
断层领先!Google发布图像生成和编辑大模型Gemini 2.5 Flash Image Preview,火爆网络的Nano Banana背后真正的模型发布!
就在刚才,Google宣布发布最新的图像生成和编辑大模型Gemini 2.5 Flash Image Preview。该模型就是最近火爆网络的Nana Banana背后真正的模型。该模型在图片生成和编辑方面目前是断层领先,效果非常好。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
就在刚才,Google宣布发布最新的图像生成和编辑大模型Gemini 2.5 Flash Image Preview。该模型就是最近火爆网络的Nana Banana背后真正的模型。该模型在图片生成和编辑方面目前是断层领先,效果非常好。

智谱AI于2025年7月发布了Zread。这款产品能够利用其大模型能力,结合类似Deep Research的Agent技术,对GitHub项目进行深度解读和问答。其价值在于将强大的模型能力通过优秀的工程化设计,变成了一个真正“好用”的工具。它解决的正是那种“代码就在那里,但我就是看不懂”的尴尬,这种体验是单纯聊天机器人无法替代的。
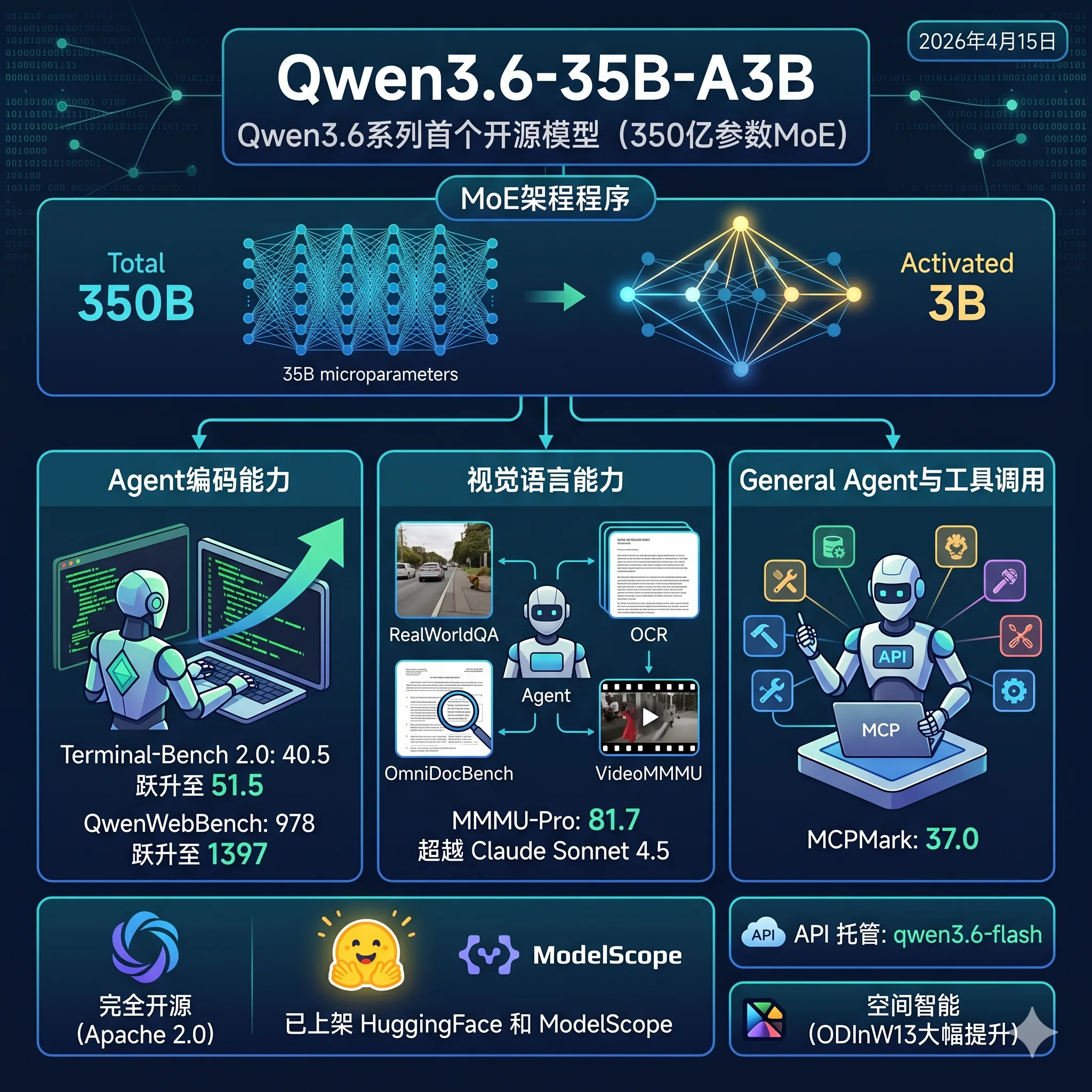
阿里开源Qwen3.6-35B-A3B,350亿总参数仅激活30亿,Terminal-Bench 2.0得分51.5,SWE-bench Verified 73.4,视觉多项超越Claude Sonnet 4.5,Apache 2.0开源。
EmbeddingGemma 是基于 Gemma 3 架构打造的全新开源多语言向量模型,专为移动端/本地离线应用而生。它以约 308M 参数的紧凑体量,在 RAG、语义搜索、分类、聚类等任务上提供高质量表征,同时将隐私与可用性拉满:无需联网即可在本地生成向量。

