2026年5月份最新AI Agent系统设计与技术进展研究报告
最新 AI Agent 系统设计与技术进展研究报告
本报告来自ChatGPT的DeepResearch整理,仅供参考。
执行摘要
AI Agent 在 2024–2026 年间出现了一个非常清晰的范式收敛:从“带工具调用的聊天模型”演进为“带会话、工具、记忆、审批、安全边界和评测闭环的运行时系统”。Anthropic 将这一差别明确区分为 workflow 与 agent:前者的控制流由代码预先定义,后者则允许模型动态决定下一步、选择工具并调整路径;OpenAI 则把 agent 定义为能够规划、调用工具、在专家之间协作并保持足够状态以完成多步工作的应用。这个定义收敛,基本解释了为什么近两年的工程重点已经从 prompt 本身转向“运行时+评测+安全”三个层面。
从架构上看,最值得关注的不是“更大的单体 agent”,而是模块化运行时的兴起。Anthropic 的 Managed Agents 将 session、harness、sandbox 解耦;LangGraph 强调 durable execution、human-in-the-loop 和 persistence;Google 的 Agent Platform/ADK 与 Microsoft Agent Framework 都在把 agent 开发抽象成更接近传统软件工程的有状态编排运行时。换言之,AI Agent 的主战场已经从“单次推理质量”转向“长时执行可靠性、可恢复性、可观测性与安全边界”。
从算法上看,2023 年奠定了 ReAct、Toolformer、Self-Refine、Tree of Thoughts、Voyager 等基础;而 2024–2026 年的真正推进来自多轮交互训练与测试时计算扩展:WebRL 将在线 RL 引入网页 agent,KALM 和离线 RL 工作尝试从 rollout 中蒸馏策略,STEP-HRL 与 HiPER 等工作把层级强化学习重新带回 agent 训练,近年的多智能体 debate 则在“更大测试时计算预算”这一方向上持续探索。
评测体系也在快速成熟。过去常见的“只看最终回答是否正确”已经明显不够:Google Vertex AI 已把 trajectory evaluation 作为一等公民,支持 exact/in-order/any-order、precision、recall、single-tool-use、latency、failure 等指标;Anthropic 在多智能体研究系统里强调 end-state、LLM-as-a-judge 与小样本快速迭代;而 GAIA、WebArena、VisualWebArena、OSWorld、τ-bench、BFCL、AgentDojo、Online-Mind2Web、Mind2Web 2、SWE-bench Verified 等基准,已经把 agent 的能力拆解到真实网页、GUI、工具调用、软件工程、策略遵循与安全鲁棒性等维度。
就产业落地而言,编码代理与研究代理目前最先形成高价值闭环。原因并不神秘:软件工程环境更容易提供可验证反馈,研究任务则天然适合并行搜索。Anthropic 的公开工程总结表明,多智能体研究系统在并行广度查询上显著优于单 agent,但代价是 token 开销成倍上升;OpenAI、Anthropic、Google、AWS、Salesforce 则分别在编码、企业流程、客户服务、法律、基础设施优化等场景把 agent 推到了产品级。
最重要的判断是:未来 2–5 年,真正决定 agent 成败的,不会是单一“最强模型”,而是五件事的组合能力——稳定的工具接口、可恢复的有状态运行时、以 end-state/trajectory 为核心的评测闭环、强制审批与最小权限安全边界,以及能把高成本自治限定在高价值任务上的经济学设计。公开资料已经相当一致地指向这一结论。
概念、定义与分类
