DataLearner AI A knowledge platform focused on LLM benchmarking, datasets, and practical instruction with continuously updated capability maps.
© 2026 DataLearner AI. DataLearner curates industry data and case studies so researchers, enterprises, and developers can rely on trustworthy intelligence.
Gemma 4 全面解读:首个 Apache 2.0 的 Google 开源模型,实测数学推理优秀,实测部分评测甚至好于 Qwen3.5-27B | DataLearnerAI
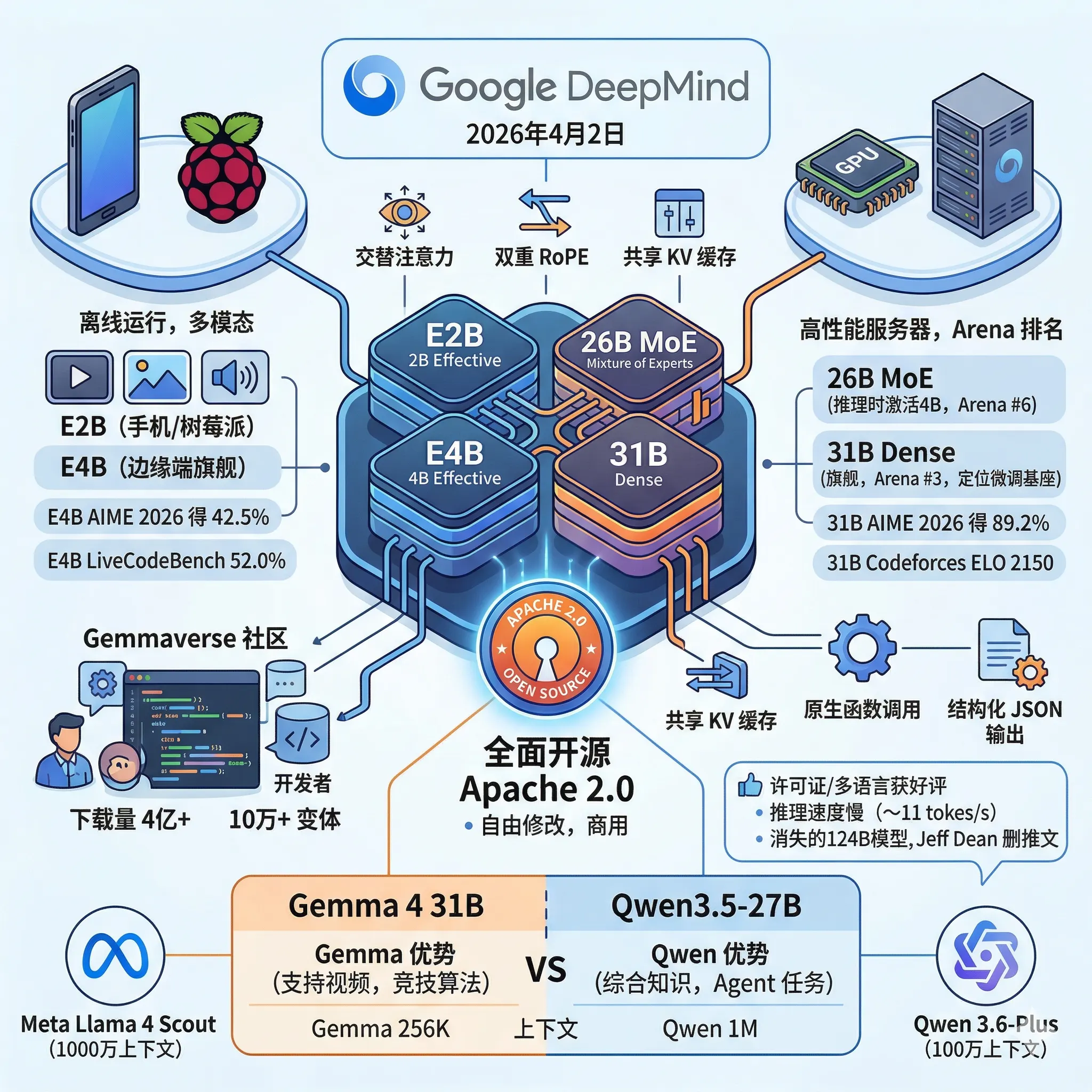
Home / Blog List / Blog Detail 2026年4月2日,Google DeepMind 正式发布了 Gemma 4 系列模型。自2024年首代 Gemma 发布以来,开发者已经累计下载超过4亿次,并在此基础上衍生出超过10万个变体版本,形成了所谓的"Gemmaverse"社区生态。这次的 Gemma 4,Google 不只是做了常规的性能升级,而是在许可证、模型架构和部署覆盖范围上同时迈出了一大步。
Follow DataLearner WeChat for the latest AI updates
四款模型同步发布,首次采用 Apache 2.0 全面开源 Gemma 4 系列共包含四个模型,参数量从20亿到310亿,全部以 Apache 2.0 协议开源发布,支持图像、音频输入和140多种语言。这是 Gemma 系列第一次以标准开源协议发布。之前的 Gemma 版本虽然开放权重,但使用的是 Google 自定义的专有许可证,用户无法自由修改和商业分发。Apache 2.0 协议则允许用户下载、修改和商业使用,只需保留适当的版权声明。
Gemma 4 基于 Gemini 3 相同的研究和技术构建,是目前可以在本地硬件上运行的性能最强的 Google 开放模型系列。这四个模型被划分为两个部署层次:针对手机、树莓派等边缘设备的轻量级系列(E2B、E4B),以及面向消费级 GPU 和高性能服务器的大规模系列(26B MoE、31B Dense)。