几个小时前,DeepSeek 突然发布了两款全新的推理模型:DeepSeek V3.2 正式版与DeepSeek V3.2-Speciale。前者已经全面替换官方网页、App 与 API 成为新的默认模型;后者则以“临时研究 API”的方式开放,被定位为极限推理版本。

昨天,Anthropic公布了一项引人注目的实验——Project Vend。他们让旗下的大模型Claude Sonnet 3.7在一个真实的办公环境中,自主经营一家小型自动化商店,为期约一个月。这个实验的目标是探索,在不久的将来,AI模型在真实经济体中自主运行任务的可行性、潜在的成功模式以及那些出人意料的失败方式。实验结果非常强大,也充满了令人深思的细节!

就在刚刚,马斯克在推特上宣布本周会开源Grok大语言模型。xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。

在人工智能领域,Mistral与NVIDIA的合作带来了一个引人注目的新型大模型——Mistral NeMo。这个拥有120亿参数的模型不仅性能卓越,还为AI的普及和应用创新铺平了道路。MistralAI官方博客介绍说该模型是此前开源的Mistral 7B模型的继承者,因此未来可能7B不会再继续演进了!

就在刚才,Anthropic 正式推出了 Claude Sonnet 4.5——全球最强的编码模型。这款新模型不仅在软件开发能力上实现了断层领先,更在构建复杂 AI 代理、计算机操控以及数学推理等多个维度展现出革命性突破。

