Google开源CodeGemma编程大模型和RNN架构大模型RecurrentGemma,同等参数规模最强编程大模型以及更快的大模型
Gemma系列是谷歌开源的与Gemini同源的小规模参数版本的大语言模型,此前只有70亿参数和20亿参数的Gemma大语言模型。而现在,Google又开源了2个系列的新的大模型:一个是编程大模型CodeGemma系列,一个是基于RNN架构新型大模型RecurrentGemma。

CodeGemma系列大模型简介
CodeGemma是谷歌开源的编程大模型,它是用Gemma系列模型继续在代码数据集上训练得到的。Google共开源了3个版本的CodeGemma模型,分别是CodeGemma-7B、CodeGemma-7B-IT以及CodeGemma-2B。三者的关系如下:
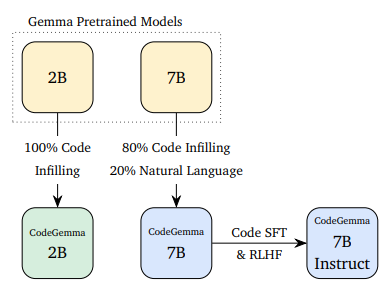
可以看到,CodeGemma-2B模型是Gemma-2B模型在全部的代码补全数据集上继续训练得到的。而CodeGemma-7B模型则是用Gemma-7B模型在80%的代码补全数据集以及20%的自然语言数据集上进行训练得到。在此基础上,继续使用代码有监督微调和**基于人类反馈的强化学习(RLHF)**方式进行指令对齐,得到指令优化版本的CodeGemma-7B-IT模型,这里的IT就是Instruct的缩写。
根据谷歌的论文,谷歌使用的新的代码数据集包含了5000亿tokens的代码数据、开源数学数据以及网络文档数据。
从这个过程也可以看到,这三个模型可以完成不同的任务:
CodeGemma评测结果
CodeGemma模型是编程大模型,所以Google也详细评测了它的编程能力。在最常见的代码评测HumanEval和MBPP以及数学能力MATH上,CodeGemma都表现出了同等模型中很好的水平。但是,总体编程性能不如DeepSeek Coder-6.7B模型而理解能力应该是强于DeepSeek模型!。
CodeGemma-7B与其它模型对比结果如下:
| 模型名称 | 模型参数 | HumanEval | MBPP | Math | GSM8K | | ------------ | ------------ | ------------ | ------------ | ------------ | | CodeGemma-7B-IT | 70亿 | 56.1 | 54.2 |41.2 |**20.9 ** | | CodeLLaMA-Instruct-7B | 70亿 | 34.8 | 44.4 | | 13.0| | DeepSeek Coder Instruct - 6.7B | 67亿 | 66.1 |65.4 | 28.6|62.8 | | StarCoder2 | 160亿 | 28.0 | 42.8 | 40.4 |||
可以看到,虽然相比较其它模型CodeGemma-7B都表现出强大,但是还是稍逊于DeepSeek Coder-6.7B模型。上述模型的具体信息可以参考DataLeanerAI模型信息卡:
在全球主要的模型编程能力对比上,CodeGemma-7B模型很能打,结果如下:
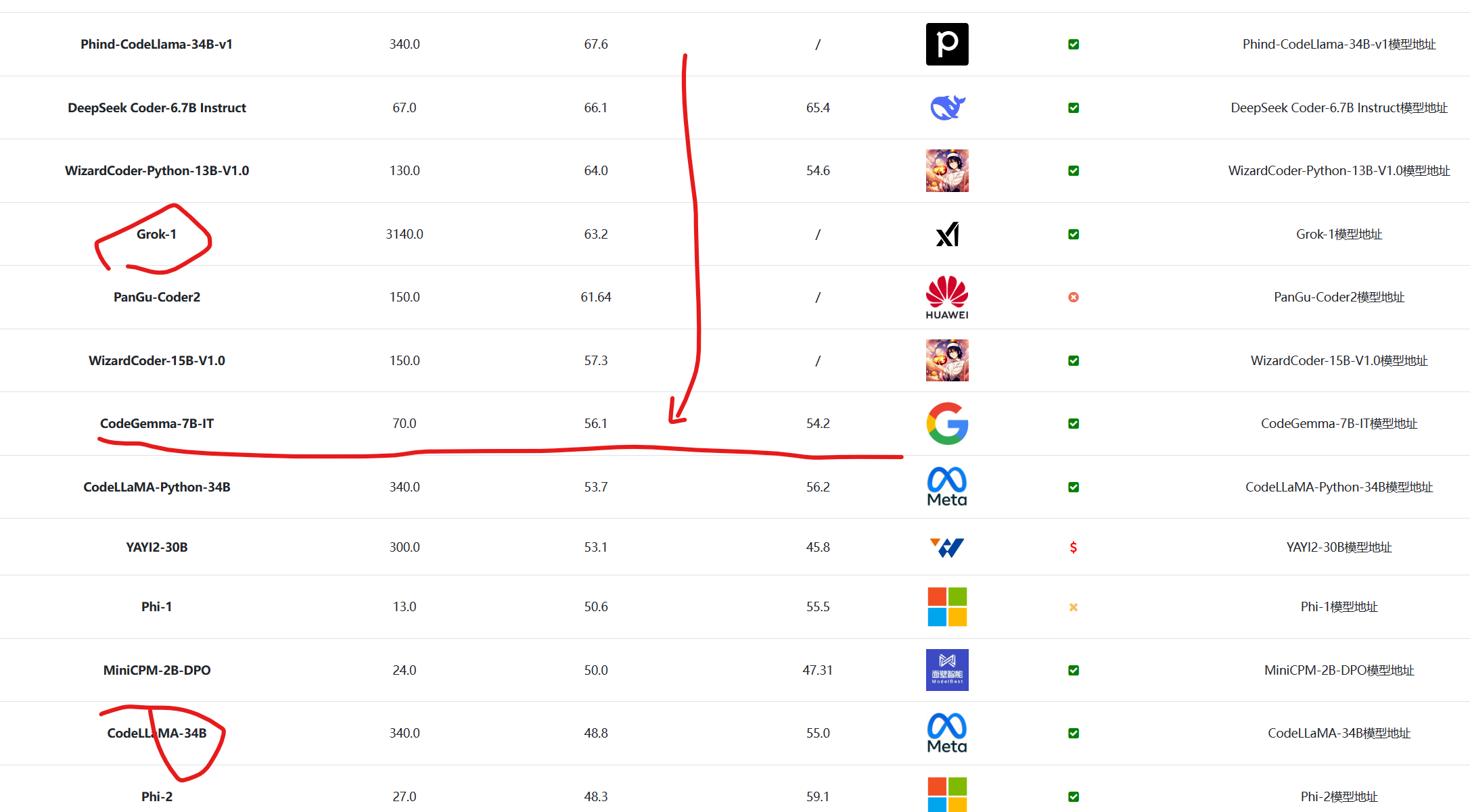
上图是按照HumanEval评测排序的结果,可以看到,CodeGemma-7B甚至接近Grok-1模型,也超过了CodeLlama-34B。
RecurrentGemma模型