尽管谷歌官方宣称Gemma4 E4B和Gemma4 E2B定位均为端侧模型,但是实际上手机端运行的要求比较高。前者总参数量8B,激活参数4.5B,后者总参数量5.1B,激活参数2.3B,虽然激活参数不高,速度可以,但是float16精度下前者至少16G显存,所以可能需要int8量化才可能比较合理。
不过,由于E2B 的推理时有效参数量为20亿,设计目标是在手机、树莓派和 NVIDIA Jetson Orin Nano 上以接近零延迟运行,可以完全离线使用。这个规模的模型做到多模态本身就不容易,E2B 支持128K的上下文窗口。
而 E4B 的定位是边缘设备中的旗舰选项,有效参数量为40亿。这两款边缘模型原生支持视频、图像和音频处理,可用于语音识别和图像理解等任务。E4B 在 AIME 2026 数学推理测试上达到42.5%,在 LiveCodeBench 上达到52.0%——这对一个可以在 T4 GPU 上运行的模型来说相当可观。更值得注意的是,E4B 在大多数 benchmark 上显著超越了没有推理模式的 Gemma 3 27B,参数量却只是后者的零头。
Gemma4 31B Dense 和 Gemma4 26B MoE的总参数量都在30B规模,前者是稠密模型,后者是MoE架构,与Qwen3.5-27B和Qwen3.5-35B-A3B非常接近。
26B MoE 是混合专家架构(Mixture of Experts),总参数量260亿,但推理时只激活约40亿参数。它支持256K的上下文窗口,目前在 Arena AI 文本排行榜上位列开放模型第6名。
不过 Gemma4 26B MoE 模型的 benchmark 表现与 Gemma4 31B 版本非常接近:AIME 2026 得分88.3%,LiveCodeBench 77.1%,GPQA Diamond(研究生水平科学推理)82.3%。考虑到推理成本优势,这个差距相当小。
Gemma4 31B Dense 是 Gemma 4 中的旗舰模型,目前在 Arena AI 文本排行榜上位列全球开源模型第3名,比Qwen3.5-27B的27名高很多。Gemma4 在 AIME 2026 上达到89.2%,LiveCodeBench v6 达到80.0%,Codeforces ELO 为2150,视觉任务上 MMMU Pro 为76.9%、MATH-Vision 为85.6%。Google 把这个版本定位为微调基座,更适合企业做领域专属微调,而非日常直接调用。
