阿里通义千问团队首次开源语音合成大模型:Qwen3-TTS:总共5个模型,最小的仅0.6B参数规模,最大1.8B参数
就在刚刚,阿里开源了全新的语音合成大模型Qwen3-TTS系列!本次开源的语音合成模型共5个版本,最小的仅0.6B参数规模,最大的模型参数也就1.7B,基本上手机端都可以运行。此次发布不仅在性能上宣称超越了许多商业级闭源模型(如 OpenAI 的 GPT-4o-Audio 和 ElevenLabs),更重要的这应该是阿里通义千问团队首次开源语音合成系列大模型。
本次发布的 Qwen3-TTS 主要包含两个核心能力方向:语音设计(Voice Design) 和 语音克隆(Voice Cloning),旨在解决传统 TTS 模型在情感表达、个性化定制和多语言适应性上的痛点。
Qwen3-TTS模型概览
本次开源的Qwen3-TTS系列包括5个模型,但也就2个参数规模,分为1.7B和0.6B两种参数规模。核心技术基于Qwen3-TTS-Tokenizer-12Hz多码本语音编码器,实现高效压缩和高保真语音重建。
这次开源的Qwen3-TTS又分为三个不同的版本,分别是VoiceDesign, CustomVoice 和 Base。其中VoiceDesign版本是基于用户描述进行语音设计,支持指令控制和流式生成。CustomVoice版本则是通过用户指令控制目标音色,支持9种优质音色(覆盖性别、年龄、语言和方言组合),支持指令控制和流式生成。而Base版本是基础模型,支持3秒快速语音克隆,可用于微调其他模型,支持流式生成。
Qwen3-TTS的核心特性
本次开源的Qwen3-TTS模型虽然参数规模不大,但是很有特色,总结一下3个方面,即语音设计、语音克隆和多语言支持。
Qwen3-TTS支持“语音设计”
首先,Qwen3-TTS 引入了强大的 Voice Design 功能。与传统 TTS 只能选择预设音色不同,Qwen3-TTS 允许用户通过自然语言描述来定制声音。也就是我们可以使用自然语言描述来生成自定义语音,例如音色、情感、韵律、年龄、性别甚至背景角色。比如说,我们可以指示模型生成“高亢的男性声音带着兴奋”或无缝融入方言和口音。具体来说,包括:
- 精细控制:你可以描述“一个沙哑的中年男性,语气急促且带有销售腔调”,或者“一个温柔的讲睡前故事的年轻女性”。
- 多维调节:支持对音色、说话风格、情感、语速甚至语调的精细化控制。
- 所想即所得:极大地降低了创造特定角色声音的门槛,非常适合游戏NPC配音、有声书制作等场景。
Qwen3-TTS支持3秒种的语音克隆
另一个亮点是语音克隆,只需3秒钟的音频样本即可准确复制说话者的声音。Qwen3-TTS在时延方面体验很好,在单个字符输入后即可交付第一个音频包,端到端延迟低至97ms,非常适合实时应用如直播或互动对话,其它核心特点包括:
- 仅需3秒:只需要提供一段 3秒钟 的参考音频,Qwen3-TTS 就能迅速“学会”这个人的声音特征。也就是说语料很少即可完成任务;
- 跨语言克隆:学会声音后,不仅能说原语言,还能用这个声音说出其他 10 种支持的语言(如用中文参考音频合成流利的英文、日文语音)。
- 高保真度:在相似度和自然度上,据官方测试数据,其表现优于目前的行业标杆 ElevenLabs 和 GPT-4o-mini-tts。
Qwen3-TTS多语言能力强悍
最后,Qwen3-TTS的多语言能力也很厉害,它支持10+ 主流语言:包括中文、英语、日语、韩语、德语、法语、西班牙语、意大利语、葡萄牙语、俄语等。