本次除了CodeGemma模型外,Google还开源了一个全新架构的模型,就是RNN架构的大模型,称为RecurrentGemma。这个模型仅仅包含了27亿参数。它的评测结果与Gemma-2B差不多,但是因为是全新的RNN架构,所以它最大的意义是希望解决长上下文的问题。
Google称该架构为Griffin架构,它结合线性递归单元(LRU)和局部注意力机制,而非传统的全局注意力。这种架构具有固定大小的状态,可降低内存使用并提高长序列的推理效率。
RecurrentGemma模型最大的特点和价值主要体现在以下几个方面:
- 高效的长序列处理能力 - 通过使用Griffin架构结合线性递归单元和局部注意力,RecurrentGemma能够将输入序列压缩到固定大小的状态中,从而避免了Transformer架构中键值对缓存随序列长度线性增长的问题。这使得RecurrentGemma在处理超长序列时具有显著的内存优势,能够生成任意长度的序列而不受内存限制。
- 高推理效率 - 由于固定状态大小,RecurrentGemma在长序列生成时的推理速度明显快于同等规模的Transformer模型。报告展示,在TPU上,相比Gemma-2B,RecurrentGemma-2B在长序列生成任务上的吞吐量提高数倍。这种高效的推理能力使其更适用于对延迟和计算资源敏感的应用场景。
- 出色的下游任务表现 - 尽管使用了较少的预训练数据(2万亿 vs 3万亿标记),RecurrentGemma-2B在广泛的学术基准测试中表现与Gemma-2B相当,在指令遵从和对话任务的人工评估中也有优异表现,与7B的Mistral模型不相上下。这说明Griffin架构并未牺牲模型的语言理解和生成能力。
- 有效管理训练成本 - 相比Transformer,RecurrentGemma的固定状态使得在TPU等加速器上训练时能获得更高的加速比,从而降低总体的训练成本和资源需求。
Gemma系列总结
谷歌的大模型之路可以说非常“坎坷”,在发力一年多之后的今天,它模型的表现依然与GPT-4有着明显的差距。但是,谷歌的模型的进步十分明显。而最近开始开源的Gemma系列似乎是Google继续在开源大模型方向上一种尝试。Gemma系列虽然不能说是开源模型最强的模型,但是十分出色,整体水平非常优秀。并且免费商用授权!
本次开源的模型地址和其它具体信息可以参考DataLearnerAI模型信息卡地址:
RecurrentGemma-2B:https://www.datalearner.com/ai-models/pretrained-models/RecurrentGemma-2B RecurrentGemma-2B-IT:https://www.datalearner.com/ai-models/pretrained-models/RecurrentGemma-2B-IT codegemma-7b:https://www.datalearner.com/ai-models/pretrained-models/codegemma-7b codegemma-7b-it:https://www.datalearner.com/ai-models/pretrained-models/codegemma-7b-it: codegemma-2b:https://www.datalearner.com/ai-models/pretrained-models/codegemma-2b
关于Google的Gemma系列模型参考DataLearnerAI的介绍:https://www.datalearner.com/blog/1051708523708257
