马斯克大模型企业xAI开源Grok-1,截止目前全球规模最大的MoE大模型,词汇表超过13万!
此前,马斯克在推特上宣布要开源旗下大模型公司开发的Grok-1大语言模型。一周后的现在,这个模型Grok-1正式宣布以Apache2.0开源协议开源,本文将针对Grok-1的技术部分进行介绍。
Grok-1简介
Grok-1是马斯克旗下大模型企业xAI的首个大语言模型商业产品。但他们最早训练的大模型是Grok-0,Grok-0是一个330亿参数的规模较小的模型,它用了Llama2-70B一半的硬件资源就达到了Llama2-70B的水平。因此,xAI研发人员很有信心,继续开发了Grok-1。

Grok-1最早在2023年11月初公开,随后在X平台上使用。此次开源后,Grok-1成为了目前开源大模型中参数最高的一个(除去此前反响平平的1.6万亿的谷歌大模型)。而更重要的是,这也是一个混合专家架构的模型,类似Mixtral 8×7B MoE模型(参考:https://www.datalearner.com/ai-models/pretrained-models/Mistral-7B-MoE )。具体来说,Grok-1模型参数如下:
不过,需要注意的是,Grok-1的训练是在xAI团队自己搭建的平台上,基于JAX等先进的基础设施。本次开源的只有Grok-1的推理代码,不包含训练代码!
Grok-1的表现
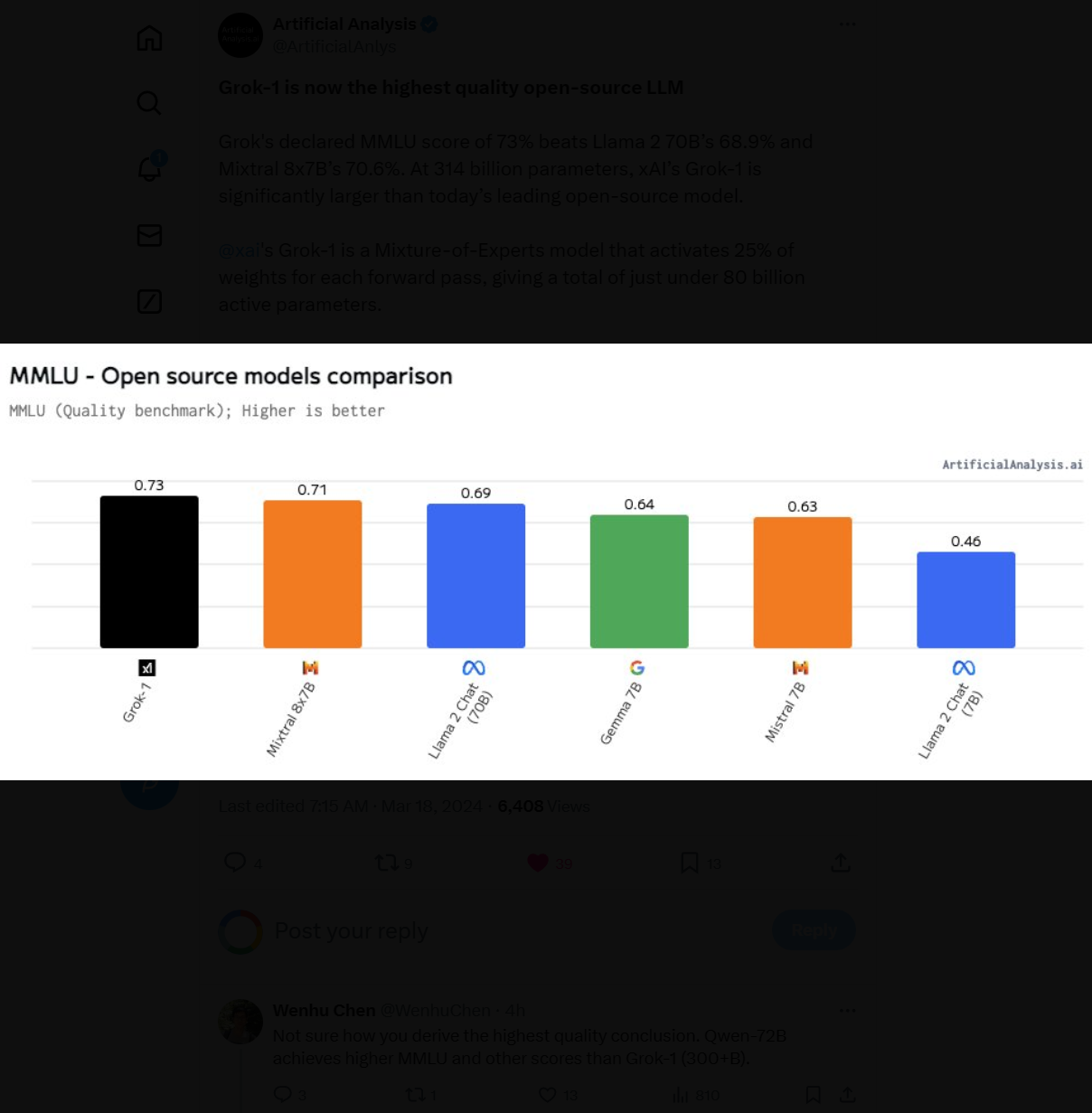
首先,根据11月份透露的数据,Grok-1模型在各项评测结果中表现不错,但并不算突出。其MMLU得分73分,应该说得分超过了GPT-3.5,但是不如Qwen-72B。而数学推理(GSM8K)方面表现更差,不如60亿参数规模的ChatGLM3-6B。要知道,Grok-1的模型总参数是3140亿,每次激活860亿,这个水平相比较而言应该说不令人满意。
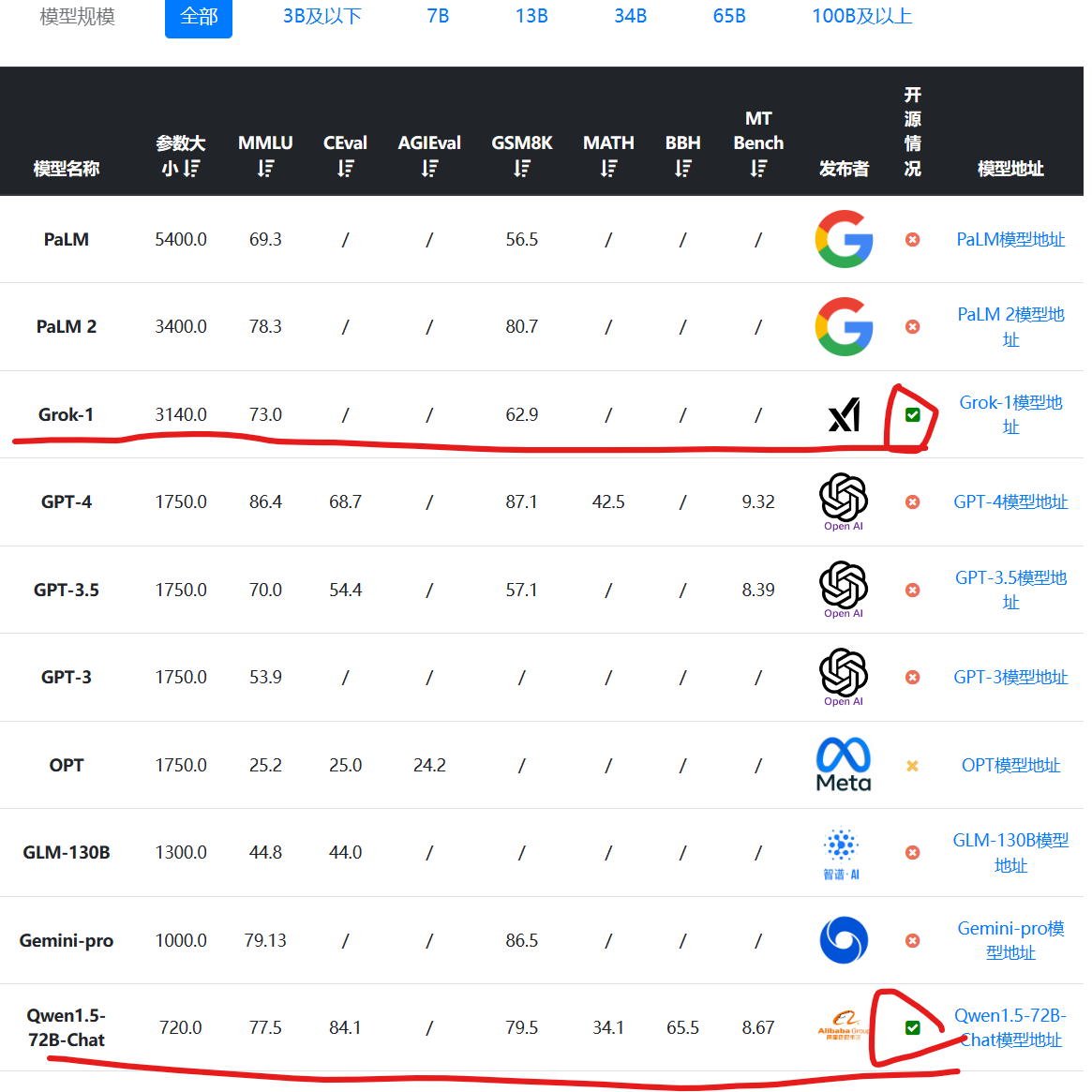