Anthropic 在其“Building effective agents”中提出了一个非常实用的工程定义:workflow 是模型和工具被预先编排在固定代码路径中的系统;agent 则是模型能够动态决定过程、使用工具并控制完成方式的系统。OpenAI 的 Agents SDK 文档进一步把 agent 概括为:能够规划、调用工具、在专家之间协作,并保留足够状态以完成多步工作。近年的综述则把 tool use、planning、feedback learning、memory、multi-agent organization 视为统一 taxonomy 的核心维度。
据此,当前 AI Agent 可以从四个轴来分类。第一是控制自主性:从严格受控工作流,到单智能体自治,再到多智能体协同。第二是环境耦合方式:从文本推理,到 API/tool agents,再到网页/桌面/移动端 computer-use agents。第三是运行时归属:本地执行、自托管、托管云运行时,以及本地—云混合。第四是状态机制:无状态单轮、带会话历史、多层记忆(工作记忆、长期记忆、外部状态库)以及显式 artifact/file-based state。这个分类已经能较好覆盖 OpenAI、Anthropic、Google、AWS、Microsoft 与主流开源框架的公开设计。
一个更细的实践分类是按任务性质划分。研究/搜索型 agent 倾向于 breadth-first 并行探索与证据压缩;交易/流程型 agent 强依赖 API 正确性、策略遵循和 end-state;编码 agent 具有最强的自动验证潜力,因为测试、编译、lint 和 diff 本身就是天然 reward signal;computer-use agent 则最困难,因为它们同时面临 GUI grounding、操作知识、视觉理解与环境不稳定。GAIA、OSWorld 与 Online-Mind2Web 的结果共同说明:通用 agent 在真实环境中的能力仍远低于人类,尤其是在开放网页和操作系统场景。
下表给出一个工程上最有用的架构模式归纳。它不是官方单一定义,而是根据公开论文、产品文档和框架能力做的综合抽象。
架构模式摘要
架构模式与核心组件
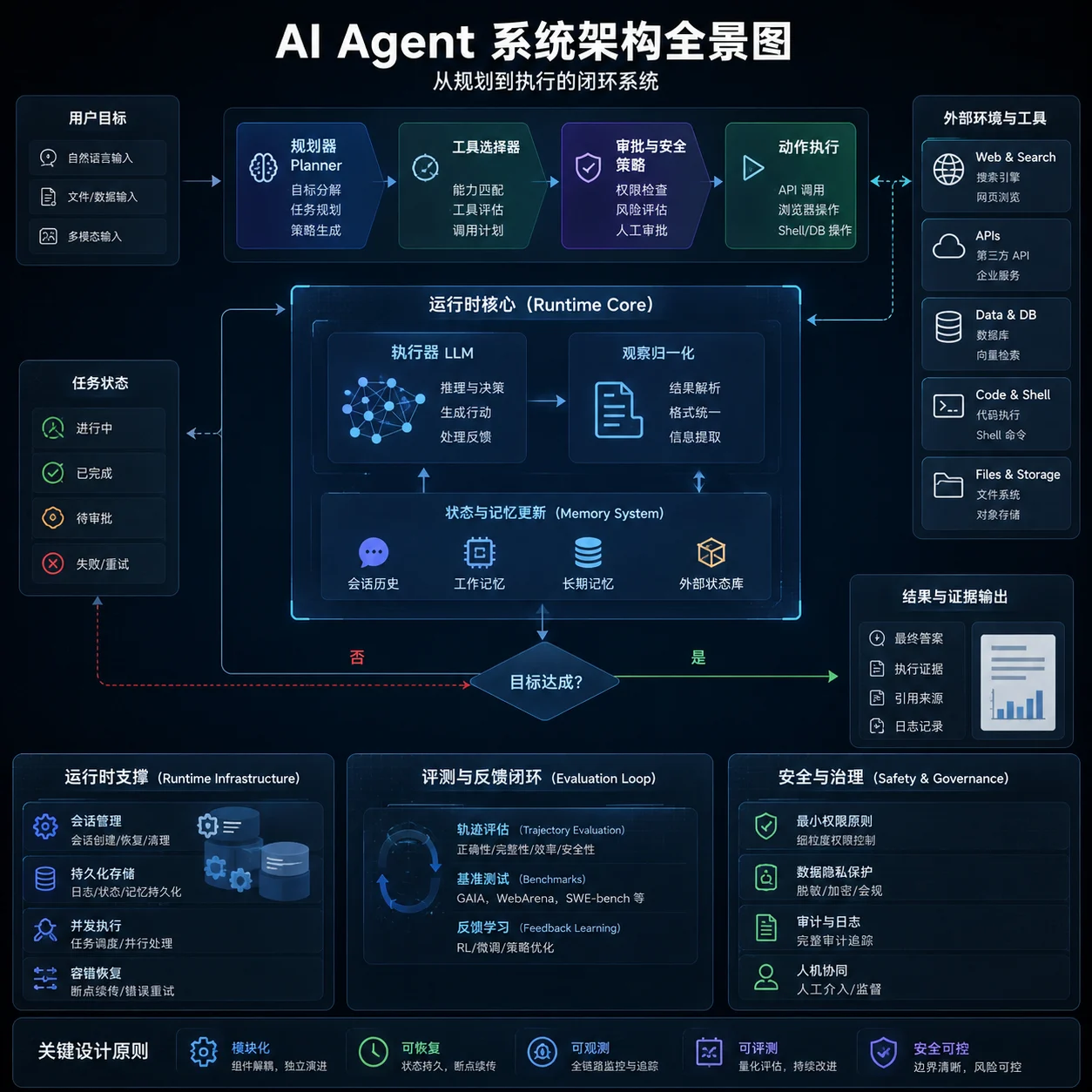
Anthropic、Microsoft、Google 与 LangChain 近两年的公开设计有一个共同趋势:把“模型”从“运行时”中分离出来。Anthropic Managed Agents 通过 session、harness、sandbox 的三分结构,把“脑”(模型与 harness)与“手”(沙箱、MCP 工具)解耦,并把会话日志外置为可恢复状态;Microsoft Agent Framework 把 Agent、Tool、Session、Telemetry 抽象成 typed primitives;LangGraph 则把 durable execution、persistence、human-in-the-loop 置于核心;Google ADK/Agent Platform 也在将 agent 开发软件工程化。换句话说,最新主流系统不再把 agent 视为一个 prompt,而将其视为有状态、可编排、可恢复的软件系统。
上图概括的是近两年最常见的 planner–executor 结构:规划、工具选择、动作执行、观察归一化、状态更新和安全审批分层存在。它的公开代表包括 Magentic-One 的 Orchestrator-worker 结构、Anthropic Research 的 lead agent + subagents,以及 Thomson Reuters 下一代 CoCounsel Legal 所采用的 “plan / select tools / retrieve authoritative content / adapt mid-workflow” 模式。
LLM 骨干与后训练
