie 3的核心特点与能力
Genie 3最突出的能力在于它能够将简单的文本提示转化为一个动态的、可探索的世界。用户可以在这个生成的世界中以每秒24帧的速度实时导航,并且画面能在720p的分辨率下保持数分钟的一致性。
如何理解这个能力呢?Google官方给的视频很好的解释。例如,你生成了一个视频,你在墙上用蓝色的油漆刷墙,此时你可以控制视频的你走到另一个房间,这是你刷墙的画面就消失了,然后你返回到这个房间,墙上的油漆涂抹形状不变。



这个视频非常通俗易懂的展示了世界模型Genie 3生成的视频的一致性。
Genie 3核心能力可总结为以下几点:
- 物理属性建模:模型能够模拟自然现象,如水流、光照,以及复杂的环境互动。例如,它可以生成火山区域的崎岖地形,或是在飓风来临时海浪拍打路面的场景。
- 模拟自然世界:Genie 3可以创造充满活力的生态系统,从动物行为到复杂的植物形态。用户可以体验在冰川湖畔奔跑,或是在深海中与水母群共游的景象。
- 动画与虚构场景建模:该模型能将想象力变为现实,创造奇幻的场景和生动的动画角色,比如一只毛茸茸的生物在彩虹桥上奔跑,或是一个折纸风格的蜥蜴世界。
- 探索地点与历史场景:Genie 3能够跨越地理和时间的界限,重现历史遗迹(如克诺索斯宫殿)或世界各地的真实地点(如威尼斯运河)。
- 长时程环境一致性:尽管逐帧自回归地生成环境极具技术挑战,但Genie 3生成的环境能在几分钟内保持高度的物理一致性。例如,即使一个物体在画面中消失后再次出现,其状态和位置也能保持不变。 这种一致性是一种“涌现能力”,与依赖显式三维表征的NeRFs等技术不同,Genie 3逐帧生成的方式使其世界更加动态和丰富。
- 可提示的世界事件(Promptable World Events):除了导航操作,用户还可以通过文本指令来改变世界。这是一种更具表现力的交互形式,例如改变天气、引入新的物体或角色等,极大地增强了互动体验。
Genine与其它模型,特别是视频生成大模型的对比
为了更加清晰的展示世界模型Genie3与其它模型,特别是视频生成大模型的差异,Google官方还给出了Genie3模型和其它模型的对比总结:
从上表可以看出,Genie 3的创新并非单一维度的提升,而是一次能力的融合与超越。它不像Veo那样只能生成供人观看的“电影”,也不像NeRFs那样需要基于现有数据重建一个相对静态的“场景”。Genie 3真正做到了“创世”:它从零开始,仅根据文本描述和用户的实时指令,一帧一帧地构建出一个动态的、有物理逻辑、并且可以持续互动的世界。这种将高质量生成、物理一致性与实时交互性三者结合的能力,是其与所有前代技术最根本的区别,也是其价值的核心所在。
Genie3应用场景与价值
作为一个通用的世界模型,Genie 3的出现为多个领域带来了巨大的应用潜力。
下图是当前Google放出的一些生成的视频截图,这些视频都是可以控制在场景中进行探索的:
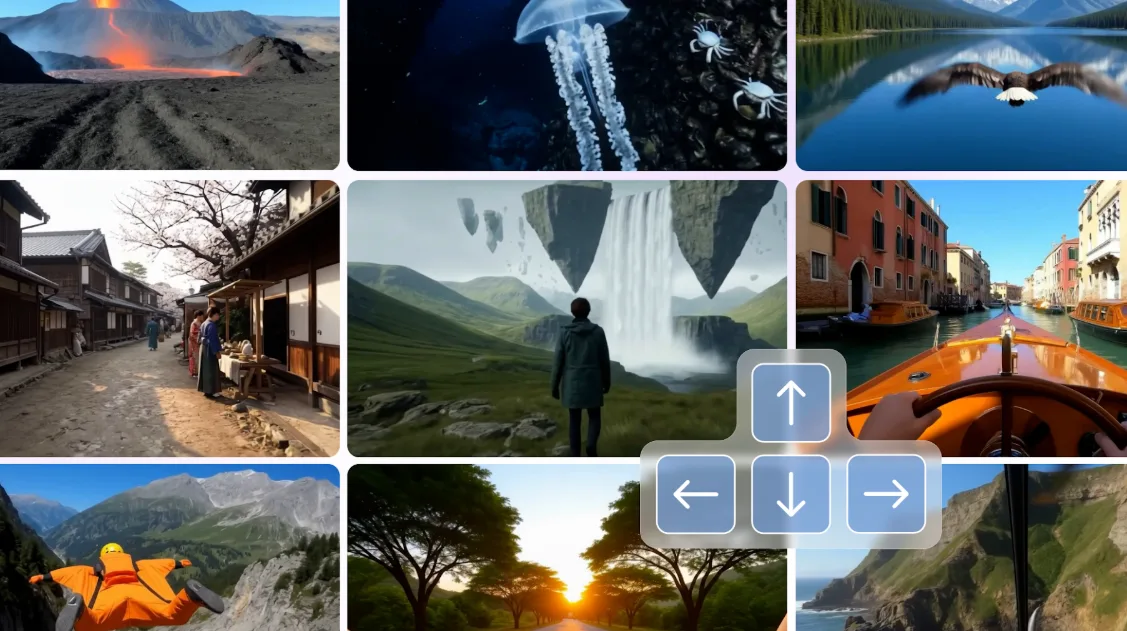
最直接的价值体现在**“具身智能代理(Embodied Agent)”的研究**上。研究人员已经将Genie 3生成的世界用于测试谷歌的通用代理SIMA。 在这些虚拟环境中,SIMA被赋予不同的目标,并通过向Genie 3发送导航指令来尝试完成任务。 由于Genie 3能够保持环境的一致性,AI代理现在可以执行更长、更复杂的动作序列,从而实现更具挑战性的目标。 这项技术将成为推动AGI发展和让AI代理在世界中扮演更重要角色的关键。
此外,Genie 3的价值还体现在:
- 教育与培训:它可以为学生和专业人士创造全新的学习机会。例如,模拟历史事件供学生体验,或为专家提供一个安全的虚拟环境进行技能训练。
- AI代理的评估与探索:Genie 3能提供一个广阔的测试平台,用于评估AI代理的性能,并探索它们在应对各种“意料之外”情景时的弱点。
- 生成式媒体:作为一种强大的内容创作工具,它有望在电影、游戏和虚拟现实等领域催生新的创意形式。
当前Genie3模型的局限性
尽管Google“吹嘘”了Genie3的诸多优点,但是谷歌DeepMind团队同样坦诚地指出了Genie 3目前存在的局限性,包括不限于:
- 有限的动作空间:尽管“可提示的世界事件”功能强大,但代理本身能直接执行的动作范围目前仍然有限。
- 多代理互动模拟:在共享环境中精确模拟多个独立代理之间的复杂互动,仍然是一个持续的研究挑战。
- 真实世界位置的准确性:Genie 3目前还无法以完美的地理精度模拟真实世界的地点。
- 文本渲染问题:清晰可辨的文本通常只有在输入的世界描述中提供时才能被良好生成。
- 有限的互动时长:模型目前可以支持几分钟的连续互动,而不是长达数小时的扩展体验。
Geinie 3的总结分析
Genie 3的发布无疑是世界模型发展的一个重要时刻,它标志着AI生成内容从静态的图像、视频,走向了动态、可实时交互的“世界”。这不仅是一项技术上的飞跃,更预示着AI研究和生成式媒体的未来将深度融合。
不过遗憾的是,目前这个模型并没有开放使用。当前,Genie 3仅作为有限的研究预览版,提供给一小部分学者和创作者进行早期测试。 这种方法有助于在技术发展的早期阶段收集关键反馈,理解潜在风险并制定适当的缓解措施。
随着技术的成熟和局限性的克服,像Genie 3这样的世界模型将可能成为下一代数字内容的基础设施。它不仅将彻底改变AI代理的训练方式,加速AGI的到来,还可能为教育、娱乐和专业培训等行业带来颠覆性的变革。我们正在见证一个由AI驱动、人人皆可创造和探索虚拟世界的时代的开启。
关于Genie3模型的其它信息可以参考DataLearnerAI大模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/genie-3