Tool Decathlon(简称 Toolathlon)是一个针对语言代理的基准测试框架,用于评估大模型在真实环境中使用工具执行复杂任务的能力。该基准涵盖32个软件应用和604个工具,包括日常工具如 Google Calendar 和 Notion,以及专业工具如 WooCommerce、Kubernetes 和 BigQuery。它包含108个任务,每个任务平均需要约20次工具交互。该框架于2025年10月发布,旨在填补现有评测在工具多样性和长序列执行方面的空白。通过执行式评估,该基准提供可靠的性能指
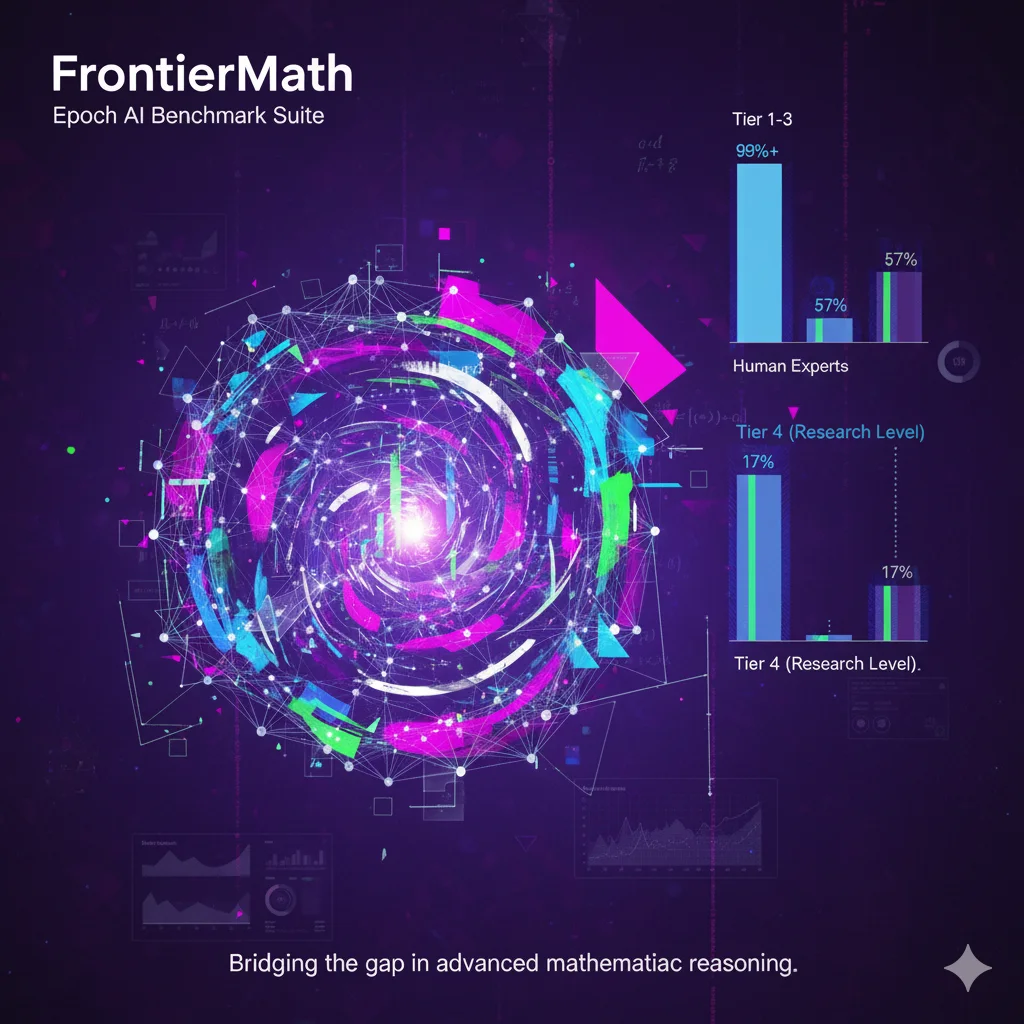
FrontierMath是一个由Epoch AI开发的基准测试套件,包含数百个原创的数学问题。这些问题由专家数学家设计和审核,覆盖现代数学的主要分支,如数论、实分析、代数几何和范畴论。每个问题通常需要相关领域研究人员投入数小时至数天的努力来解决。基准采用未发表的问题和自动化验证机制,以减少数据污染风险并确保评估可靠性。当前最先进的AI模型在该基准上的解决率低于2%,这反映出AI在处理专家级数学推理时的局限性。该基准旨在为AI系统向研究级数学能力进步提供量化指标。