Agent 的核心“脑”仍是基础模型,但 2025–2026 的产品文档越来越少把“换更强模型”当成唯一解,而是强调 context engineering + eval + targeted post-training。OpenAI 在 Responses/Agents/RFT 文档中把 agent 设计、评测和 reinforcement fine-tuning 明确连接起来;Anthropic 的 context engineering/managed agents 工程文章则反复强调 harness 假设会随着模型进步而“过时”,因此系统必须允许上下文压缩、重取、切分与恢复策略动态演化。
在实践上,近两年的最佳经验不是“先 fine-tune”,而通常是:先用 prompt/context/tooling 把系统做成可测形态,再用 SFT、DPO 或 RFT 去优化局部子策略,比如工具选择格式、任务分解质量、代码修复策略或策略遵循行为。DPO 给出了比传统 RLHF 更轻量的偏好优化路径;OpenAI 的 RFT 则把 programmable grader 直接引入训练。
检索增强、工具 API 与 grounding
RAG 仍然重要,但最新 agent 系统已经从“静态检索后生成”转向“动态检索—工具调用—证据回流—再规划”的多步 grounded loop。Anthropic 在多智能体研究系统文中明确对比了传统静态 RAG 与其动态多步搜索架构;OpenAI 的 Responses API 把 web search、file search、computer use 等 agentic primitive 前置;Google 与 Anthropic 分别推动了 A2A 与 MCP,说明“工具与上下文互操作”已成为生态层的主线。
MCP 的重要性在于,它把“模型访问外部能力”的接口标准化;A2A 的重要性则在于,它试图把“agent 与 agent 的协作”标准化。Google 文档已经把 A2A 作为多智能体系统的推荐参考,并提到该协议于 2025 年 6 月捐赠给 Linux Foundation;Anthropic 和 OpenAI 的产品也都在不同层面接入 MCP。未来 agent 生态的互操作,很大概率会沿着 “MCP 管工具,A2A 管协作” 的方向演进。这个判断是基于当前官方文档的工程推断,而不是既成行业标准。
行动空间、观测处理与状态存储
当前主流 agent 的行动空间至少包括四类:结构化 API 调用、代码/文件编辑、浏览器/GUI 操作,以及跨系统消息/任务动作。相应地,观测也不再只是文本:WebArena 和 VisualWebArena 把网页导航与视觉信息引入评测;OSWorld 则把真实操作系统中的 GUI、文件 I/O、跨应用工作流纳入环境;Codex 与 Claude Code 系列产品则进一步把本地终端、浏览器、图像输入、工作区文件树、Git 状态和插件/MCP 工具都当作可观察世界的一部分。
在状态/记忆方面,近年的收敛非常明显:短期上下文不足以支持长程任务,因此需要外部状态对象或记忆库。Anthropic Managed Agents 明确把 session 视为“不是 Claude 上下文窗口本身,而是窗口外可重取的 durable log”;Claude Code 提供 CLAUDE.md 作为持续项目记忆;LangGraph 提供 persistence 与 comprehensive memory;Google 在 Gemini/Vertex 侧提供 context cache 与 Memory Bank。工程上,好的 agent 往往不是“记住所有内容”,而是把高价值状态以可检索对象形式显式保存。
安全模块与人类在环
到 2026 年,审批与沙箱已不再是“补丁”,而是 agent 设计的内建层。OpenAI 把 approvals 定义为 tool call 级的人类复核路径;Codex 用 sandbox 作为本地动作边界,并在 Windows 上专门公开了其安全沙箱设计;Anthropic 在 Managed Agents 中把凭据移出沙箱,改由 vault/proxy 模式处理;Haystack 也把 human-in-the-loop 设计成可以拦截、修改或拒绝工具参数的原语。对高风险任务来说,最小权限、默认拒绝、显式审批正在变成主流设计前提。
算法进展
