Anthropic发布Claude Opus 4.8:定价不变,编程与智能体能力小幅提升
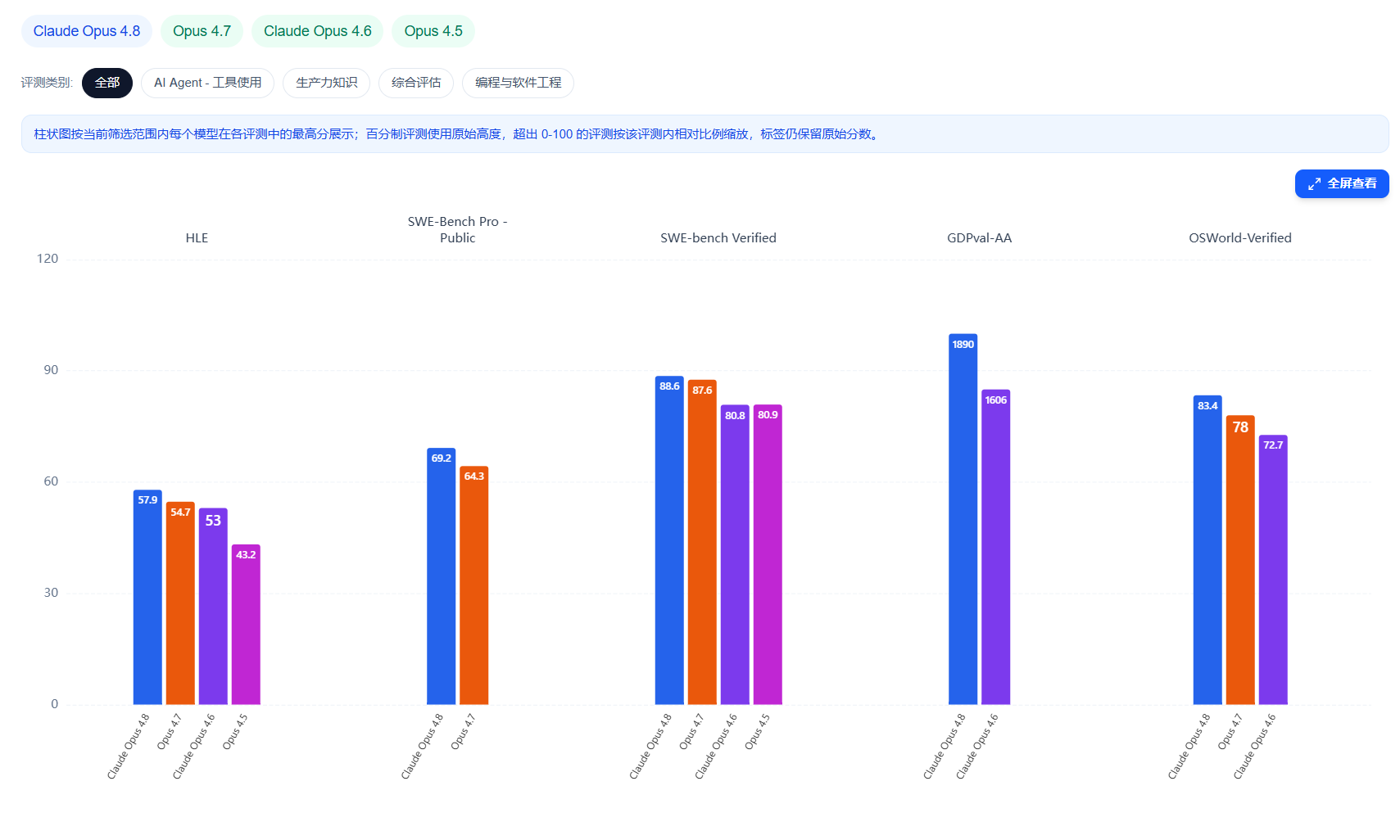
2026年5月28日,Anthropic发布了旗舰模型的新版本Claude Opus 4.8。这是一次幅度不大但方向明确的迭代:模型在编程、智能体(agentic)任务、推理和知识工作类基准上全面小幅领先于前代Opus 4.7,定价保持不变,同时把”诚实性”作为本次最被强调的改进点。Anthropic官方在公告中也未回避,直接将其定性为”对前代一次温和但切实的改进(a modest but tangible improvement)”。