Gemma4四款模型共有的架构设计:交替注意力、双重 RoPE 和原生函数调用 Gemma 4 引入了几个值得关注的架构设计:交替注意力机制——解码器层在局部滑动窗口注意力(处理512-1024个 token)和全局全上下文注意力之间交替,兼顾效率与长程理解;双重 RoPE——滑动窗口层用标准旋转位置编码,全局层用比例 RoPE,使大模型在不损失质量的情况下支持256K超长上下文;共享 KV 缓存——后几层复用前层的 KV 张量,大幅降低推理内存占用和计算开销。
函数调用(Function Calling)、结构化 JSON 输出和系统提示(System Prompt)在四个模型中均原生支持,不是事后通过指令跟随实现的。这对构建智能体(Agent)工作流的开发者意义很大——模型天生就知道怎么用工具。
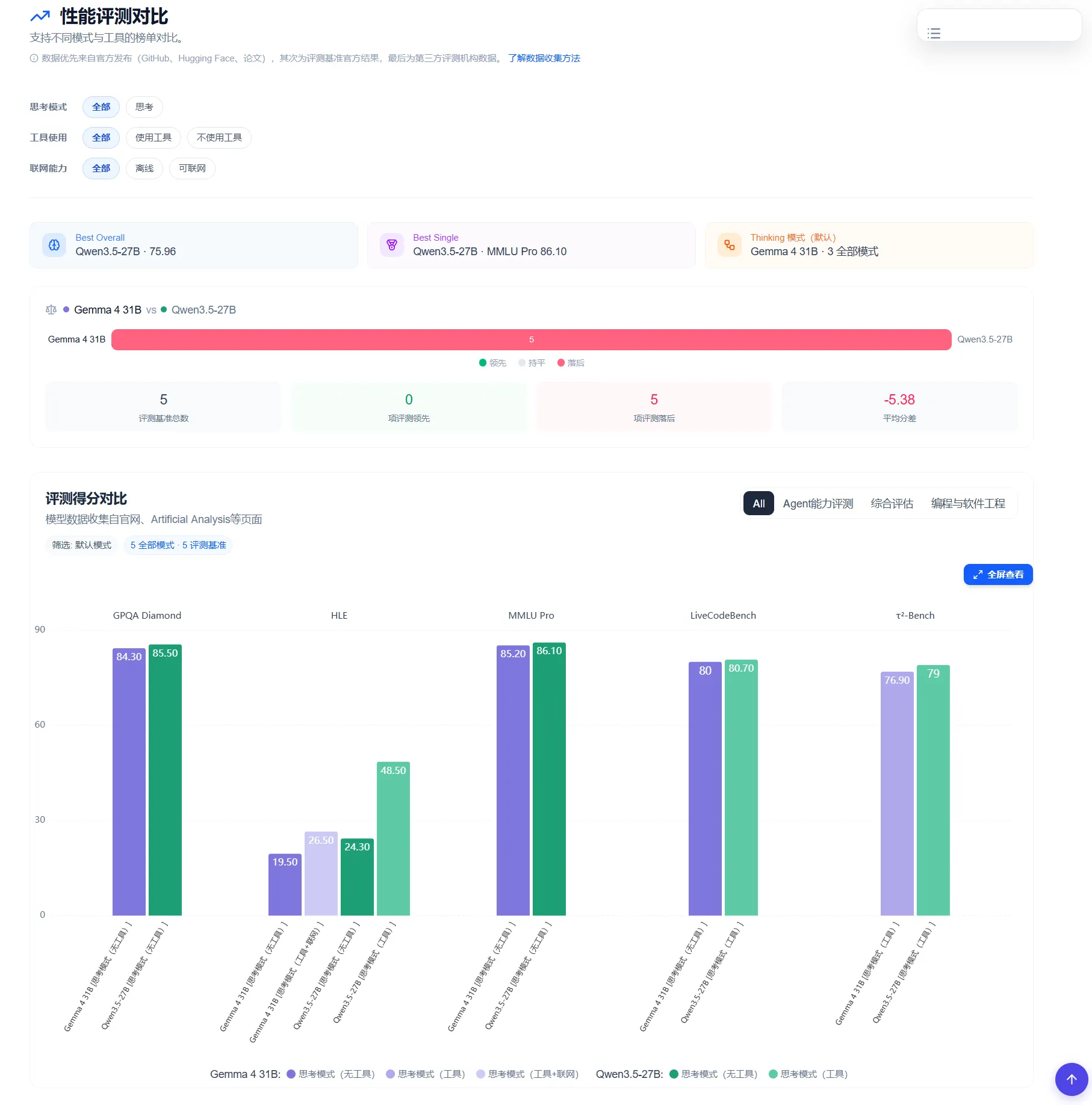
30B 的 Gemma 4 与 27B 的 Qwen3.5 对比:多模态有优势,纯文本综合得分略低 在30B参数量级,目前公认最具代表性的两个开源模型是 Google 的 Gemma 4 31B 和阿里的 Qwen3.5-27B。两者都采用 Apache 2.0 协议、都支持思考模式、都可以免费商用,属于同一赛道的直接竞争对手。同日发布的 Qwen 3.6-Plus 为更大规模的 MoE 模型,不属于同一参数量级,因此这里选择 Qwen3.5-27B 作为同档位对比对象。DataLearner 的横向评测对比页面 汇总了目前可获取的公开 benchmark 数据:
数据来源:https://www.datalearner.com/benchmark-compare/popular-compare/gemma4-31b-vs-qwen3_5-27b
综合知识和科学推理方面,Qwen3.5-27B 略占上风。 MMLU Pro 上 Qwen 得 86.1%,Gemma 得 85.2%;GPQA Diamond(博士级物理、化学、生物推理)上 Qwen 85.5%,Gemma 84.3%。差距不到1.5个百分点,但两个方向一致,Qwen 在综合学科知识上稳定高一点。
编程能力则是典型的各有所长。 LiveCodeBench v6 两者基本持平,Qwen 80.7%、Gemma 80.0%。但如果细分场景,差异就明显了:Codeforces ELO 这个衡量算法竞赛编程的指标上,Gemma 4 31B 得 2150,Qwen3.5-27B 得 1899,相差251分,在这个分段里差距非常显著,Gemma 在竞赛类算法题上明显更强。另一边,SWE-bench Verified 测的是在真实代码库中定位和修复 bug 的能力,Qwen 得 72.4%,Gemma 没有公布对应数据,这个工程实战维度目前无法比较。