如果把 2023–2026 的 agent 算法进展抽成一条主线,那么它大致是:从提示式推理,走向交互式规划;从单次输出优化,走向多轮轨迹优化;从单 agent 推理,走向多 agent 测试时计算扩展。 CoT 证明了中间推理步骤能显著提升复杂推理;ReAct 把 reasoning 与 acting 交错起来;Toolformer 让模型学会何时调用工具;Tree of Thoughts 让搜索显式化;Self-Refine 让测试时自我反馈成为独立范式;Voyager 则把自动课程、技能库和长期累积带入 embodied/lifelong setting。今天大家熟知的 planner、reflection、skill library、tool loop,本质上都能追溯到这一时期。
接下来一轮推进来自偏好优化与强化学习。RLHF 与 InstructGPT 证明了“对齐用户偏好”对泛化帮助很大;DPO 以更轻量的目标函数替代传统 reward model + PPO;OpenAI 的 RFT 则把“可编程评分器”直接用于 reasoning model 的任务定制。对 agent 而言,这意味着训练目标不再必须是“正确答案文本”,而可以是“正确动作、正确轨迹、正确 end-state 或正确多轮行为”。这正是 agent learning 与普通 chat tuning 的关键差别。
2024 年之后,网页与多轮交互训练成为新热点。WebRL 将自演化课程、结果监督 reward model 和自适应 online RL 引入网页 agent 训练,在 WebArena-Lite 上让开源小模型大幅追近甚至超过当时的闭源基线;KALM 则尝试把 LLM imaginary rollouts 变成离线 RL 可学习的知识;ACL 2025 的“Offline RL for LLM Multi-step Reasoning”与 2025 年底的 on-policy expert corrections 进一步表明:单纯依赖静态 expert trajectories 的模仿学习,容易在多轮环境中因 covariate shift 失效。
另一个强趋势是层级化与多智能体化。STEP-HRL 通过子任务级全局进度与局部进度摘要来实现 step-level agent RL;HiPER 则显式拆分 high-level planning 与 low-level execution;而多智能体 debate 的最新工作——例如针对 MAD 的系统化框架 MALLM,以及 2026 年的 Self-Debate Reinforcement Learning——都在探索如何让模型在测试时或训练时从不同推理轨迹中受益。值得强调的是,这一方向还远未收敛:它在高难推理任务上具有潜力,但在真实 long-horizon production agent 里,token 成本、协调不稳定与评测困难仍是硬约束。
这条时间轴概括了过去三年的主要脉络:2023 年是基础认知与工具调用范式确立;2024 年是 benchmark 与 engineering pattern 爆发;2025–2026 年则是“产业级运行时 + 更真实 benchmark + 多轮训练/评测”并进。对应来源包括 CoT、ReAct、Toolformer、Voyager、GAIA、WebArena、VisualWebArena、OSWorld、BFCL、τ-bench、Magentic-One、Online-Mind2Web、Mind2Web 2、A2A、Codex、AlphaEvolve、Anthropic Research/Managed Agents,以及 STEP-HRL/SDRL 等。
系统工程与评测