上述数据是按照参数大小排序,可以看到这是目前开源中参数规模最高的大模型了。排第二的开源模型是阿里巴巴的720亿参数规模的Qwen-72B。具体数据参考:https://www.datalearner.com/ai-models/llm-evaluation
Grok-1的推理资源要求
从上面的分析可以看到,Grok-1是一个不错的模型,但是与同类相比劣势比较明显。主要就是在于它资源消耗更大,但是没有获得相应的收益。以它和Mixtral 8×7B MoE模型对比(二者都是混合专家模型):
从上述简单对比可以看到,Grok-1用了远比Mixtral 8×7B MoE模型更多的资源,结果就是MMLU评测略高,而数学推理还不如Mixtral 8×7B MoE。
Grok-1总结
尽管Grok-1已经开源。但是也些关键信息并没有透露。首先,xAI宣称他们是基于一套高效的基础设施进行训练的。这套高效的基础设施架构并未透露。另外,就tokenizer来说,Grok-1包含了13万个tokens,远超Llama系列。而且tokenizer中出来特殊的"[PAD]"、"[BOS]"、"[EOS]"、"[UNK]"外,还有此前**大家没见过的"<|controlX|>"token,这里的X是1-20,它的作用并不清楚**。联想到Grok-1本身作为基础模型,有super prompt、新闻等特殊能力,这部分是不是可能会影响也不知道。原因就是Grok-1的训练代码没有公布。
关于Grok-1的SuperPrompt等能力介绍参考此前的内容:https://www.datalearner.com/blog/1051699114783001
不管怎么说,Grok-1里面还是有新的东西的。至少从主流开源模型的效果看,Grok-1虽然还可以,但不够惊艳。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