在 Agent 任务和工具调用上,Qwen3.5-27B 有优势。 τ²-Bench(多步 Agent 任务执行)Qwen 得 79.0,Gemma 得 76.9。更值得注意的是 HLE(人类最难问题评测):不使用工具的纯推理条件下,Gemma 4 31B 得 26.5%,比 Qwen 的 24.3% 略高;但一旦允许使用工具,Qwen3.5-27B 直接跳到 48.5%,提升幅度远超 Gemma——Gemma 在有工具条件下的 HLE 分数没有公布,但这个反差本身说明了一些问题。
指令遵循和多语言,Qwen 有完整数据,Gemma 没有。 IFEval(指令遵循精确度)Qwen 得 95.0%,接近满分,Gemma 没有发布该项数据。多语言评测上,Qwen 在跨语言 MMMLU 得 85.9%、覆盖29种语言的 MMLU-ProX 得 82.2%,Gemma 虽然声称支持140+种语言,但目前没有任何多语言 benchmark 数据公布,是一个明显的信息空白。
多模态是 Gemma 4 31B 明确的差异化方向。 MMMU Pro 综合多模态理解上 Gemma 得 76.9%,Qwen 没有发布对应分数。更关键的是:Gemma 4 31B 支持最长60秒的视频序列输入,Qwen3.5-27B 不支持视频。如果应用场景涉及视频理解,这是目前这个参数量级里 Gemma 独有的能力。
人类偏好评分上,Gemma 排名更靠前。 Gemma 4 31B 在 LMArena 文本对话榜的预估 ELO 约为 1452,开放模型中排第三。Qwen3.5-27B 没有公布对应的 Arena 排名数据。
总体来看,两者的差距并没有 benchmark 数字有时呈现的那么悬殊。Qwen3.5-27B 在纯文本任务上更全面稳定——综合知识、科学推理、指令遵循、工具调用均有具体数据支撑,而且上下文窗口长达100万 token,是 Gemma 256K 的约四倍。Gemma 4 31B 的优势集中在两个方向:一是多模态(尤其是视频输入),二是竞赛类算法编程,另外在人类偏好评分上表现更好。如果任务场景不涉及视频或算法竞赛题型,从目前公开的数据来看,Qwen3.5-27B 是更保险的选择;反之,Gemma 4 31B 的视频能力和更高的 Arena 分数值得认真考量。