MistralAI开源的混合专家模型Mistral-7B×8-MoE在本周吸引了大量的关注。这个模型不仅是稍有的基于混合专家技术开源的大模型,而且有较高的性能、较低的推理成本、支持法语、德语等特性。昨天MistralAI发布的不仅仅是这个混合专家模型,还有他们的平台服务La plateforme。在这里他们透露了MistralAI还有更加强大的模型。
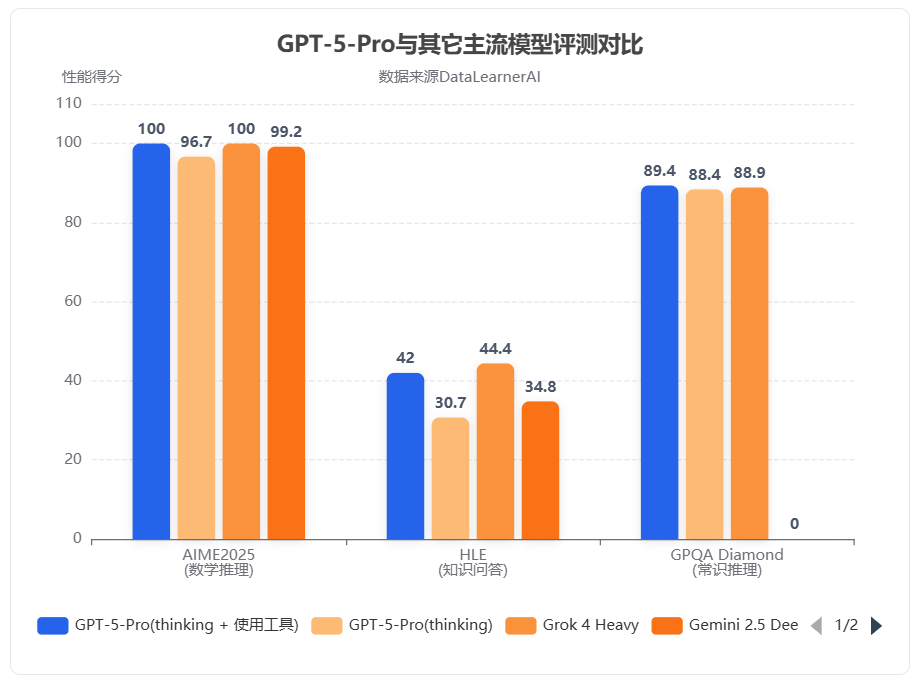
几个小时前,OpenAI发布了全新一代大模型GPT-5系列。本次发布的是一个全新的AI系统,而非一个单独的模型系列。GPT-5背后包含了5个不同的模型系列或者版本,分别是GPT-5-Pro、GPT-5、GPT-5-mini、GPT-5-nano和GPT-5-Chat。
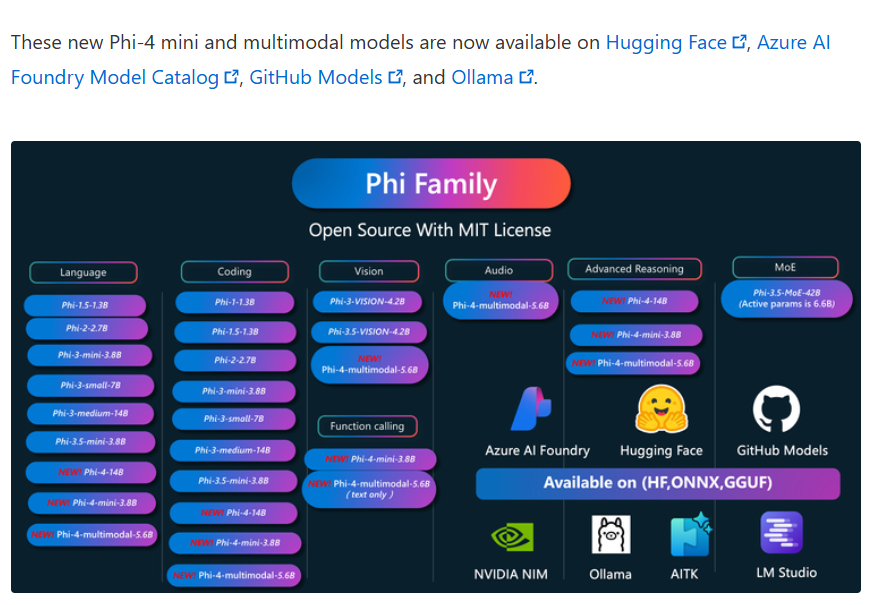
2025年2月27日,微软正式发布了其全新系列的大型语言模型——Phi-4系列。这一系列包含了三个创新性的模型:Phi-4-Mini、Phi-4-Multimodal和一款经过推理优化的Phi-4-Mini。此次发布的模型不仅在性能上展现出色,更在多模态能力与推理任务中实现了显著突破。其中,Phi-4-Multimodal是一个仅仅包含56亿参数规模的多模态大模型,但是支持文本、语音、图片的输入,十分强大。

