重磅!ChatGPT加入多模态能力,可以听语音、生成语音并理解图片了!
几分钟之前,OpenAI宣布ChatGPT支持多模态,目前已经支持语音的输入、语音的输出、理解图片的输入!不过目前似乎仅限于客户端~官方说的是未来2周内企业和Plus用户可以使用,后面会普及到其它用户!

多模态版本背后的ChatGPT模型是GPT-4V,请参考DataLearner模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/GPT-4V
ChatGPT多模态能力简介
为了不断提升用户体验并提供更多多功能性,ChatGPT 推出了令人激动的新功能:声音和图像功能。这些功能使对话更加直观,并扩大了 ChatGPT 可以协助的任务范围。
与 ChatGPT 进行声音对话
ChatGPT 中最令人期待的功能之一是能够进行声音对话的能力。这种功能允许用户与人工智能助手进行互动式的、来回交流的讨论。
要开始使用声音功能,只需在移动应用程序上导航到“设置”→“新功能”并选择加入声音对话。然后,在主屏幕右上角点击耳机图标,选择五种可用选项中的首选声音。
这个功能背后是由一种新的文本到语音模型驱动的,它能够从文本和短暂的语音样本中生成极为逼真的音频。每个声音都是与专业声音演员合作精心打造的,确保了丰富而自然的对话体验。此外,OpenAI 还使用了 Whisper,他们的开源语音识别系统,以准确地将口语话语转录成文本。
下图是一个界面:

关于图像进行对话
另一个突破性的新增功能是与 ChatGPT 分享图像的能力,这使您能够与您的人工智能助手讨论和分析视觉内容。这一功能打开了无限可能性,从排除烧烤问题,到通过检查冰箱内的食材来计划餐点,再到分析工作相关数据图表。
要开始使用这一功能,请点击照片按钮来捕捉或选择图像。如果您使用 iOS 或 Android 平台,首先点击加号按钮。您甚至可以讨论多个图像,并在移动应用程序中使用绘图工具来引导对图像中的特定细节的讨论。
这一图像理解功能得以实现,得益于强大的多模式 GPT-3.5 和 GPT-4 模型。这些模型利用其语言推理技能来分析各种类型的图像,包括照片、屏幕截图以及包含文本和图像的文件。
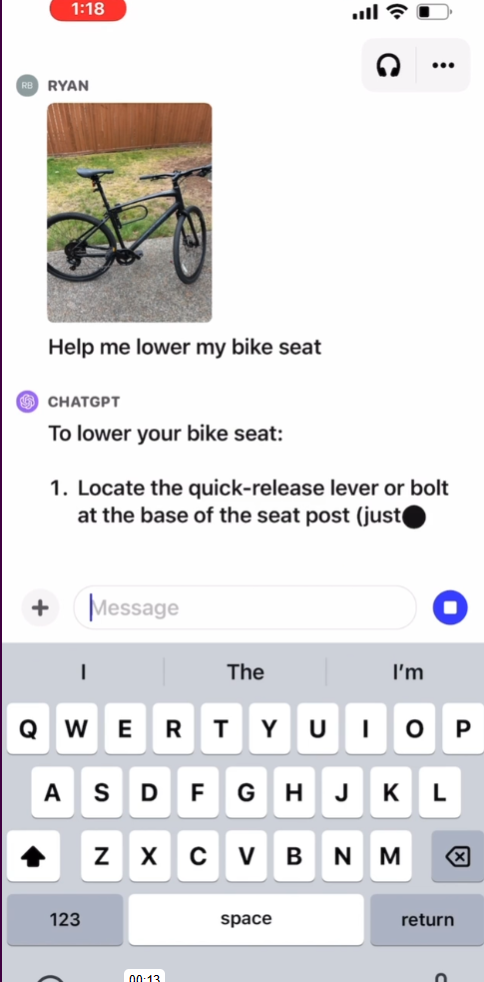
可以看到,这里的图片理解不单纯是一个图像识别或者图像分割,而是结合问题来解决问题,上图的案例就是chatgpt如何调整自行车座椅~
渐进式部署以确保安全性和响应性
目前多模态能力没有完全开放!声音技术虽然带来了令人兴奋的可能性,但也带来了新的风险,例如潜在的滥用或冒充。为了减轻这些风险,OpenAI 将声音功能的使用重点放在特定应用上,比如声音聊天,并与各行各业的专业人士密切合作,如 Spotify 的“声音翻译”功能。
这意味着短期看不会完全普及这个能力!
同样,基于视觉的模型引入了独特的挑战,包括在高风险领域中可能的误解。在更广泛的部署之前,经过与红队测试人员的风险评估和来自 alpha 测试人员的反馈,已经帮助制定了安全措施。
关于在线的演示结果大家可以参考官方博客:https://openai.com/blog/chatgpt-can-now-see-hear-and-speak
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