在系统工程层面,最关键的变化是:长时任务的可恢复执行 已从“可选增强”变成“基础要求”。Anthropic Managed Agents 通过把 session 外置到 durable log,实现 harness 崩溃后 wake(sessionId) 式恢复;LangGraph 把 durable execution 作为核心能力;OpenAI 提供 background mode 来支撑长时 reasoning/agent 任务;Microsoft Agent Framework 和 Google Agent Platform 也都在以会话、持久状态、编排与 telemetry 为核心设计。内部工程数据虽然属于厂商自报,但方向非常一致:如果没有可恢复运行时,生产级 agent 很难成立。
性能工程也正在从“平均响应时延”转向对 TTFT、总任务时长、工具并行度、失败恢复率 的综合优化。Anthropic 报告称,在其 brain–hands 解耦架构中,p50 TTFT 约下降 60%,p95 下降超过 90%;同一篇文章也说明,按需调用容器而不是为每个会话预先 provisioning 全套环境,是降低用户体感时延的关键。另一方面,Anthropic 的多智能体研究系统又指出,多智能体在复杂 research query 上可把时间降到原来的一个很小分数,但 token 开销会明显上升。这组事实合在一起说明:Agent 的性能优化不是单一目标,而是 latency、parallelism、token economics 与可靠性的多目标平衡。
可观测性与测试正快速走向“一等公民”。OpenAI Agents SDK 默认 tracing,记录 LLM generations、tool calls、handoffs、guardrails 和 custom events;CrewAI 与 LangGraph/LangSmith 也分别将 tracing/observability 与 eval 集成到平台中;Anthropic 的公开工程经验则强调,小样本 eval 应该尽早建立,因为 agent 改动往往会带来很大的行为跃迁,早期 20 个真实查询就足以看出显著变化。对于生产环境,full tracing、decision-pattern monitoring、rainbow deployment 已经是比传统 LLM app 更接近复杂分布式系统的做法。
在评测方面,最新共识是“三层并行”:final response、trajectory、end-state。Google Vertex AI 已将 trajectory evaluation 工具化,提供 exact match、in-order match、any-order match、precision、recall、single-tool-use,并默认加上 latency 与 failure;Anthropic 针对会修改外部状态的 agent 强调 end-state evaluation,认为不应对所有中间步骤做僵硬规定;Online-Mind2Web 则表明在真实 open web 上,现有 agent 的能力被许多沙箱 benchmark 高估了,同时其 LLM-as-a-judge 与人工评判约有较高一致性。
基准比较
对于人类评测协议,Anthropic 与 Mind2Web 2 的经验很有代表性:人工评测不应被自动评测替代,但应被用于校准自动评测。 Anthropic 在 research 系统中使用单次 LLM-judge 打分并比较其与人类一致性,同时保留人工测试来发现偏源、幻觉和异常失败;Mind2Web 2 则用 Agent-as-a-Judge 解决真实网页与长答案组织的自动评分问题。高质量评测不再是“人工或自动二选一”,而是 rubric 明确的人类—自动双层体系。
开源与商业系统比较
先说明两个假设。其一,“Hermes”在公开资料中存在同名项目;本报告按 Nous Research 的 Hermes Agent 处理,因为它是最符合“近期 AI Agent 产品/系统”语境、且有明确官方仓库和产品描述的项目。其二,商业产品的“许可证”通常并不以开源许可证形式公开,因此表中对商业系统统一标为“商用产品/公开源码许可证未披露”;这并不等价于法律意义上的完整许可审查。
系统比较总表