万众瞩目的GPT-4即将来临!3月9日晚上在德国举办的一个AI会议。微软德国的员工参与了讨论,在介绍微软云的AI能力的时候,微软德国CTO Andreas Braun透露了GPT-4将在下周发布。
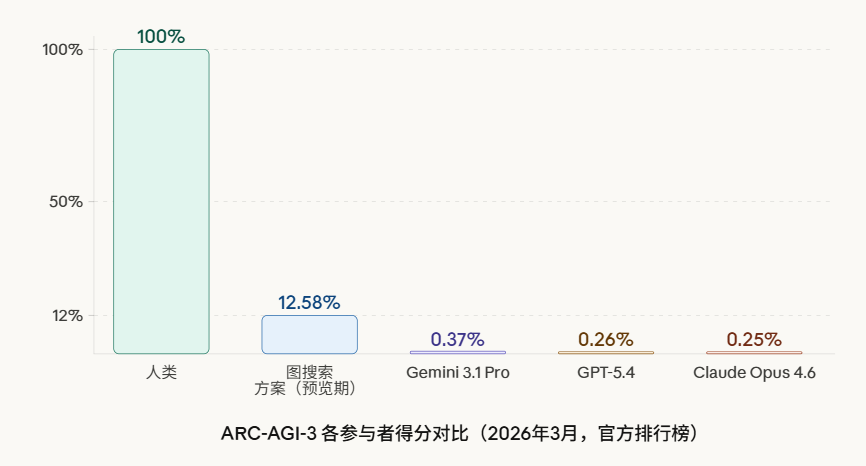
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。
AIME 2026 是基于美国数学邀请赛(American Invitational Mathematics Examination)2026 年问题的评测基准,用于评估大语言模型在高中水平数学推理方面的表现。该基准包含 15 个问题,覆盖代数、几何、数论和组合数学等领域。模型通过生成答案并与标准答案比较来计算准确率。
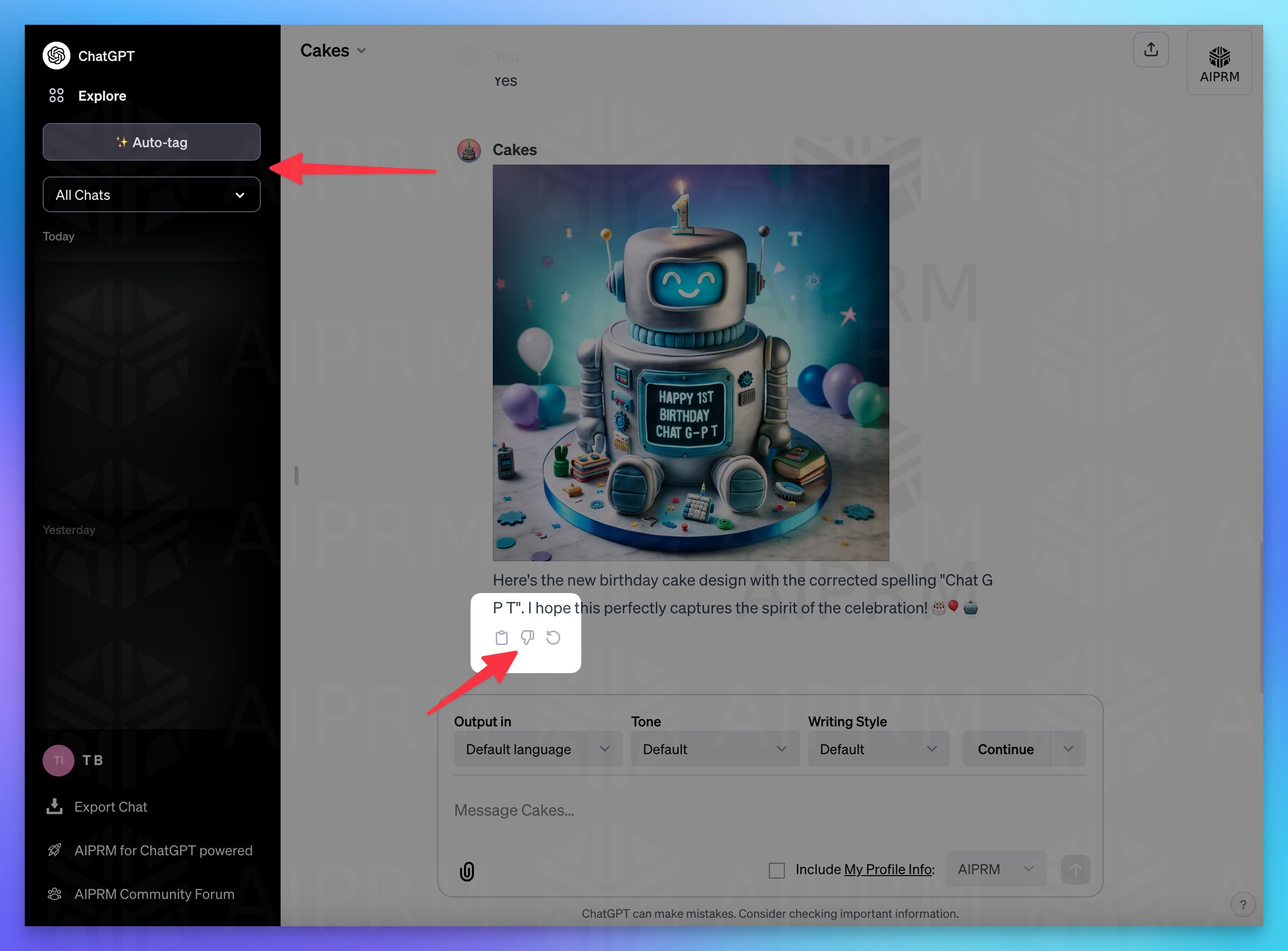
在OpenAI的首次开发者大会上,OpenAI发布了诸多的新功能。但是,ChatGPT目前一个非常难用的功能就是历史记录查询。当前,ChatGPT的历史对话是ChatGPT自动取名标题之后放在左侧,而新截图显示,ChatGPT可能即将上线一个新功能来改进这个管理。