实测表现:Gemma 4 31B略优于Qwen3.5-27B 为了测试2个模型的能力,我们给了2个题目测试验证,这两个题目只是随机找的,可能不能代表全貌,但也算标准评测的补充。
这里我们给了一个算法题:给定一个长度为 n 的整数数组 a,找出所有满足 i < j < k 且 a[i] + a[j] + a[k] 能被给定整数 m 整除的三元组数量。要求时间复杂度优于 O(n³)。约束条件:n ≤ 10⁵,m ≤ 100。这道题的关键在于:n 很大但 m 很小,这两个约束条件的组合直接决定了最优算法的选择方向。
Gemma 4 31B 的解法 抓住了 m ≤ 100 这个关键约束。先统计数组中每个元素对 m 取余的频次分布(长度为 m 的数组),然后枚举所有可能的余数三元组 (r₁, r₂, r₃),检查 (r₁ + r₂ + r₃) mod m 是否为零,再根据三个余数是否相等分三种情况计算组合数。时间复杂度 O(n + m³),在 n = 10⁵、m = 100 的约束下,实际计算量约为 10⁶,毫秒级完成。算法推导完整,分类讨论清晰,代码与数学推导一致。
而Qwen3.5-27B 的解法 采用了双层循环的方案——枚举中间元素 j 和右侧元素 k,通过前缀计数数组在 O(1) 时间内查找满足条件的 i。时间复杂度 O(n²),在 n = 10⁵ 时实际计算量约为 10¹⁰,比 Gemma 的方案慢了四个数量级。此外,Qwen 在回答末尾给出的验证样例自相矛盾——写了一段推导过程但中间步骤对不上最终结果,最后以"实际应为示例调试确认"收尾,等于承认自己没算出来。
虽然,两个模型的解法都不是错的,但 Gemma 4 准确识别并利用了 m ≤ 100 这个约束条件,将问题从"元素索引"维度转移到了"余数分布"维度,实现了降维。Qwen3.5 给出的 O(n²) 方案在 m 很大时反而更优,但在本题给定的约束下,它没有利用 m 很小这个核心信息。Codeforces ELO 相差251分反映的就是这种差距:不是"会不会做"的问题,而是"能不能找到最优解"的问题。
第二个题目是Agent工具规划调用,假设你有以下三个工具可用:
search(query) 搜索网络信息
calculate(expression) 计算数学表达式
translate(text, target_lang) 翻译文本
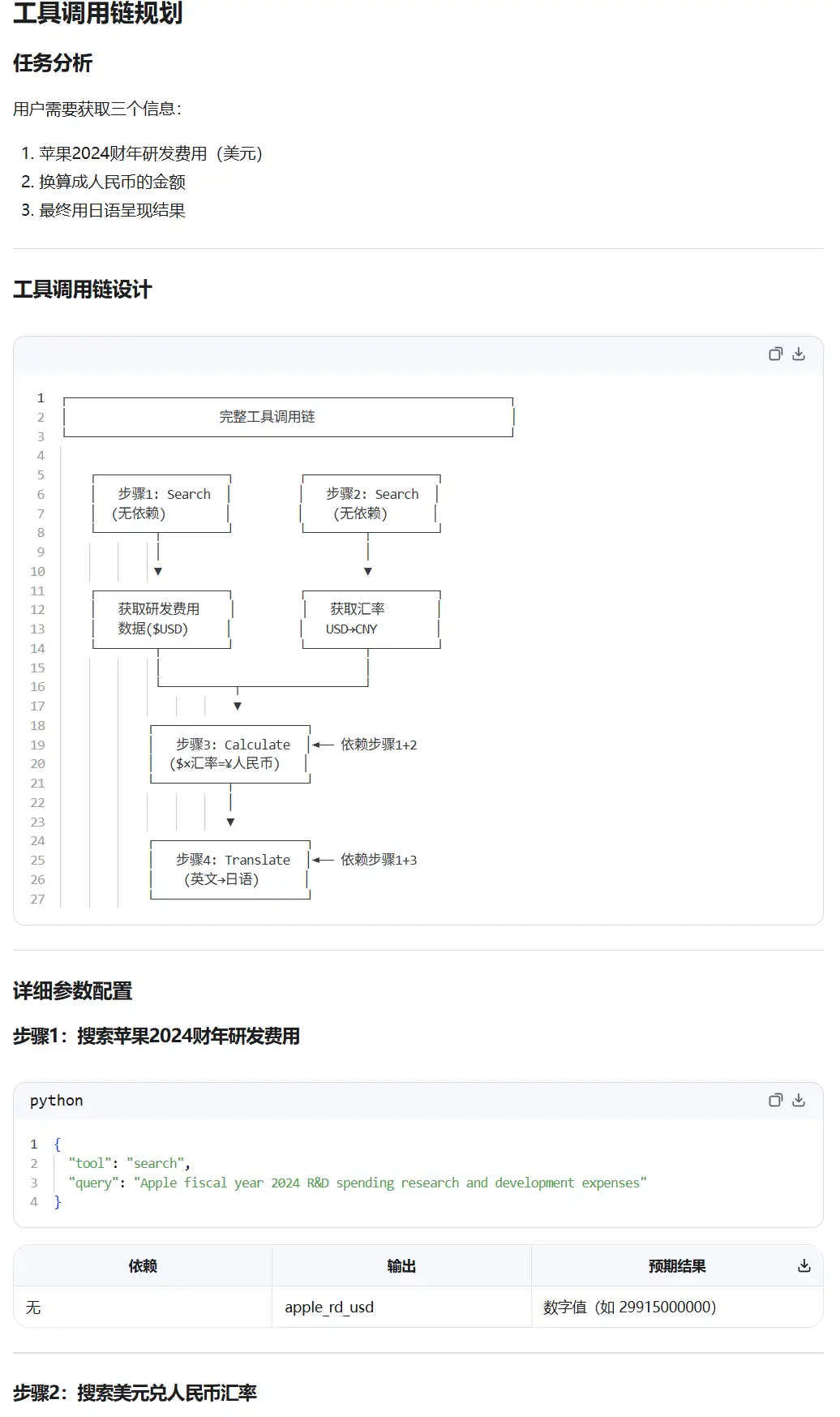
用户问:"苹果公司2024财年的研发费用是多少美元?换算成人民币是多少?用日语回复我。"请规划完整的工具调用链,写出每一步的调用参数和依赖关系。
