![网络爬虫中URLConnection的使用[以科学网为例]](https://www.datalearner.com/resources/blog_images/datalearner_blog_default_img.jpg)
Original Blog
Original AI Tech Blogs
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
Dirichlet Tree Distribution(狄利克雷树分布)
狄利克雷分布作为多项式分布的先验大家应该比较熟悉了。这里介绍另外一种Dirichlet树结构的分布,也可以作为多项式分布的先验,但却更加灵活
EM算法简介及其例子
EM(expectation-maximization)算法是统计学中求统计模型的最大似然和最大后验参数估计的一种迭代式算法,模型一般是依赖于不可观测的潜在变量。
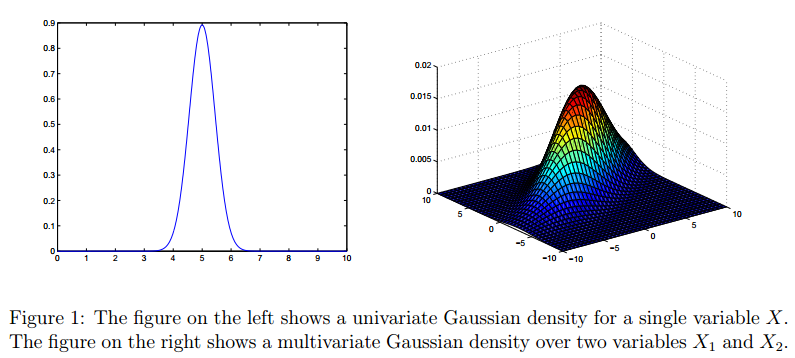
多元高斯分布(多元正态分布)简介
高斯分布是一种非常常见的分布,对于一元高斯分布我们比较熟悉,对于高斯分布的多元形式有很多人不太理解。这篇博客的材料主要来源Andrew Ng在斯坦福机器学习课的材料。
HMC(Hamiltonian Monte Carlo抽样算法详细介绍)
HMC(Hamiltonian Monte Carlo抽样算法详细介绍)
Author Topic Model[ATM理解及公式推导]
Author Topic Model[ATM理解及公式推导]

机器学习中MCMC方法介绍
有人把Metropolis算法当作是二十世纪最伟大的十大算法之一。这个算法是大规模抽样算法的一种,也叫做马尔可夫链蒙特卡洛(Markov chain Monte Carlo,MCMC)。对于很多高维问题来说,比如计算一个凸体的体积,MCMC仿真是目前唯一可以在合理时间内解决这个问题的一般性方法。本文介绍了三种主流的MCMC算法,即MH算法、模拟退火算法和吉布斯抽样方法

贝叶斯统计中的计算方法简介
仿真抽样是给予贝叶斯方法第二春的重要角色。由于很多时候实际问题很复杂,我们无法精确求出后验密度,使用仿真抽样的方法我们可以获得近似的结果。这篇博客主要介绍了几种仿真抽样的方法。
Scrapy网络爬虫实战[保存为Json文件及存储到mysql数据库]
Scrapy网络爬虫实战[保存为Json文件及存储到mysql数据库]