腾讯开源Hunyuan-A13B大模型:MoE架构,混合推理(支持直接回复和带推理过程后回复),原WizardLM团队打造,评测结果超Qwen2.5-72B,接近Qwen3-A22B,但参数量只有一半
2025年6月27日,腾讯发布并开源了其混元大模型系列的新成员Hunyuan-A13B。该模型定位为一个基于细粒度专家混合(MoE)架构的大语言模型。其主要特点是高效率和可扩展性,旨在为开发者和研究人员,特别是在资源受限的环境中,提供高级推理和通用应用能力。Hunyuan-A13B是由原来的微软的WizardLM团队成员打造(二代WizardLM2在2024年开源打败了所有闭源模型,仅次于最新的GPT-4,似乎这件事在微软内部引起了很大的问题,不久后撤回了这个模型,团队成员也离职了,后面加入了腾讯)。

Hunyuan-A13B核心功能与技术特点
Hunyuan-A13B定位非常明确:一个为资源受限环境设计的高性能、高效率的通用大语言模型。它采用MoE(混合专家)架构,总参数800亿,每次推理激活130亿参数。模型最高支持256K的超长上下文推理。
这意味着,Hunyuan-A13B 在实际运行时,其计算开销和内存占用仅与一个13B规模的模型相当,但其知识储备和能力上限却是由800亿总参数决定的。
Hunyuan-A13B模型和Qwen3的混合推理架构类似,引入了一个非常人性化的设计——混合推理模式(Hybrid Inference)。用户可以根据需求,在“快思”(fast thinking)和“慢想”(slow thinking)之间灵活切换。
- 快思模式: 适用于常规问答、文本生成等需要快速响应的场景。
- 慢想模式: 针对复杂的逻辑推理、代码生成或深度分析任务,模型会调用更复杂的推理路径,生成更具深度的思考过程和答案。
模型做过agent方向的优化,在接口调用和任务规划方面有明显的变化。Hunyuan-A13B一共开源了4个版本,分别是基座版本和指令优化的版本,同时提供了指令优化版本的量化版本(分别是FP8和Int4):
- Hunyuan-A13B-Pretrain:基座版本,160GB
- Hunyuan-A13B-Instruct:指令优化版本,160GB
- Hunyuan-A13B-Instruct-FP8:FP8量化,85.88GB
- Hunyuan-A13B-Instruct-GPTQ-Int4:Int4量化,43.7GB
可以看到,Int4量化只有原版模型的1/4!但是性能并没下降很多。
Hunyuan-A13B评测结果:接近Qwen-235B-A22B水平