从这张表可以看到两个重要趋势。第一,产品与框架正在分层:Codex、Claude Code 这样的“终端/桌面级产品”更贴近开发者日常,而 LangGraph、ADK、Agent Framework、Bedrock AgentCore 则更像“agent runtime/平台层”;二者是互补而不是互斥。第二,开源系统越来越强调自托管与模型无关性,商业系统则更强调治理、审批、会话、长期执行和企业集成。这个分化与传统云原生生态很像:开源负责可塑性,云平台负责运营复杂度。
同时也要看到,这些系统并不都在解决同一个问题。Claude Code、Codex、OpenHands面向的是软件工程自治;Claude Managed Agents、Agent Platform、Bedrock AgentCore 面向的是运行时和企业编排;Hermes、OpenClaw 更接近个人代理/持续陪伴型 agent;smolagents 和 CrewAI 则偏研究和应用搭建框架。如果不区分这一点,系统比较很容易失真。
行业落地、安全治理与未来路线图
从公开案例看,AI Agent 的最成熟落地方向已经非常清楚:软件工程、客服/支持、法律检索与文书、企业知识流程、科学发现/基础设施优化、以及部分高自主度机器人/航天任务。但不同场景的证据质量并不相同:NASA/JPL 与学术 benchmark 通常可信度更高;厂商 customer stories 与内部 eval 则更适合用来理解 ROI 轮廓,而不宜直接当作可横向比较的科学证据。
案例研究
安全、对齐与治理
安全上,OWASP 对 LLM/GenAI 应用的 Top 10 已经较系统地概括了当前 agent 面临的主要风险:prompt injection、insecure output handling、training data poisoning、model DoS、supply chain vulnerabilities 等。对 agent 来说,这些问题会比普通 chat app 更严重,因为 agent 不只是“说”,还会“做”,并且往往拥有外部系统权限。
工程上的一线防御已经比较明确。第一层是权限最小化:Anthropic Managed Agents 把凭据移出沙箱,OpenAI 用 sandbox 和 approvals 缩小动作面,OpenClaw 默认对陌生私信走 pairing/allowlist。第二层是人类在环:OpenAI、Haystack、LangGraph 都把审批中断设计成框架原语。第三层是轨迹级观测与审计:因为 agent 的关键风险不只在输出文本,更在完整轨迹、工具参数、隐式重试与上下文漂移。
治理上,企业与前沿实验室正在形成两条并行路径。对企业应用,NIST 的 Generative AI Profile 提供了风险管理框架;对 frontier model 与更高危能力,OpenAI 的 Preparedness Framework 与 Anthropic 的 Responsible Scaling Policy 提供了公司级自我治理框架。需要注意的是,这些框架主要面向严重危害与前沿能力治理,并不自动等价于每个企业 agent 应用的完整合规方案;在落地层面,组织仍需额外建设权限模型、日志留存、审批制度、供应链审计和 red-teaming。
开放挑战
当前最核心的技术挑战仍然是真实环境中的长时可靠性。OSWorld 显示最优模型与人类之间仍有巨大差距;Online-Mind2Web 则提醒我们,不少网页 agent 成绩受限于 benchmark 设计与环境静态性,现实能力要弱得多。对 computer-use agent 而言,GUI grounding、弱观察、环境变动与异常处理仍是主瓶颈。
第二个挑战是多智能体的经济性与协调复杂度。Anthropic 的公开经验表明,多智能体对 breadth-first 研究任务非常有效,但 token 成本可远高于单次聊天,而且对于共享上下文密集、强同步依赖高的任务并不一定划算;Microsoft 关于 tool-space interference 的讨论则进一步提示:多加工具、多加 agent 并不天然提升效果,反而可能因描述冲突与选择负担导致性能下滑。