Qwen3.5-27B模型的Agent调用结果
Gemma 4 31B的Agent调用结果
结果看,这道题两个模型的核心逻辑完全一致:搜索研发费用、搜索汇率、计算、翻译,依赖关系也都对了(步骤1和2可并行,步骤3依赖1+2,步骤4依赖1+3)。所以在"规划能力"这个维度上,两者打平,没有实质差异 。
但呈现方式的差异很大,而且恰好反映了两个模型不同的风格倾向:Gemma 4 更简洁精准。 四步写完,每步的调用参数、依赖关系、预期输出一目了然,最后用一个三行的流程图收尾。作为一个 Agent 调用规划,这个信息密度是够的,不多不少。Qwen 工程化考虑更多 , 同样的四步逻辑,它用了 ASCII 流程图、参数配置表、执行顺序表、伪代码实现、注意事项五个板块来呈现,信息量比较多。实际使用中优点是考虑周全,缺点可能是耗费tokens多。
不过有一个细节 Qwen 可能做得更好:它的搜索 query 用了英文("Apple fiscal year 2024 R&D spending"),而 Gemma 用了中文("苹果公司 2024财年 研发费用 USD")。搜索苹果财报数据,英文 query 更可能命中 SEC filing 原始数据源,中文 query 大概率只能搜到二手报道。这是一个小但实际有意义的差异。
Gemma4的许可证有较大变化,完全开源了 Gemma 4 另一个很重要的是许可证的切换。此前Google的gemma系列的开源协议是自定义开源协议,虽然也是免费,但包含各种使用限制和随时可能修改的条款,把很多团队推向了 Mistral 或阿里的 Qwen。法律审查带来的摩擦、合规团队标记的边缘情形,让"开放但有星号"的 Gemma 3 无法真正进入生产环境。
Gemma 4 彻底消除了这种摩擦。Apache 2.0 协议与 Qwen、Mistral 以及大多数开放权重生态系统使用的条款完全一致,没有自定义条款,没有需要法律解读的"有害使用"排除条款,没有对再分发或商业部署的限制。
发布24小时后:多语言获好评,推理速度被集中吐槽,124B 大模型去哪了 Google发布Gemma4之后,社区做了很多评测,我们总结主要情况如下:
最受认可的是许可证和多语言能力。 Apache 2.0 被普遍认为是这次发布中比 benchmark 数字更重要的变化。测试德语、阿拉伯语、越南语和法语的用户报告称 Gemma 4 在非英语任务上超越了 Qwen 3.5,有人称其在翻译方面是"独占一档"。Hugging Face 团队给出了高度评价。 他们表示在预发布版本测试中印象深刻,甚至因为模型开箱即用的质量太高,难以找到足够有代表性的微调示例 但速度问题成为发布后最集中的抱怨。 26B MoE 模型本应是效率优先的选择,但社区测试显示其实际推理速度只有约11 tokens/秒,而 Qwen 3.5 在同等 GPU 上能达到60 tokens/秒以上。这对于生产场景来说差距过于明显。产品线的空白也引发了讨论,尤其是那个消失的124B模型。 发布当天,Google 的 Jeff Dean 在 X 上发的推文里写道 Gemma 4 的规模覆盖从边缘端"up to a 124B parameter MoE model"——但这句话不久后就从推文中悄悄删除了。社区很快注意到这个细节,结合发布前 Arena 上曾出现过一个叫"significant-otter"的匿名模型(自称是 Gemma 4,当时曝光的产品线包含一个 120B-A15B 的 MoE 版本),外界普遍认为更大规模的 Gemma 4 确实存在,只是没有随四款模型一起发布。有猜测认为这个模型在某些 benchmark 上的表现已经超越了 Gemini 3 Flash-Lite,Google 因此暂时搁置了发布。E4B 和 26B MoE 之间缺少一个12B左右的中间档位,也是另一个被反复提到的遗憾——Gemma 3 12B 在社区里颇受欢迎,但 Gemma 4 没有直接对应的升级版本。**整体判断倾向于"值得关注,但还不够成熟"。**从务实角度来看:对于纯英文、速度敏感型场景,Qwen 3.5 目前仍是更优选择;对于多语言、有商业合规需求、以微调为主要使用方式的场景,Gemma 4 有相当有力的理由。速度和工具链的问题还需要几周时间沉淀,等量化感知训练(QAT)版本出来后,小规模模型的效率表现也会有明显改善。
Gemma4发布总结 把时间线拉长来看,这次发布的意义或许不只在于 Gemma 4 本身的性能。一个真正以 Apache 2.0 开放的、覆盖从手机到高性能 GPU 全场景的 Google 模型系列,改变的是开发者的选项格局——至少在许可证层面,Google 终于和开源社区站在了同一边。而那个还没有出现的124B大模型,如果确实存在且性能超过 Gemini 3 Flash-Lite,它将直接改变开源模型与闭源模型的竞争格局。
关于Gemma 4系列模型的开源地址、在线体验、详细评测请参考DataLearnerAI大模型信息卡:
谷歌发布视频大模型Veo 3.1:电影级别的视频生成,声音合成和同步能力大幅提升,但相比较Sora2依然有明显差距!