网络流传了一张疑似GPT-4.5的定价截图,引爆了很多人的讨论。但是,目前没有人可以确定真假。
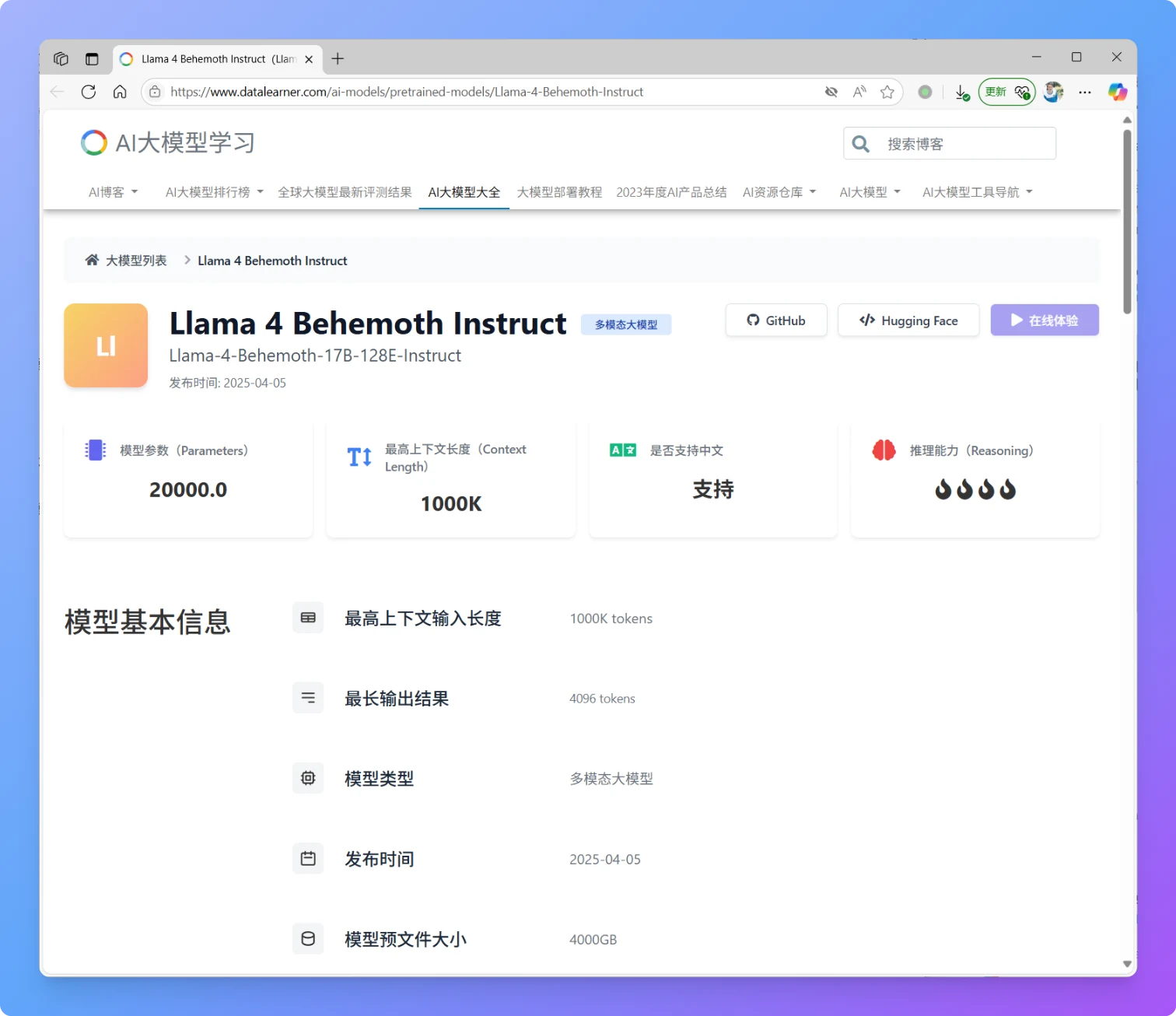
就在刚刚,MetaAI发布了全新一代Llama4大模型,Llama正式进入多模态和MoE架构时代。本次新发布的是Llama4中的2个模型分别是Llama4 Scout和Llama4 Maverick。这两个模型都是170亿激活参数,但是前者共16个专家,后者有128个专家,因此总的参数量分别达到了1090亿和4000亿!不过根据评测的情况看,即使是4000亿规模170亿激活的模型,也和DeepSeek V3.1(即DeepSeek V3 0324)版本差不多。