此外,也支持多个不同的方言,如粤语、四川话、东北话 等多种方言,能够精准捕捉方言的韵味和地道表达。
变体如Qwen3-TTS-Flash强调多音色和多方言支持,提供多达49种高质量声音和9种优质音色,涵盖各种性别、年龄和语言组合。 这包括对噪声输入的鲁棒性,能够处理特殊符号、拼音和罕见字符而不遗漏。
Qwen3-TTS的评测结果:
根据官方公布的技术报告,Qwen3-TTS 在语音克隆、语音设计及长音频稳定性等关键维度上均展现了很好的效果。在与 MiniMax、ElevenLabs、GPT-4o 等顶尖闭源模型的对比中,Qwen3-TTS证明了开源模型在复杂任务处理上的成熟度并不差。
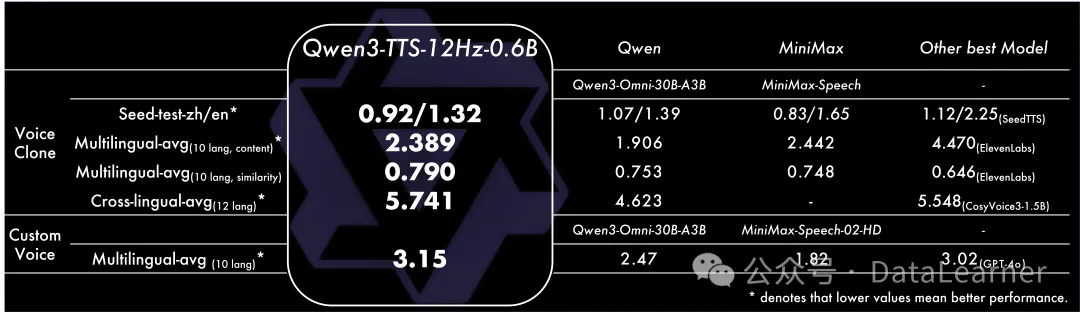

以下是本次官方公布的评测中几个最具代表性的关键数据供大家参考:
- 语音克隆(Voice Clone):在包含 10 种语言的 TTS 多语言测试集中,Qwen3-TTS 的表现大幅领先行业标杆。其平均词错误率(WER)低至 1.835%(对比 ElevenLabs 为 4.470%),说话人相似度高达 0.789(对比 ElevenLabs 为 0.646),也就说错词更少,更加自然。
- 跨语言克隆(Cross-lingual):在极具挑战的 12 种语言跨语言克隆任务上,Qwen3-TTS 实现了 4.418 的平均优异成绩(数值越低越好),显著优于此前的开源 SOTA 模型 CosyVoice3(5.548)和自家的全模态大模型Qwen3-Omni-30B-A3B。
- 语音设计(Voice Design):在 InstructTTS-Eval 基准测试中,模型对指令的理解与执行能力得分高达 84.1/81.8,在指令遵循和表现力上双双击败了闭源模型 MiniMax-Voice-Design(82.3/81.6)。
- 定制音色(Custom Voice):在单说话人多语言泛化测试中,Qwen3-TTS 的平均 WER 仅为 2.34,其综合表现优于 GPT-4o(3.02)和 Gemini-pro。
此外,模型在长音频生成的稳定性上也取得了突破。在连续生成 10分钟 语音的压力测试下,中文和英文的词错误率分别控制在 2.36% 和 2.81%,配合说话人相似度高达 0.95 的高保真 Tokenizer,确保了长篇有声书或演讲内容的连贯与自然。
Qwen3-TTS的技术架构
在底层,Qwen3-TTS采用通用端到端架构,结合离散多码本语言模型(LM),全面建模语音,避免了传统级联系统的缺陷。其中,阿里认为,他们自研的Qwen3-TTS-Tokenizer-12Hz多码本语音编码器可以在高效压缩音频信号的同时保留副语言细节和环境声学。轻量级非DiT(非扩散Transformer)架构处理高速重建,而双轨混合流式系统支持流式和非流式模式,提供灵活性。
Qwen3-TTS已经免费开源
Qwen3-TTS的全部5个模型均以Apache 2.0协议开源,意味着完全免费商用授权,最大的模型文件也就4.52 GB,有显卡的童鞋可以直接测试起来了。
五个模型的官方开源地址可以参考DataLearnerAI模型的大模型库:https://www.datalearner.com/ai-models/pretrained-models?q=qwen3-tts&page=1
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