Qwen-235B-A22B是第三代Qwen3模型中参数规模最大,最强的模型,总参数2350亿,每次推理激活220亿参数,而本次腾讯开源的Hunyuan-A13B模型总参数规模大约是其1/3的,推理参数规模大约是1/2。Hunyuan-A13B 在一系列权威基准测试中的表现,有力地证明了其“小身材,大能量”的特性。
下表展示了 Hunyuan-A13B 与其它模型的对比:
我们可以清晰地看到,激活参数仅13B的 Hunyuan-A13B,在MMLU、EvalPlus、MATH等多个关键指标上,不仅超越了72B的Qwen2.5,甚至与22B激活参数的Qwen3-A22B互有胜负,尤其在代码(EvalPlus)和数学(MATH)能力上表现突出。
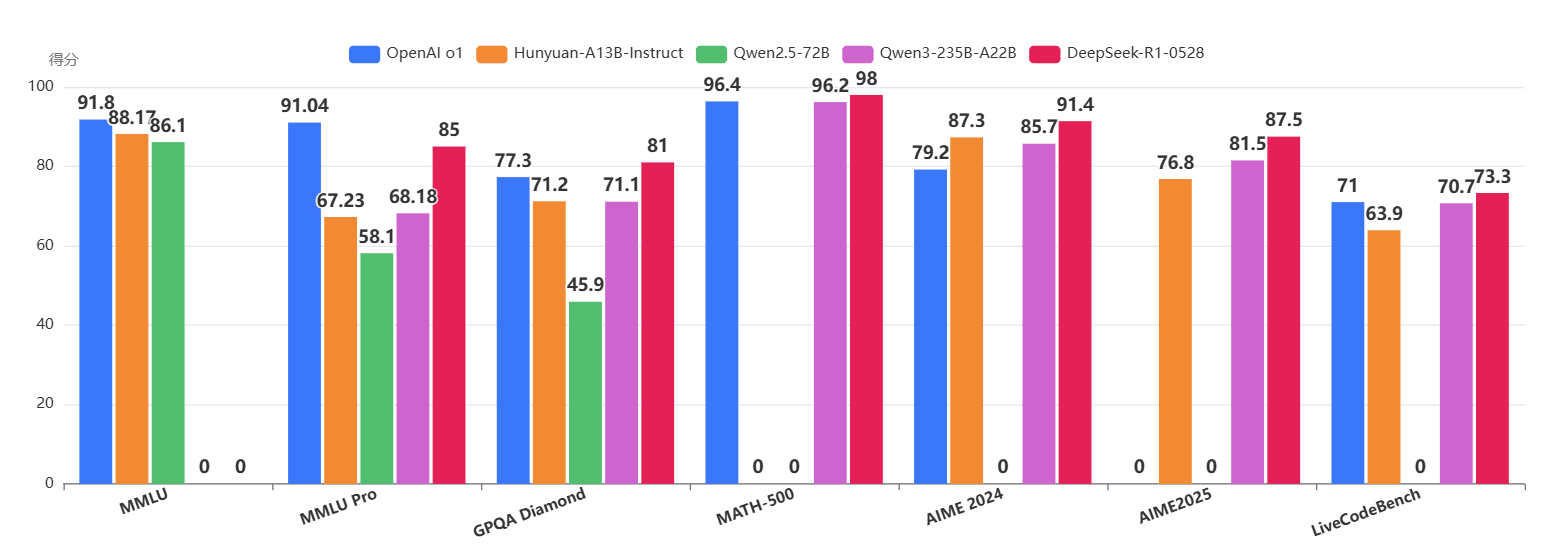
在更细分的领域,如数学、代码、推理和Agent能力上,Hunyuan-A13B 同样展现了强大的竞争力。
特别值得关注的是Agent能力,在BDCL v3基准上,Hunyuan-A13B 大幅领先,这表明其在遵循复杂指令、使用工具等任务上经过了深度优化。其在数学竞赛(AIME)和通用推理(BBH)上的优异表现,也再次印证了其“慢想”模式的强大威力。
Hunyuan-A13B量化压缩:模型规模下降3/4,性能几乎不影响
如果说MoE架构是性能与成本平衡的第一步,那么量化就是通向端侧部署和极致效率的“最后一公里”。腾讯同步推出了FP8和INT4两种量化版本,并预告了即将开源的压缩工具 AngleSlim。
无论是FP8还是INT4量化,模型的性能损失都微乎其微。这意味着开发者可以几乎无损地将模型体积和显存占用压缩数倍,极大地降低了部署门槛,使其在边缘设备或普通消费级显卡上运行成为可能。
Hunyuan-A13B模型的开源情况和其它信息
Hunyuan-A13B目前以腾讯自定义的开源协议来开源,依然是免费商用授权,不过需要注意的是,这个开源协议明确规定,不允许在欧洲联盟、联合王国和韩国地区使用。此外,如果在腾讯混元版本发布之日,你的产品或服务的月活跃用户在最近一个日历月内超过 1 亿月活跃用户也不允许使用哦~
关于Hunyuan-A13B模型的开源地址和更多信息参考DataLearnerAI的大模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/Hunyuan-A13B-Instruct
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