OpenAI 于 2025 年 2 月 27 日发布了 GPT-4.5,作为其语言模型系列的最新版本。尽管具体的技术细节因商业保密而未完全公开,基于现有信息和合理推测,DataLearner提供更具体的数据和分析,同时补充更多来自用户的评价。
就在今日,Moonshot AI 正式推出 Kimi K2 Thinking,这款开源思考代理模型以其革命性的工具集成和长程推理能力,瞬间点燃了开发者社区的热情。Kimi K2能自主执行200-300次连续工具调用,跨越数百步推理,解决PhD级数学难题或实时网络谜题。本次发布的Kimi K2不仅仅是模型升级,更是AI Agent能力的扩展。

xAI 正式发布 Grok 4 Fast —— 一款以 极致性价比与前沿性能 为核心卖点的新一代推理模型。相比前代产品,它不仅在推理准确率上几乎与旗舰模型Grok 4等持平,还凭借 40%更高的推理效率 和 高达98%的成本降低,将高质量智能推理真正带入大众用户和企业应用场景。

Anthropic正式发布最新一代入门级模型Claude Haiku 4.5。相较上一代小模型,Haiku 4.5 在编码、推理与“计算机使用/子代理编排”等关键生产力场景上实现逼近甚至局部追平 Sonnet 4,但价格更低、速度更快,定位于“面向规模化落地的高性价比主力”。