第三个挑战是评测与复现。真实 agent 的合理轨迹常常不唯一,这使得“预设唯一正确路径”的评测天然偏窄;同时 live web/live systems 又会导致结果时变和复现困难。Google 的 trajectory metrics、Anthropic 的 end-state/LLM-as-judge、Mind2Web 2 的 Agent-as-a-Judge,实际上都在试图回答同一个问题:如何给非确定性、多路径、可操作外部状态的系统建立可靠质量门槛。这个问题到 2026 年仍远未彻底解决。
未来两到五年的研究与工程路线图
如果把未来两到五年的重点压缩成最有价值的路线图,我会把它分成“必须优先工程化”和“值得重点研究”两层。
优先路线图
进一步收敛成一组可执行的优先事项,最值得先做的五件事是:先建评测再扩权限;先做模块化 planner–executor 再做多智能体;先把高风险工具纳入审批与最小权限,再谈自治;优先选择可以程序验证的场景获取 RL/RFT 信号;只有在任务天然可并行、单 agent 明显受上下文限制时,才引入多智能体编排。公开工程经验基本都支持这一排序。
推荐阅读
下面这组阅读材料最值得作为后续系统化深入的起点:
- Anthropic《Building effective agents》:workflow 与 agent 的工程分界,适合做总纲。
- Anthropic《How we built our multi-agent research system》:研究型 multi-agent 的最佳公开工程复盘之一。
- Anthropic《Scaling Managed Agents: Decoupling the brain from the hands》:长时运行时设计的高质量一手资料。
- OpenAI《A practical guide to building agents》与 Agents/Responses/RFT 文档:构建、评测、训练三位一体。
- Magentic-One 技术报告:多智能体通用系统的代表性开放方案。
- WebArena、VisualWebArena、OSWorld:网页与 computer-use agent 的关键 benchmark 链。
- Online-Mind2Web 与 Mind2Web 2:理解“真实开放网页上 agent 其实还有多弱”的最好入口。
- BFCL、τ-bench、AgentDojo:工具调用、策略遵循与安全评测的三类代表。
- WebRL、STEP-HRL、SDRL:理解 2024–2026 agent learning 新趋势的代表工作。
- NIST GenAI Profile、OWASP Top 10 for LLM Applications、OpenAI Preparedness、Anthropic RSP:安全治理的最小公共语境。
开放问题与限制
本报告优先采用 2024–2026 的论文、官方文档与工程博客,并补充 2023 年奠基性工作;因此某些 2022–2023 文献只作方法学背景使用。对于商业产品,很多“成熟度”“效果提升”“客户收益”来自供应商官方案例或内部评测,应理解为厂商自报证据,不宜与学术 benchmark 结果直接横向比较。尤其是 Anthropic Research 的内部 90.2% 提升、Managed Agents 的 TTFT 改善、以及 AlphaEvolve 的基础设施收益,都属于强参考价值但非独立复现证据。
“Hermes”在公开资料中存在同名项目;本报告按 Nous Research 的 Hermes Agent 处理。部分商业系统的完整源码许可未在公开文档中披露,表中因此标注为“商用产品/未公开/需确认”。此外,benchmark 与产品能力都处在快速变化之中,尤其是 Codex、Claude Code、Agent Platform 与公开 leaderboard 的细节,可能在未来数周内继续变化。
如需追踪最近几周的产品与治理动态,可参考下列报道。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
